








智东西(公众号:zhidxcom)
编辑 | ZeR0
智东西6月1日报道,近期,字节跳动火山语音团队的最新音乐检索系统ByteCover2入选了国际语音技术领域顶会ICASSP 2022。
该系统主要面向音乐信息检索(MIR)领域的重要任务之一——翻唱识别(CSI),通过表征学习方法让其具备提取音乐核心特征的能力,并且该特征能够对种类繁多的音乐重演绎具有良好的鲁棒性,检索速度提高8倍。
经Da-Tacos数据集上的评估,其准确率远超其他方案的SoTA性能。
除了ByteCover2,字节跳动火山语音团队还有多篇论文被ICASSP 2022收录,内容涵盖智能音乐、音频合成、音频理解、超脑等多个方向。
一、翻唱识别:设计隐式嵌入降维方法
翻唱识别往往需要对音乐中的一些常见变化具有鲁棒性,从而保证系统专注于对音乐旋律走向的建模。在设计翻唱识别系统时,音乐调式偏移、音乐结构变化、音乐节奏变化这三种音乐变化通常会被重点考虑。
此外,抖音平台上每日新增千万量级的用户投稿,如何快速应对巨量查询需求,提高识别系统的整体吞吐量并同时确保识别准确性,也是亟待解决的问题。
在内部开发返厂识别时,字节跳动还面临另一挑战,即在设计特征时,如何在保障其他性质的前提下尽可能减小特征大小,从而减少存储空间,降低系统复杂度和成本。
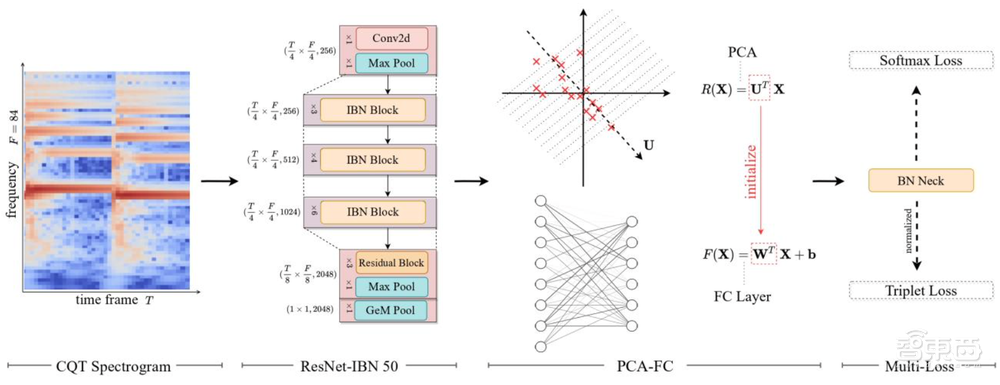
在ByteCover2系统中,字节跳动火山语音团队通过多任务学习范式联合ResNet-IBN模型,做到从音频输入中提取鲁棒且具备区分性的向量表征。针对效率优化问题,团队还提出了PCA-FC模块,实践证明该模块在保证ByteCover2模型性能不变甚至提高的前提下,可将向量尺寸压缩至ByteCover1的1/8。
 ▲Bytecover模型结构与训练流程
▲Bytecover模型结构与训练流程
1、多任务学习提高音乐检索能力
翻唱识别领域通常存在两种训练范式,分别是多分类学习和度量学习。
前者将每个曲目视为一个独立类别,在特征层后加上全连接层,并通过交叉熵等分类损失对模型进行训练,训练完成后去掉全连接层,使用特征层的输出作为歌曲的表征;后者直接在特征层之上,使用triplet loss等度量学习损失训练网络。
总体来看,两种训练范式各有优劣,团队通过实验发现,分类损失往往能提高模型对同曲目不同风格版本的检索能力,细致设计的度量学习损失则能提高翻唱网络对相似风格不同曲目音乐的区分能力。
因此ByteCover系列模型对这两种学习范式进行了结合,并通过引入BNNeck模块,提高了两种损失的兼容性。
