








智东西(公众号:zhidxcom)
作者 | ZeR0
编辑 | 漠影
智东西1月4日报道,上周四(12月30日),在北京智源人工智能研究院自然语言处理重大研究方向前沿技术开放日上,北京智源人工智能研究院(以下简称“智源研究院”)发布大模型评测的“命题”新方案——智源指数。
NLP是智源重大学术研究方向之一,由清华大学孙茂松教授任该方向首席科学家,北京语言大学杨尔弘教授任项目经理,学者包括李涓子、穗志方、刘洋、万小军、何晓冬,青年科学家包括刘知远、韩先培、孙栩、严睿、张家俊、赵鑫、杨植麟、李纪为等。
除了发布智源指数外,本次技术开放日期间,24位自然语言处理(NLP)学术专家,20多项前沿报告、10余项最新研究成果“组团”亮相。
一、智源指数CUGE:面向大模型的多层次、多维度评测方案
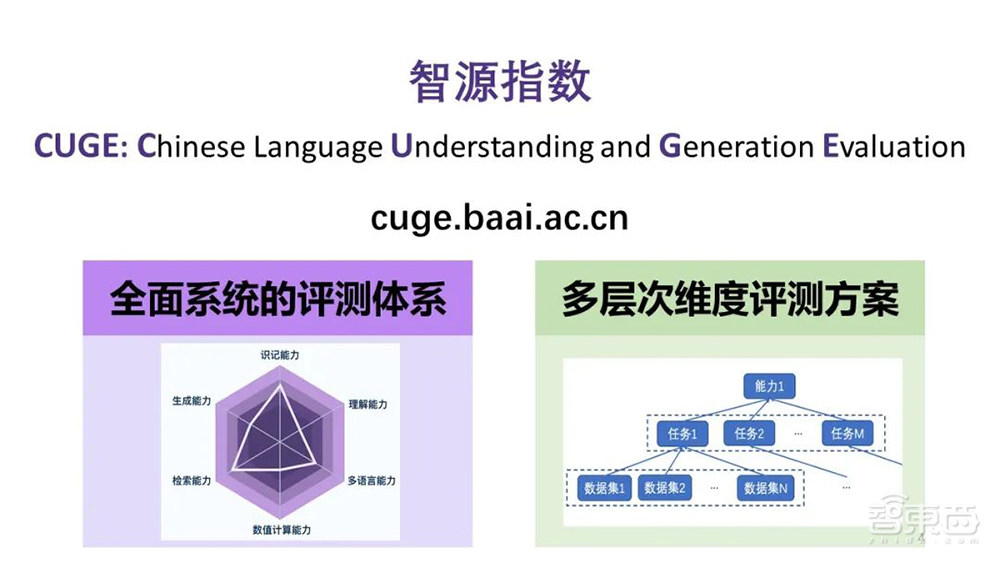
据清华大学副教授、智源青年科学家、智源指数建设骨干成员刘知远介绍,智源指数CUGE(全称为Chinese Language Enderstanding and Generation Evaluation)是一个全面均衡的机器中文语言能力评测基准,在全面系统的评测体系基础上建立了多层次、多维度的评测方案。
CUGE网站链接:cuge.baai.ac.cn
技术报告链接:arxiv.org/pdf/2112.13610.pdf
代码链接:github.com/TsinghuaAI/CUGE
在基准框架上,不同于传统将常用数据集扁平组织的方式,智源指数根据人类语言考试大纲和当前NLP研究现状,以语言能力-任务-数据集的分层框架来选择和组织数据集,涵盖7种重要语言能力、17个主流NLP任务和19个代表性数据集,全面均衡,避免“偏科选拔”。
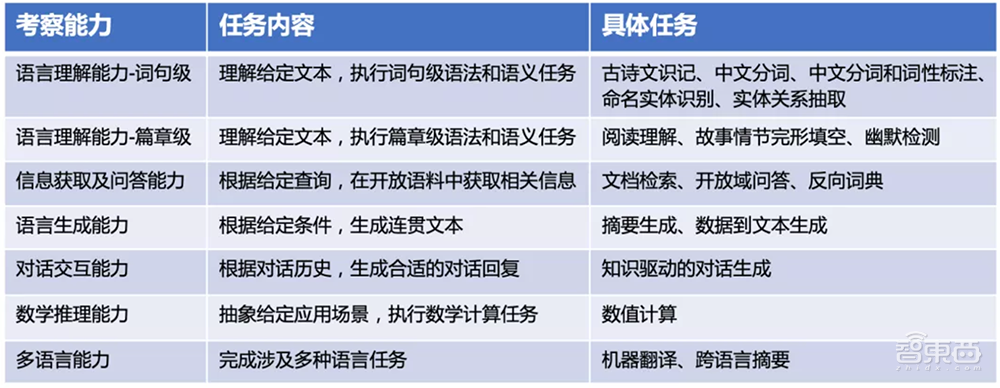 ▲智源指数CUGE框架
▲智源指数CUGE框架
在评分策略上,参考现有评测方案优缺点,智源指数构建了一个多层次的评测方案,能更好展现模型不同维度的模型语言智能差异:依托能力-任务-数据集层次性基准框架,提供不同层次的模型性能评分,系统性大大加强。
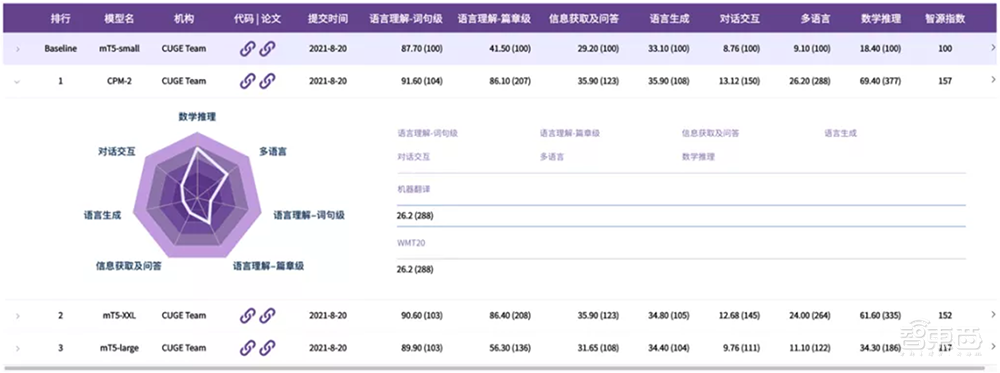
智源指数会提供一个参与者模型的性能排行榜,该排行榜充分吸收了国内外相关评测基准的特点,构建出了一个具有相应特色。
第一,排行榜基于能力-任务-数据集体系,会给每一个数据集所对应的标签,方便参与者筛选出感兴趣的能力或角度,进行相应的评测。
第二,基于标签体系,支持参与者通过标签筛选的方式定制排行榜。同时官方也会提供若干代表推荐套餐,如精简榜等,更加方便地让参与者利用其平台开展有针对性的能力评测。
第三,根据7种重要语言能力呈现雷达图,直观反映不同模型在不同能力上提升的效果。
第四,平台同时会支持单数据集的排行榜和评测,更加有利于参与者去追踪数据集研究的进展和动态。也就是说,任何一个单个数据集,都可以看到相关评测效果的榜单。
“我们希望以学术的视角构建智源指数,让它回归我们本身构造这种评测基准的初心,不是变成刷榜的行为。”刘知远认为,专门针对榜做优化,并不意味着大模型在应用场景中获得很好的效果,这种行为没有意义,反而会浪费非常大的算力和时间。
