








AI芯片主要承担推断任务,通过将终端设备上的传感器(麦克风阵列、摄像头等)收集的数据代入训练好的模型推理得出推断结果。由于终端场景多种多样各不相同,对于算力和能耗等性能需求也有大有小,应用于终端芯片需要针对特殊场景进行针对性设计以实现最优解方案,最终实现有时间关联度的三维处理能力,这将实现更深层次的产业链升级,是设计、制造、封测和设备材料,以及软件环境的全产业链协同升级过程。
相比于传统CPU服务器,在提供相同算力情况下,GPU服务器在成本、空间占用和能耗分别为传统方案的1/8、1/15和1/8。 人工智能服务器是AI算力基础设施的主要角色,在服务器中渗透率不断提升。 L3自动驾驶算力需求为30-60TOPS,L4需求100TOPS以上,L5需求甚至达1,000TOPS,GPU算力需求提升明显,芯片主要向着大算力、低功耗和高制程三个方向发展。
本期的智能内参,我们推荐华西证券的报告《AI领强算力时代,GPU启新场景落地》,解读GPU三大落地场景和国产GPU最新的发展趋势。
来源 华西证券
原标题:
《AI领强算力时代,GPU启新场景落地》
作者:孙远峰 等
一、算力时代,GPU开拓新场景
广义上讲只要能够运行人工智能算法的芯片都叫作 AI 芯片。但是通常意义上的 AI 芯片指的是针对人工智能算法做了特殊加速设计的芯片。
AI芯片也被称为AI加速器或计算卡,即专门用于处理人工智能应用中的大量计算任务的模块(其他非计算任务仍由CPU负责)。到目前位置,AI芯片算力发展走过了三个阶段:
第一阶段: 因为芯片算力不足,所以神经网络没有受到重视;
第二阶段:通用芯片CPU的算力大幅提升,但仍然无法 满足神经网络的需求;
第三阶段: GPU和和新架构的AI芯片推进人工智能落地。
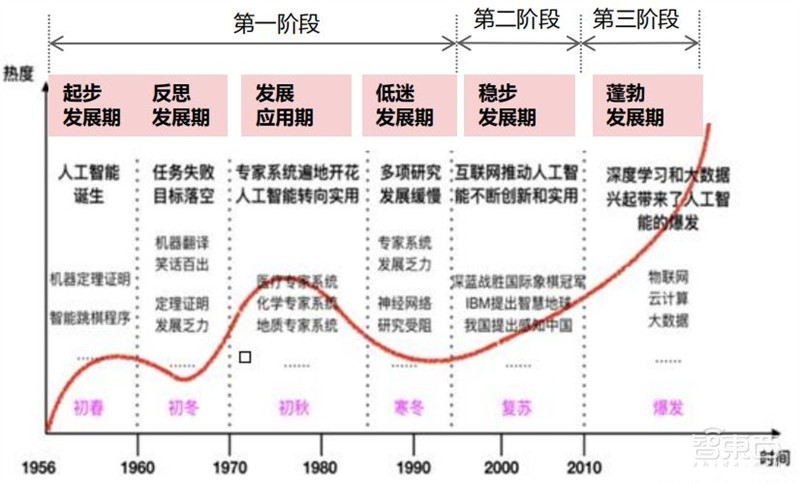
▲AI芯片算力发展阶段
目前,GPT-3模型已入选了《麻省理工科技评论》2021年“十大突破性技术。 GPT-3的模型使用的最大数据集在处理前容量达到了45TB。根据 OpenAI的算力统计单位petaflops/s-days,训练AlphaGoZero需要1800-2000pfs-day,而GPT-3用了3640pfs-day。
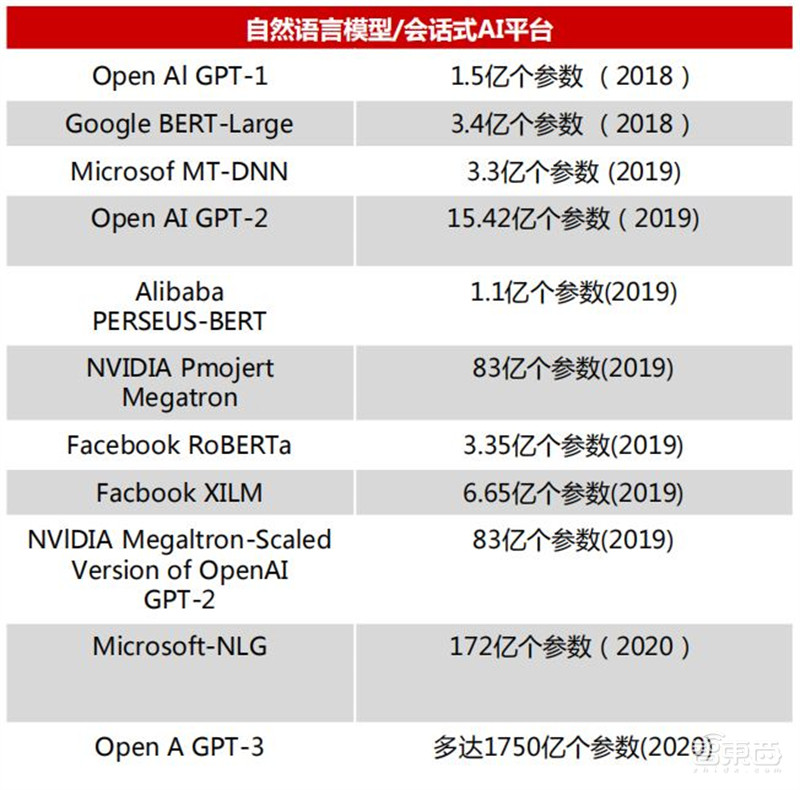