2、ResNet网络与IBN正则化方法(ResNet & Instance-Batch Normalization)
为了简化音乐特征提取的流程,加快特征提取速度,团队使用CQT频谱图作为模型的输入,而不使用在同期其他翻唱识别方法中常用的cremaPCP或其他更为复杂的特征,但此设计会天然地在输入特征层面上损害模型对音频频移的鲁棒性。
因此,团队选择卷积神经网络做了音乐表征提取网络,希望能利用卷积网络的平移不变性来实现模型对频移的不变性。
实验证明,CQT谱+普通ResNet组合已在效率和性能上超过CremaPCP+CNN的设计。
深入探究,团队引入了Instance-Batch Normalization来从网络隐表示的层面进一步学习和风格无关的音乐特征,即特征图上不同通道间的均值方差等统计量与输入的风格化特征相关。IN通过对特征图的通道维度做的归一化处理,一定程度上实现了在隐藏表征层面上去除风格化信息,从而提高翻唱识别模型对音色变化的鲁棒性。
3、特征降维模块(PCA-FC)
通过测算,团队发现工业级别的翻唱系统大部分耗时集中在特征检索阶段,而这一阶段的时间消耗基本和曲库的大小以及特征向量的尺寸线性相关。曲库中歌曲的数目会随着业务的增长而不断增加,因此降低特征向量尺寸成为优化检索系统整体耗时的必由之路,而同期其他翻唱向量特征降维的工作往往采用一个全连接层来将高维向量投影到维度更低的空间。
实验结果发现,单纯使用全连接层进行降维会明显降低系统的检索能力,团队认为这种现象不仅是因为更小的尺寸限制了向量的表征能力,性能的损失也来自于随机初始化的全连接层对特征各向同性的破坏。
随后对数据可视化之后可发现,降维后特征分布在一个锥形空间,表现出明显的各向异性,此种性质不利于使用余弦距离为度量的向量检索。
因此团队尝试使用PCA对特征向量进行降维操作并随后用PCA的变换矩阵初始化一个全连接层,把该层和特征提取网络连接进来并联合训练,并将模块称作PCA-FC。
实验结果显示,PCA-FC能显著提升降维模型的检索性能,在保持检索性能不变的前提下向量尺寸可以被压缩8倍。
 ▲对比结果
▲对比结果
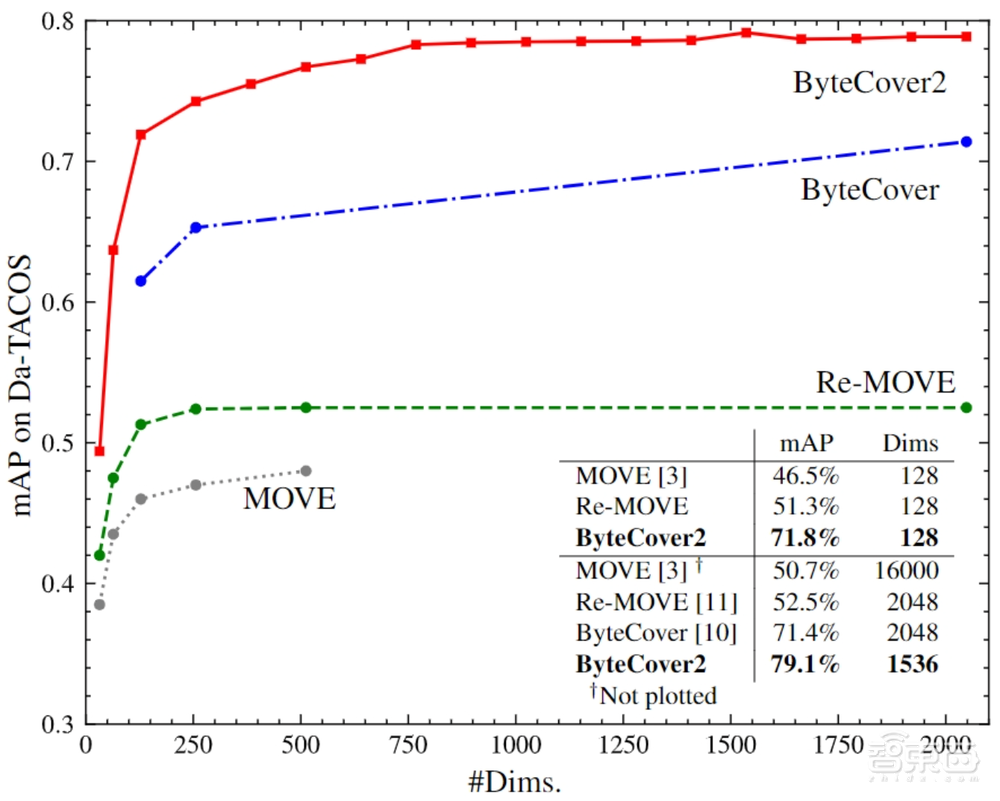
从结果来看,一直以来Da-Tacos是作为评估翻唱识别的基准测试数据集,在该数据集上,采用1536维的ByteCover2模型取得了远超其他方案的SoTA性能,全类平均正确率指标(mAP)达到79.1%,而ByteCover系列以外的最好方法Re-MOVE的该项指标只有52.5%。