智源指数会每年定期吸纳新的优秀数据集加入到智源指数的计算中来,同时所有的提交者必须填写Honor Code并展示,不人工干预数据预训练和测试过程。未来智源也计划依托智源研究院、智源社区的力量,提供用户面向数据集和评测结果的反馈意见、讨论机制,通过交互交流来去构建起中文高质量数据集社区的机制,来推动中文的自然语言处理的发展。
为了更好地去支持智源指数的发展,智源研究院搭建了「智源指数工作委员会」,由孙茂松担任主任,穗志方和杨尔弘担任副主任。目前,委员会单位已经吸纳了国内在自然语言处理方面10余家优势单位,接近20个相关优势研究组,去针对智源指数不断进行改进,力求更加科学、规范、高质量地推进中文自然语言处理技术的标准评测。
对此,清华大学教授、中国人工智能学会理事长戴琼海院士评价说:“祝贺孙茂松教授带领智源NLP学者共同建立了机器中文语言能力评测基准智源指数,这对中文信息处理乃至我国人工智能的发展具有重要的里程碑意义。”
二、穗志方:NLP评测中的问题与对策
在智源学者成果报告会环节,北京大学穗志方教授分享了NLP评测中的问题与对策。
他谈到NLP评测中存在的问题涉及评测的规范性、效率、指标、周期、数据集及任务等。
首先,评测缺乏一定规范性。这致使评测的准入门槛非常低,评测数量过多而质量参差不齐,研究者们往往采用对自己的模型最有利的数据集,并声称达到了最好结果,这导致后续研究者难以客观地比较和超越,使得公众难以把握当前领域的真实研究水平。
第二,评测效率衰退。面对参数量越来越大的模型,大部分现有评测任务已经无法明显区分人类水平和机器表现。大部分评测在短时间内失去了效力,这被称之为评测效力衰退。
第三,评测生命周期非常短。部分评测数据集提出后不久,最好的机器模型得分就超过了人类基准。评测系统过快失去效力,缺少生命力。
NLP评测的是语言能力还是语言表现,这是一个比较深刻的问题。周期短、效力衰退仅仅是语言上的一种表现,语言能力如何去真正评估机器的语言能力,我们需要评测的是机器的语言能力,而不仅仅是表层的一种行为临时的呈现。
另一个问题是通用的NLP评测。通用的NLP评测是否能够完整、综合、系统的考察机器理解与语言处理的综合能力?我们看到的是综合性汇总,综合性评测可能并不是综合,只是简单的数据聚合,各任务之间缺乏有机关联,各个任务没有真正结合成一个系统,缺乏一个系统性的体系。
评测技术单一,为什么机器模型在短期内可以达到比较高的水平?有一部分原因是因为评测技术,仅仅依托于固定的训练集、测试集和开发集,一成不变的数据集很容易被机器模型学会、突破,导致评测的生命周期非常短。所以,评测技术方面还有待进一步突破。
三、10余项丰硕成果,智源NLP研究方向探索与落地并重
本次技术开放日中还进行了“自然语言处理评测中的问题与对策”、“迈向通用连续型知识库”、“文本复述生成”等研究成果的阶段性汇报,内容涵盖预训练模型、知识计算、人机对话、文本生成等10余项重点NLP科研问题。
在智源研究院的支持下,自然语言处理重大研究方向学者团队积极探索自然语言处理新格局,通过大数据与富知识双轮驱动,并通过与跨模态信息进行交互,显著提升以自然语言为核心的中文语义理解与生成能力。
落地应用方面,清华大学教授、智源研究员李涓子团队构建的“多模态北京旅游知识图谱”可以为路径规划和景点信息查询等功能提供数据支持,为游客进行旅游行程的规划。