▲自然语言模型/会话式AI平台
AI运算指以“深度学习” 为代表的神经网络算法,需要系统能够高效处理大量非结构化数据(文本、视频、图像、语音等) 。需要硬件具有高效的线性代数运算能力,计算任务具有:单位计算任务简单,逻辑控制难度要求低,但并行运算量大、参数多的特点。对于芯片的多核并行运算、片上存储、带宽、低延时的访存等提出了较高的需求。
自2012年以来,人工智能训练任务所需求的算力每 3.43 个月就会翻倍,大大超越了芯片产业长期存在的摩尔定律(每 18个月芯片的性能翻一倍)。针对不同应用场景,AI芯片还应满足:对主流AI算法框架兼容、可编程、可拓展、低功耗、体积及价格等需求。
从技术架构来看,AI芯片主要分为图形处理器(GPU)、现场可编程门阵列(FPGA)、专用集成电路(ASIC)、类脑芯片四大类。其中,GPU是较为成熟的通用型人工智能芯片,FPGA和ASIC则是针对人工智能需求特征的半定制和全定制芯片,类脑芯片颠覆传统冯诺依曼架构,是一种模拟人脑神经元结构的芯片,类脑芯片的发展尚处于起步阶段。
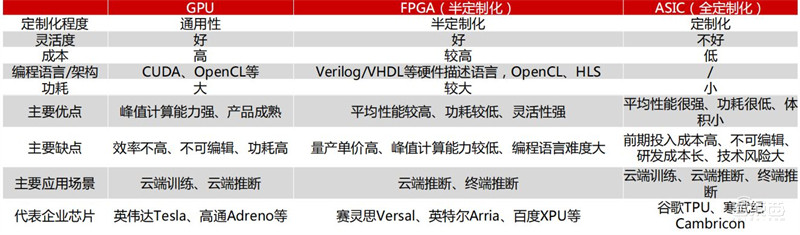
▲三种技术架构AI芯片类型比较
2019年全球人工智能芯片市场规模为110亿美元。随着人工智能技术日趋成熟,数字化基础设施不断完善,人工智能商业化应用将加落地,推动AI芯片市场高速增长,预计2025年全球人工智能芯片市场规模将达到726亿美元。
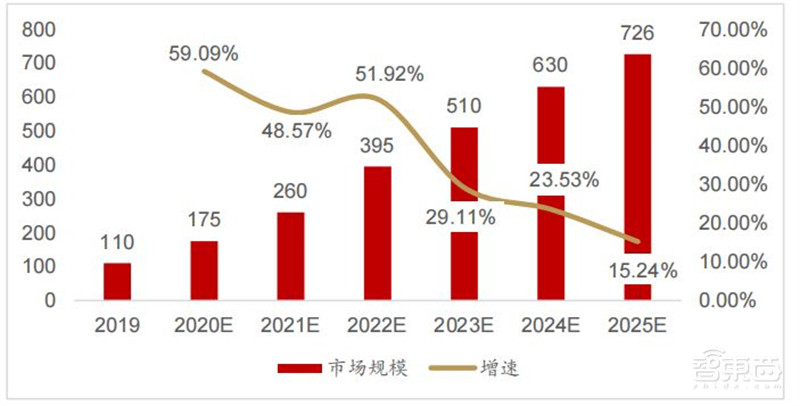
▲2019-2025年全球人工智能芯片市场规模及预测(亿美元)
二、GPU 下游三大应用市场
GPU其实是由硬件实现的一组图形函数的集合,这些函数主要用于绘制各种图形所需要的运算。这些和像素,光影处理,3D坐标变换等相关的运算由GPU硬件加速来实现。图形运算的特点是大量同类型数据的密集运算——如图形数据的矩阵运算,GPU的微架构就是面向适合于矩阵类型的数值计算而设计的,大量重复设计的计算单元,这类计算可以分成众多独立的数值计算——大量数值运算的线程,而且数据之间没有像程序执行的那种逻辑关联性。
GPU微架构的设计研发是非常重要的,先进优秀的微架构对GPU实际性能的提升是至关重要的。目前市面上有非常丰富GPU微架构,比如Pascal、Volta、Turing(图灵)、Ampere(安培),分别发布于 2016 年、2017 年、2018 年和2020年,代表着英伟达 GPU 的最高工艺水平。