值得一提的是,128维的ByteCover2模型甚至超过了2048维的ByteCover1和Re-MOVE方法。
此外,ByteCover1系统还参加了2020国际音频检索评测大赛MIREX,过程中大幅刷新了翻唱识别赛道历年最好记录,mAP指标达到84%,是同年参加该竞赛的其他方案性能的14倍。

二、智能音乐:提高挑选音乐片段效率,创新自监督音乐预训练算法
在智能音乐方向,字节跳动火山语音团队基于Transformer的声音事件检测模型HTS-AT、基于层级式Transformer的自监督音乐预训练算法S3T两篇论文均被ICASSP 2022收录。
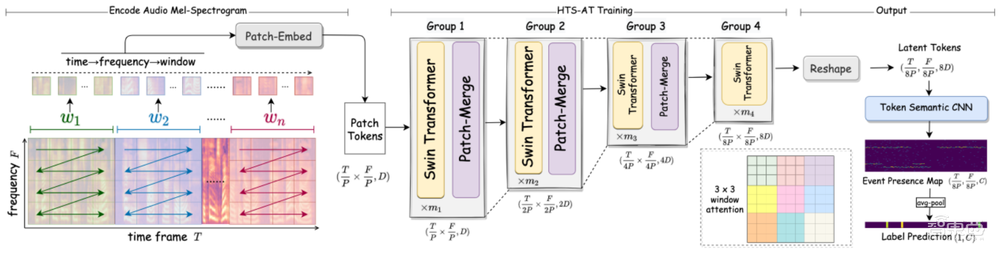
1、HTS-AT:用于声音分类和检测的分层标记语义音频
HTS-AT针对音频任务的特性,该结构能有效提高音频频谱信息在深度Transformer网络中的流动效率,提高了模型对声音事件的判别能力,并且通过降低输出特征图的大小,显著降低了模型地计算量与内存消耗。HTS-AT还引入了Token Semantic模块,使模型具备预测声音时间起始与终止点的能力,并且无需使用额外有标注数据进行训练。
 ▲HTS-AT模型的结构
▲HTS-AT模型的结构
综合以上技术,HTS-AT在标准数据集AudioSet上的mAP指标达到0.471,是当前的该数据集上的最佳水平,且参数与计算量都小于之前的最佳方法;另外,在声音事件定位任务上,HTS-AT无需额外标注数据,即达到有监督定位模型的性能水平。
在音乐识别场景中,声音事件检测模型会挑选包含音乐的片段送入音乐检索系统,以此来提高整个系统的效率与准确性。
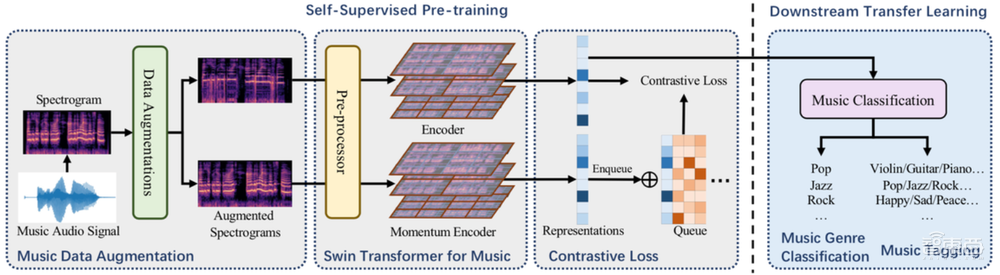
2、S3T:针对音乐分类基于Swin Transformer的自监督预训练
这篇文章提出了一种创新的、基于层级式Transformer的自监督音乐预训练算法S3T。
S3T使用了大规模音乐预训练配合少量标签数据微调的范式,充分利用大量无标签的音乐数据,通过挖掘时域和频域的信息,学习具有较强泛化性的通用音乐表征。S3T在多个下游任务上均取得很好效果,特别是仅使用10%的标签数据进行微调效果便能超过使用以往全量标签数据训练的模型,大幅降低了人工数据标注的成本。
 ▲S3T模型结构与训练流程
▲S3T模型结构与训练流程
音乐自监督学习无需大量人工标签便可利用大量音乐数据充分挖掘其自身的表征,且拥有较强的通用性。本文提出的音乐表征自监督学习,为音乐理解构筑了基础。