京东集团副总裁、智源研究员何晓冬博士团队针对大规模与训练语言模型在长文本理解任务上的不足,通过从局部视角到全局视角的重复阅读方法(Read-over-Read,RoR),提出了一种基于多视角的机器阅读理解模型,显著地提高了针对长文本的阅读理解能力。
多样性文本复述方面,北京大学王选计算机研究所研究员、智源研究员万小军团队的科研成果实现了两个“业界首个”:成功构建了业界首个面向学术文献领域的文本复述数据集ParaSCI,提出了多样化语句复述模型DivGAN,并提出业界首个篇章复述模型-CoRPG。该系列研究分别为文本复述领域提供了基础数据资源、方法模型以及新的思路,从而推动文本复述技术的应用落地。
预训练大模型方面,为突破预训练语言模型(Pretrained Language Model, PLM)的高计算成本、高设备需求、难应用适配等瓶颈问题,清华大学副教授、智源青年科学家刘知远等提出了面向PLM的全流程高效计算框架, 并基于此框架构建了以中文为核心的超大规模预训练语言模型CPM-2,具有1980亿参数,覆盖多语言、兼顾语言理解和语言生成的功能,并研制了BMInf、OpenPrompt等配套开源工具。
赵鑫、韩先培、张家俊等7位青年科学家,也带来关于预训练模型、多模态语言等方面的最新成果分享,带来新一代学者的前沿思考。
包括NLP方向在内,智源研究院于2019年4月启动的“智源学者计划”,目前已在人工智能的数理基础、人工智能的认知神经基础、机器学习、智能信息检索与挖掘、智能体系架构与芯片等几大研究方向汇聚了近百位一流人工智能学者,鼓励支持学者进行自由探索。
目前,智源研究院坚持“自由探索+目标导向”并重,取得了“悟道”大模型等多项首发、原创级重大成果,已累计支持——发表国际人工智能顶会顶刊论文1470余篇,申请中国专利82件,获得发明专利授权49件,登记软件著作权24项。
接下来,悟道大模型仍将是智源研究院的助推研究方向。在接受媒体采访时,孙茂松教授提到认同大模型发展将进入冷静期的判断,大模型发展现在到了两万亿的参数,再往上发展,单纯的规模扩大有没有意义,但是大模型展现出很多奇妙的、深刻的性质,下一步应该研究,如果把这里面几个问题搞清楚了,有可能让大模型作为一个引子,引出更深刻的模型上的问题,直着走差不多了,但是把大模型消化透,有可能会有比较大的峰回路转。
“奇妙的性质现在还没有得到很好的解释,这个东西搞明白了,对脑科学的研究基本能覆盖,”孙教授说,“因为研究人脑有很多限制,但是研究神经网络人工脑,人工脑所有参数对我们都是透明的,检测也是非常精准的,脑的研究没有这些好的条件。这块如果这个问题研究透了,可能会有更深层次的发展。”
结语:中文NLP评测任重道远
正如戴琼海院士在演讲中所言,如果说自然语言处理是人工智能皇冠上的一颗明珠,建立科学的评价标准就需要寻找这颗明珠的本身,如果方向错了走的越远、偏离越多,很有可能找不到。
近十年里智能语言处理突飞猛进,特别是超大规模预训练语言模型等技术的突破,英文语言能力评价基准发挥了至关重要的指引作用。他希望未来智源指数能够在各位学者、老师和同学们的共同努力下,不断制定完善评价体系,团结更多研究机构和大学、学者、公司、研究人员,贡献重要的力量,也期待未来每年都能够看到基于智源指数的机器中文语言能力的进展和重要贡献。