GPU的API(Application Programming Interface)应用程序接口发挥着连接应用程序和显卡驱动的桥梁作用。目前GPU API可以分为2大阵营和若干其他类。 2大阵营分别是微软的DirectX标准和KhronosGroup标准,其他类包括苹果的Metal API、 AMD的Mantle(地幔) API、英特尔的One API等。
AI芯片(GPU/FPGA/ASIC)在云端同时承担人工智能 “训练”和“推断”过程,在终端主要承担“推断”过 程,从性能与成本来看ASIC最优。ASIC作为专用芯片,算力与功耗在通用芯片GPU具有绝对优势,但开发周期较长,落地较慢,需一定规模后才能体现成本优势。FPGA可以看做从GPU到ASIC重点过渡方案。相对于GPU可深入到硬件级优化,相比ASIC在算法不断迭代演进情况下更具灵活性,且开发时间更短。
从生态与落地来看,GPU占据绝对优势,英伟达处垄断地 位。开发者能通过英伟达CUDA平台使用软件语言很方便地开发英伟达GPU实现运算加速,已被广泛认可和普及,积累了良好的编程环境。以TPU为代表的ASIC目前主要运用在巨头的闭环生态,FPGA在数据中心业务中发展较快。
2020年GPU市场规模为254.1亿美元,预计到2027年将达到1853.1亿美元,从2021年到2027年的复合年增长率为32.82%。GPU市场分为独立,集成和混合市场。2019年集成占据了GPU市场份额的主导地位,但由于混合处理器同时具有集成和独立GPU的能力,因此未来混合细分市场预计将实现最高复合年增长率。
市场分为计算机,平板电脑,智能手机,游戏机,电视等。在2019年,智能手机市场占据了全球GPU市场份额的主导地位,预计在预测期内将继续保持这一趋势。但是,由于对医疗设备等其他设备中对小型GPU的需求不断增长,预计其他领域在未来的复合年增长率最高。由于在设计和工程应用中图形处理器的广泛使用,预计汽车应用细分市场将在预测期内以最高的复合年增长率增长。
总体来说,GPU有三大应用场景:游戏 、 AI和自动驾驶
1、游戏
IDC数据显示,2020年游戏PC和显示器的出货量同比增长26.8%,达到5500万台。游戏笔记本电脑在2020年增长了创纪录的26.9%。与PC并行,游戏显示器在2020年也达到了新的高度,与2019年相比增长了77%以上,出货量达到了1430万台。