S3T目前已经应用在音乐标签、音乐指纹等场景,微调后的S3T可以为音乐打上风格、语种、情绪等标签,可靠的音乐标签可以进一步服务音乐推荐系统,使其精准地向来自不同地区的用户推送合适的音乐。
三、音频合成:实现数字人个性化穿搭和场景自由
在音频合成方向,字节跳动火山语音团队基于服装风格迁移实现场景感知下的人物视频生成论文被ICASSP 2022收录。
该方向致力于解决视频中人物个性化穿搭和背景场景自由的选择问题,设计了多个解耦encoder学习人物不同的属性(身份、衣服和姿态),通过共享decoder融合多层面信息。
不同于图片任务,视频需要学习帧之间的变化,所以团队设计了帧间判别器(Inner-frame Discriminator)来大幅提升稳定性。具体来说,在模型生成的结果上应用掩码,人物可切换到任意场景上。
工作在公开数据集TEDXPeople,相对baseline系统(CVPR2021)视频中衣服个性化的多项客观指标均有显著改善,可以达到SOTA效果:SSIM +0.047,PSNR +4.6,FID(越小越好) -0.4, FVD(越小越好)-0.543。
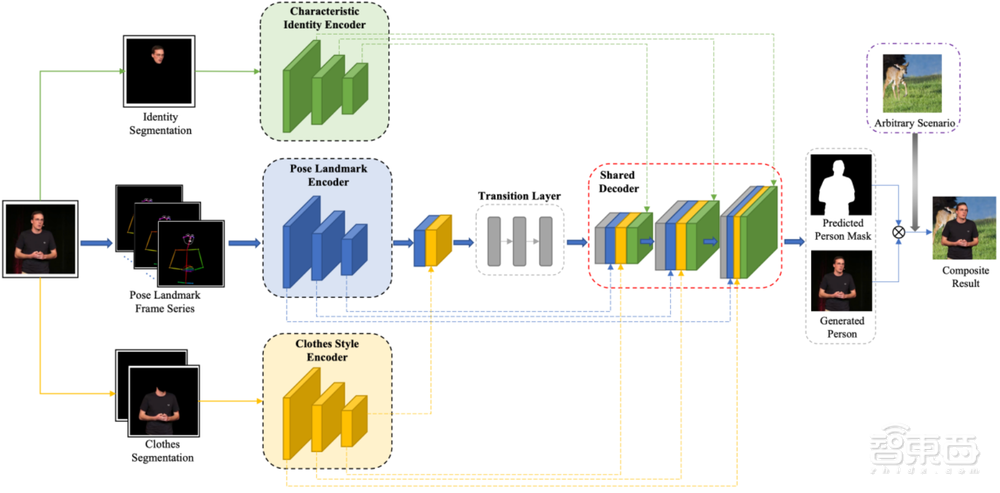 ▲场景感知的服装风格迁移模型框架
▲场景感知的服装风格迁移模型框架
在数字人多模态生成的场景和业务中,数字人主播衣服的个性化穿搭和场景自由的选择,为用户提供了自主可控的个性化能力,可大幅增加数字人生态的多样性。
四、音频理解:提升语音识别定制化性能,优化数据标注质量
在音频理解方向,字节跳动火山语音团队基于细粒度语境知识选择的端到端(语境)语音识别提升方法、非自回归Transformer自动语音识别的最小词误差训练、使用梯度掩码改进端到端语音识别的伪标签训练论文被ICASSP 2022收录。
此外,面向会议场景,火山语音团队在ICASSP 2022多方会议转录挑战赛(M2MeT)的两个限定训练数据子赛道上分获第二名和第四名。
1、基于细粒度语境知识选择的端到端(语境)语音识别提升方法
该工作在一种被称为协同解码(Collaborative Decoding,ColDec)的语音识别定制化/个性化方法的基础上,提出了细粒度语境知识选择机制(Fine-grained Contextual Knowledge Selection),来进一步增强该方法在大热词列表和较多干扰热词情境下的语音识别定制化性能。在先前工作中,一种被称为协同解码(Collaborative Decoding)的语音识别定制化技术有效地提升了定制化识别性能。
本文针对其在大热词列表和较多干扰热词情境下的性能衰减问题,提出了细粒度语境知识选择机制,进一步增强了协同解码技术在定制化场景下的能力。
在公开数据集Librispeech上,本文方法在基础CIF语音识别模型的test-clean 2.12%的WER基础上,进一步为WER带来了约5%的相对下降;在内部16w小时工业级ASR数据集训练的语音识别模型的基础上,该方法在真实会议测试集上为CER带来了最高约16%的相对下降。
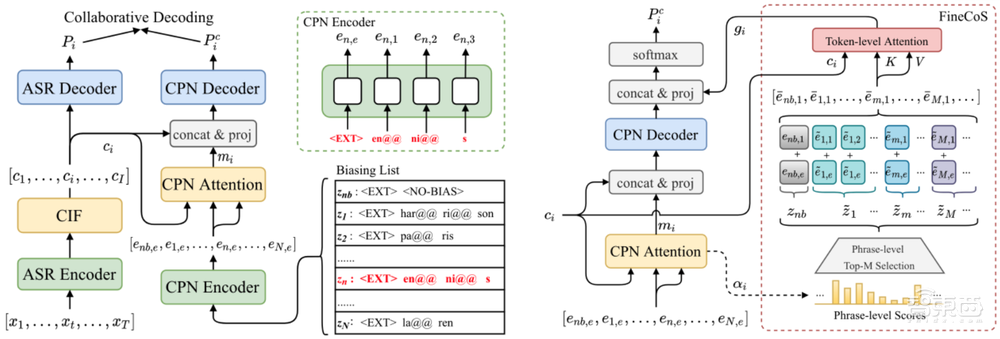 ▲a. 协同解码 b.细粒度语境知识选择
▲a. 协同解码 b.细粒度语境知识选择
应用场景方面,该方法可被用于语音识别定制化,例如在智能语音助手和在线视频会议等应用场景中,许多同背景相关的关键短语、个性化信息、热词等内容都较难识别。
此外,它也可以用在移动端智能语音助手的应用场景下,联系人列表中的联系人姓名,频繁出没的地点位置等个性化信息;在线会议场景下,参会人员的姓名,会议主题相关的专业术语等,针对性地提升这些定制化和个性化文本内容的语音识别性能,在实际应用场景中有重要意义。
2、非自回归Transformer自动语音识别的最小词误差训练
这篇论文由字节跳动和南洋理工大学(NTU)共同完成。近年来由于基于非自回归Transformer(NAT)的自动语音识别(ASR)框架的以下优点,分别是“当前的输出与历史的输出无关”以及“其推理速度非常快”,其在业界日益受到重视。
对此,团队对于其在语码转换语音识别任务(CSSR)上的性能有所期待。另外据不完全了解,似乎并没有出现将最小词错率(MWER)准则应用于NAT模型的先例,所以该工作在一定程度上填补了此项空白,且在SEAME语码转换数据集上得到了验证。
本文的贡献主要在两个方面:(1)在语码转换的场景下,提出了多种CTC掩蔽的方式训练NAT模型;(2)在MWER训练准则下,提出了多种N-best假设的生成方法。
其发现及结论是:(1)无论在单语言还是跨语言的场景下,上下文相关的场景信息非常重要,而NAT没有历史信息,NAT模型相比自回归的Transformer(AT)得到了一致性更差的结果;(2)严重受限于N-best假设的生成方法,在NAT模型上进行基于N-best的MWER训练只得到了细微的提升,所以如何生成更丰富的N-best有待进一步研究。
3、使用梯度掩码改进端到端语音识别的伪标签训练
一直以来,打伪标签在自监督学习中都是最重要的方法,最近在语音识别领域也展现出极好的效果,但是自监督学习对伪标签的质量极其敏感,主要是因为伪标签中的错误或者噪声常常会导致模型训练的不稳定并最终收敛到非最佳的状态,特别是对于e2e的模型比如RNNT。