IDC预计2021年游戏显示器的销量将首次超过游戏台式机。即使游戏台式机逐渐受到青睐,游戏笔记本电脑的显示器连接率不断提高也意味着游戏监控器市场的五年复合年增长率预计将超过10%。IDC预计2025年全球销量达到7290万,复合年增长率为5.8%。
2、AI
移动端AI芯片市场不止于智能手机,潜在市场还包括:智能手环/手表、 VR/AR眼镜等市场。
在边缘计算场景,AI芯片主要承担推断任务,通过将终端设备上的传感器(麦克风阵列、摄像头等)收集的数据代入训练好的模型推理得出推断结果。由于边缘侧场景多种多样、各不相同,对于计算硬件的考量也不尽相同,对于算力和能耗等性能需求也有大有小。因此应用于边缘侧的计算芯片需要针对特殊场景进行针对性设计以实现最优的解决方案。
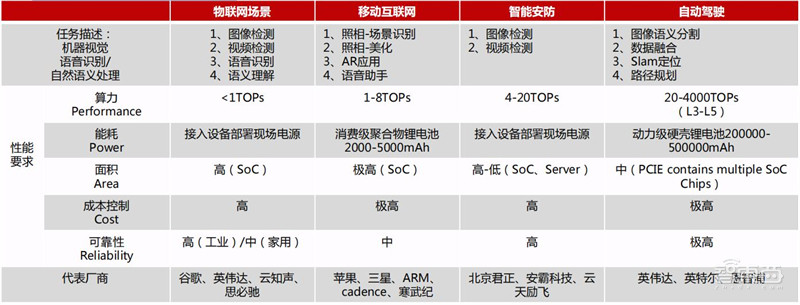
▲不同边缘计算场景对AI芯片性能要求
安防摄像头发展经历了由模拟向数字化、数字化高清到现在的数字化智能方向的发展,最新的智能摄像头除了实现简单的录、 存功能外,还可以实现结构化图像数据分析。安防摄像头一天可产生20GB数据,若将全部数据回传到云数据中心将会对网络带宽和数据中心资源造成极大占用。
通过在摄像头终端、网络边缘侧加装AI芯片,实现对摄像头数据的本地化实时处理,经过结构化处理、关键信息提取,仅将带有关键信息的数据回传后方,将会大大降低网络传输带宽压力。当前主流解决方案分为:前端摄像头设备内集成AI芯片和在边缘侧采取智能服务器级产品。 前端芯片在设计上需要平衡面积、功耗、成本、可靠性等问题,最好采取低功耗、低成本解决方案(如:DSP、 ASIC);边缘侧限制更少,可以采取能够进行更大规模数据处理任务的服务器级产品(如:GPU、 ASIC)。

▲AI芯片在智能安防摄像头中的应用
人工智能服务器通常搭载GPU、FPGA、ASIC等加速芯片,利用CPU与加速芯片的组合可以满足高吞吐量互联的需求,为自然语言处理、计算机视觉、语音交互等人工智能应用场景提供强大的算力支持,已经成为人工智能发展的重要支撑力量相比于传统CPU服务器,在提供相同算力情况下,GPU服务器在成本、空间占用和能耗分别为传统方案的1/8、1/15和1/8。
当前在云端场景下被最广泛应用的AI芯片是英伟达的GPU,主要原因是:强大的并行计算能力(相比CPU)、通用性以及成熟的开发环境。2020年全球AI服务器市场规模为122亿美元,预计到2025年全球AI智能服务器市场将达到288亿美元,5年CAGR达到18.8%。
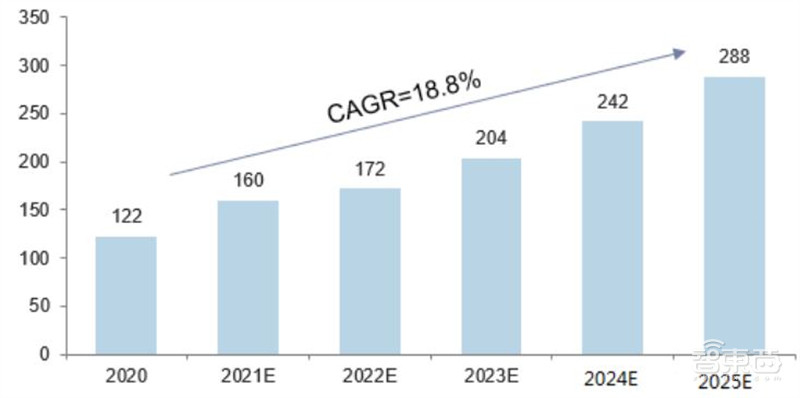
▲2020-2025年全球AI服务器行业市场规模及增速(单位:亿美元)
在AI开发中,由于深度学习模型开发及部署需要强大算力支持,需要专用的芯片及服务器支持。开发者如选择自购AI服务器成本过高。通过云服务模式,采取按需租用超算中心计算资源可极大降低项目期初资本投入同时也省却了项目开发期间的硬件运维费用,实现资本配置效率的最大化提升。
3、自动驾驶
全球自动驾驶迈入商用阶段,未来可期。IDC最新发布的《全球自动驾驶汽车预测报告(2020-2024)》数据显示,2024年全球L1-L5级自动驾驶汽车出货量预计将达到约5425万辆,2020至2024年的年均复合增长率(CAGR)达到18.3%;L1和L2级自动驾驶在2024年的市场份额预计分别为64.4%和34.0%。尽管目前L3-L5级自动驾驶技术的应用具有开拓性意义,L1-L2级自动驾驶将依然是未来5年内带动全球自动驾驶汽车出货量增长的最大细分市场。
我国汽车市场规模不断增长,自动驾驶由L2向L3过渡。中汽协数据显示,2021年1-3月,中国品牌乘用车共销售210.8万辆,同比增长81.5%,占乘用车销售总量的41.5%,占有率比上年同期提升1.4个百分点。2020年1月份至9月份,L2级智能网联乘用车销售量达196万辆,占乘用车总销量的14.7%。
更有部分企业加速研发L3级自动驾驶车型,多地开展自动泊车、自动驾驶公交车、无人智能重卡等方面的示范应用。到2025年,我国PA(部分自动驾驶)、CA(有条件自动驾驶)级智能网联汽车销量占当年汽车总销量比例超过50%,C-V2X(以蜂窝通信为基础的移动车联网)终端新车装配率达50%。
随着传感器、车载处理器等产品的进一步完善,将会有更多L3级车型出现。而L4、L5级自动驾驶预计将会率先在封闭园区中的商用车平台上实现应用落地,更广泛的乘用车平台高级别自动驾驶,需要伴随着技术、政策、基础设施建设的进一步完善,预计至少在2025年~2030年以后才会出现在一般道路上。
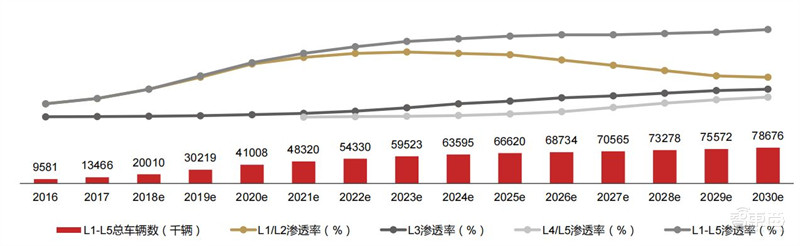
▲2016-2030年全球汽车市场自动驾驶渗透率预测
感知路境,短时处理海量数据。行车过程中依赖雷达等传感器对道理信息进行采集后,处理器每秒需实时数据解析几G量级数据,每秒可以产生超过 1G 的数据。对处理器的计算量要求较高。
自动规划,瞬时反应保障安全。处理分析实时数据后,需要在毫秒的时间精度下对行车路径、车速进行规划,保障行车过程安全,对处理器的计算速度要求较高。
兼具技术成本优势,GPU为自动驾驶领域主流。
三、国产AI GPU走上快车道
2020年国内AI芯片行业投融资金额同比增长了52.8%,2021年1月至4月的投融资事件和金额均已超过去年全年,资本对国内半导体、集成电路领域投资高涨。
从热门领域来看,人工智能领域是2020年资本青睐度较高的细分赛道之一。2020年资本投资的主要是相对成熟且已获得1-2轮甚至2轮以上融资的AI芯片企业。
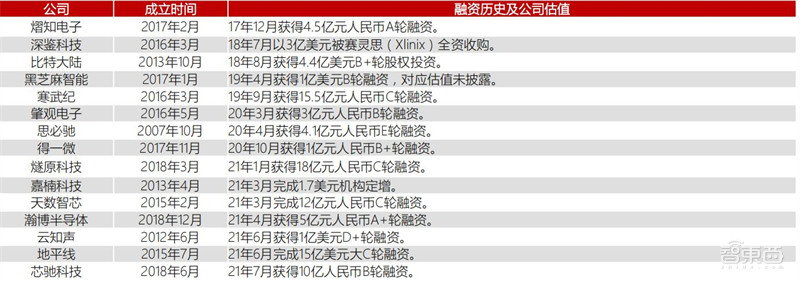
▲AI芯片行业公司成立时间、融资历史及估值
AI芯片行业市场预期逐渐趋于理性,创业进入市场检验期。大量AI芯片公司在15~17年成立。未来1-2年,市场将会对各厂商的产品和技术进行实际检验。市场期待更高算力、更低功耗、成本更低的AI芯片。
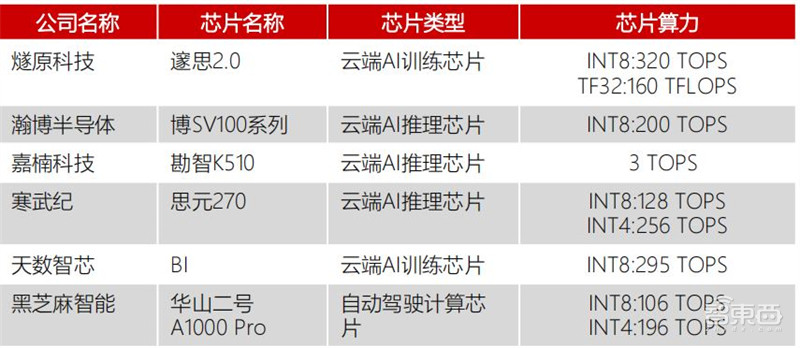
▲不同公司的芯片介绍
1、沐曦集成电路:多场景高性能GPU
沐曦集成电路专注于设计具有完全自主知识产权,针对异构计算等各类应用的高性能通用GPU芯片。公司致力于打造国内最强商用GPU芯片,产品主要应用方向包含传统GPU及移动应用,人工智能、云计算、数据中心等高性能异构计算领域,是今后面向社会各个方面通用信息产业提升算力水平的重要基础产品。
拟采用业界最先进的5nm工艺技术,专注研发全兼容CUDA及ROCm生态的国产高性能GPU芯片,满足HPC、数据中心及AI等方面的计算需求。致力于研发生产拥有自主知识产权的、安全可靠的高性能GPU芯片,服务数据中心、云游戏、人工智能等需要高算力的诸多重要领域。
2、壁仞科技:推出云端AI芯片
壁仞科技创立于2019年,公司在GPU和DSA(专用加速器)等领域具备丰富的技术储备聚焦于云端通用智能计算,逐步在AI训练和推理、图形渲染、高性能通用计算等多个领域赶超现有解决方案,以实现国产高端通用智能计算芯片的突破。

▲壁仞科技发展历程
3、燧原科技:推中国最大AI计算芯片
在2021世界人工智能大会期间,上海燧原科技推出第二代云端AI训练芯片邃思2.0及训练产品云燧T20/T21,以及全新升级的驭算Topsrider 2.0软件平台。
邃思2.0是迄今中国最大的AI计算芯片,采用日月光2.5D封装的极限,在国内率先支持TF32精度,单精度张量TF32算力可达160TFLOPS。同时,邃思2.0也是首个支持最先进内存HBM2E的产品。公司主要服务为面向消费电子、汽车电子、计算机及周边、工业、数据处理、物联网等广泛应用市场所提供的一站式芯片定制服务和半导体IP 授权服务。
燧原科技成立于2018年03月19日,成立至今连续获得过5轮融资,累计融资额近32亿元人民币。其最新一笔融资为今年1月完成的18亿元C轮融资,由中信产业基金、中金资本旗下基金、春华资本领投。
4、地平线:智能驾驶及 AI 应用领域服务
基于创新的人工智能专用计算架构 BPU,地平线已成功流片量产了中国首款边缘人工智能芯片——专注于智能驾驶的征程1 和专注于 AIoT 的旭日1 ;2019 年,地平线又推出了中国首款车规级 AI 芯片征程 2 和新一代AIoT智能应用加速引擎旭日2 ;2020年,地平线进一步加速AI芯片迭代,推出新一代高效能汽车智能芯片征程 3 和全新一代 AIoT 边缘 AI 芯片平台旭日 3。
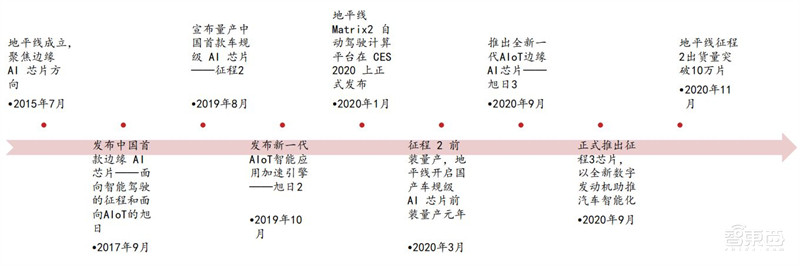
▲地平线发展历程
智能物联网需求将使云端计算的负荷成倍增长。智能物联网是未来的趋势所向,海量的碎片化场景与计算旭日处理器强大的边缘计算能力,帮助设备高效处理本地数据。
面向AIoT,地平线推出旭日系列边缘 AI 芯片。旭日2采用 BPU 伯努利1.0 架构,可提供 4TOPS 等效算力,旭日3 采用伯努利2.0 ,可提供 5TOPS 的等效算力。
地平线已成为唯一覆盖 L2 到 L4 的全场景整车智能芯片方案提供商。从 2019 年量产中国首款车规级 AI 芯片征程 2,到 2020 年推出第二代车规级芯片征程3。目前,征程 2 、征程 3 已在长安、长城、东风岚图、广汽、江淮、理想、奇瑞、上汽等多家自主品牌车企的多款主力爆款车型上实现前装量产。
地平线 Matrix由征程2 架构加速的车规级计算平台,结合深度学习感知技术,为高级别自动驾驶提供了稳定可靠的高性能感知系统。
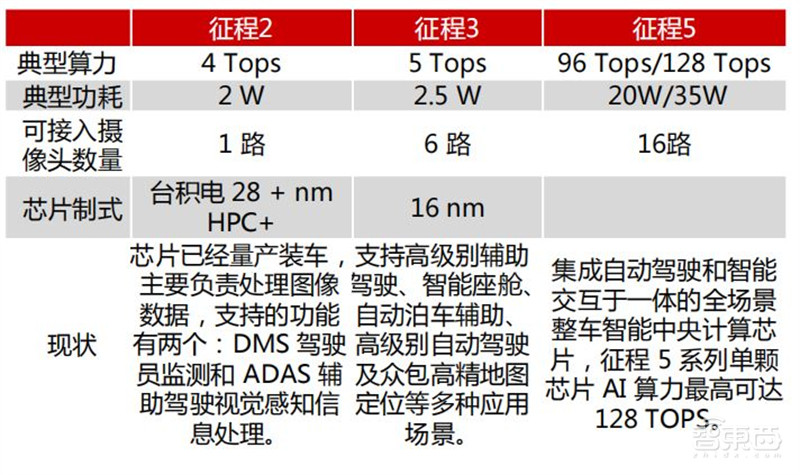
▲地平线征程系列芯片
5、黑芝麻: 智能驾驶系统解决方案
黑芝麻智能科技是一家专注于视觉感知技术与自主IP芯片开发的企业。公司主攻领域为嵌入式图像和计算机视觉,提供基于光控技术、图像处理、计算图像以及人工智能的嵌入式视觉感知芯片计算平台,为ADAS及自动驾驶提供完整的商业落地方案。
基于华山二号 A1000 芯片,黑芝麻提供了四种智能驾驶解决方案。单颗 A1000L 芯片适用于 ADAS 辅助驾驶;单颗 A1000 芯片适用于 L2+ 自动驾驶;双 A1000 芯片互联可达 140TOPS 算力,支持 L3 等级自动驾驶;四颗 A1000 芯片则可以支持 L4 甚至以上的自动驾驶需求。另外,黑芝麻还可以根据不同的客户需求,提供定制化服务。
黑芝麻智能首款芯片与上汽的合作已实现量产,第二款芯片A1000正在量产过程中,预计今年下半年在商用车领域实现10万片量级以上的量产,明年将在乘用车领域量产落地。黑芝麻智能已与一汽、蔚来、上汽、比亚迪、博世、滴滴、中科创达、亚太机电等企业在L2、L3级自动驾驶感知系统解决方案上均有合作。
黑芝麻智能科技最新的华山二号(A1000)芯片具备 40-70TOPS 的强大算力、小于 8W 的功耗及优越的算力利用率,工艺制程16nm,符合 AEC Q-100、单芯片 ASIL B、系统 ASIL D 汽车功能安全要求,是目前能支持 L3 及以上级别自动驾驶的唯一国产芯片。为了应对不同的市场需求,黑芝麻同步发布了华山二号 A1000L。
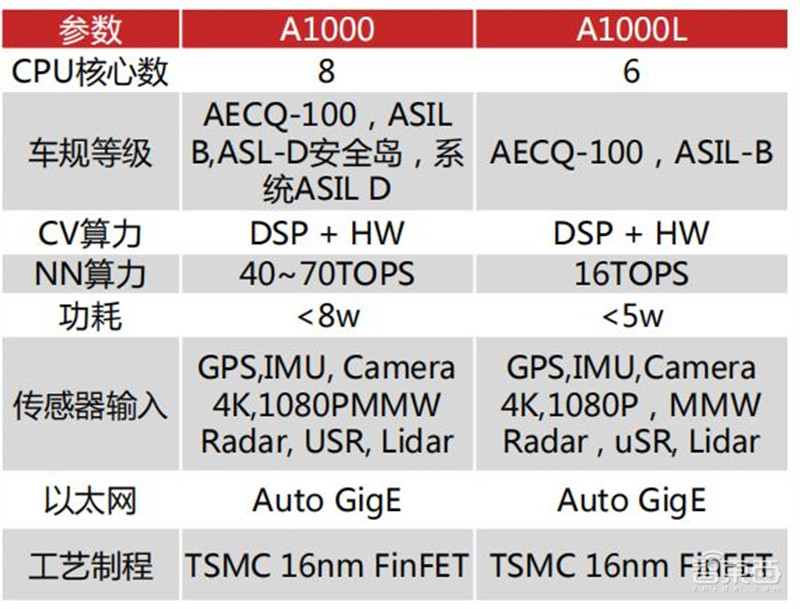
▲黑芝麻最新产品A1000系列参数对比
除了以上玩家,摩尔线程等公司最近也有新进展,见下表。

▲国产GPU最新进展
智东西认为,在传统GPU市场中,排名前三的Nvidia、AMD、Intel的营收几乎可以代表整个GPU行业的收入。国产CPU经过多年的探索和发展,已经形成一定的气候,产业和生态也逐渐健全起来。然而,国产GPU市场规模和潜力巨大,发展却远远落后于国产CPU。在AI加速计算、国产芯片自主创新和摩尔定律放缓等因素的驱动下,国产GPU和海外巨头的差距会逐步减少。