对此该论文提出了Gradient-mask的方法来应对以上问题。此方法在训练过程中抹去了encoder中可见input的对应梯度,从而鼓励模型从不可见的部分进行推测,并且能有效降低模型对corrupted label的overfit。
应用场景方面,此方法可以有效应对模型overfit到corrupted label并提升模型训练的效果,例如半监督自学习中,因为domain不match等原因导致pseudo-label质量过差,以及已知一部分数据标注质量过差的问题。
4、ICASSP 2022多方会议转录挑战赛的火山语音系统
会议场景是语音识别和说话人日志技术应用中最有价值和挑战的场景之一,会议场景包含了丰富的说话风格和复杂的声学条件,需要考虑重叠语音、未知数量说话人、远场信号、噪音、混响等挑战。
ICASSP 2022多通道多方会议转录挑战(M2MeT)提供了120小时真实记录的中文会议数据,包含8通道麦克风远场数据和对应耳机麦克风采集的近场数据。M2MeT挑战赛包括多说话人语音识别和说话人日志两个赛道,团队在限定训练数据子赛道上分别获得第二名和第四名。
针对多说话人语音识别赛道,团队提出一种神经网络前端模块和语音识别模块端到端联合训练的方法,输入8通道音频输出多说话人识别文本,除此之外加入了丰富的8通道数据仿真,在测试集上和官方基线相比CER相对下降32.6%。
在说话人日志赛道中,结合前端信号处理技术,团队提出一种融合声源定位信息的说话人日志方法,提高识别准确率;同时针对竞赛数据中存在的说话人重叠问题,提出一种多通道融合算法,减少重叠部分的说话人漏检,最后采用修改的DOVER-Lap算法对多套系统进行融合,最终在测试集上的DER(说话人日志错误率)相比官方基线相对下降53.7%。
该技术可以被用在会议室多通道麦克风场景下,生成包含说话人信息的多说话人语音转录结果。
五、超脑方向:单一模型支持跨语言语音识别,减轻部署维护成本
在超脑方向,火山语音团队基于稀疏共享子网络的跨语言语音表征学习论文被ICASSP 2022收录。
该工作提出了一种基于稀疏共享结构的多语言语音表征学习方法,即从模型中划分出多个稀疏子网络来分别对不同语言进行建模,进而实现语言自适应训练,每个语言的子网络都通过裁剪不重要的参数进行提取。
基于此,文中探索了一种基于彩票假设(Lottery Ticket Hypothesis)的提取方法以及另一种基于一阶泰勒展开的快速提取方法。在下游多语言语音识别任务上,所提出的方法可以大幅降低基线XLSR模型的错误率,并超过Gating Network、Adapter等其他自适应训练方法。
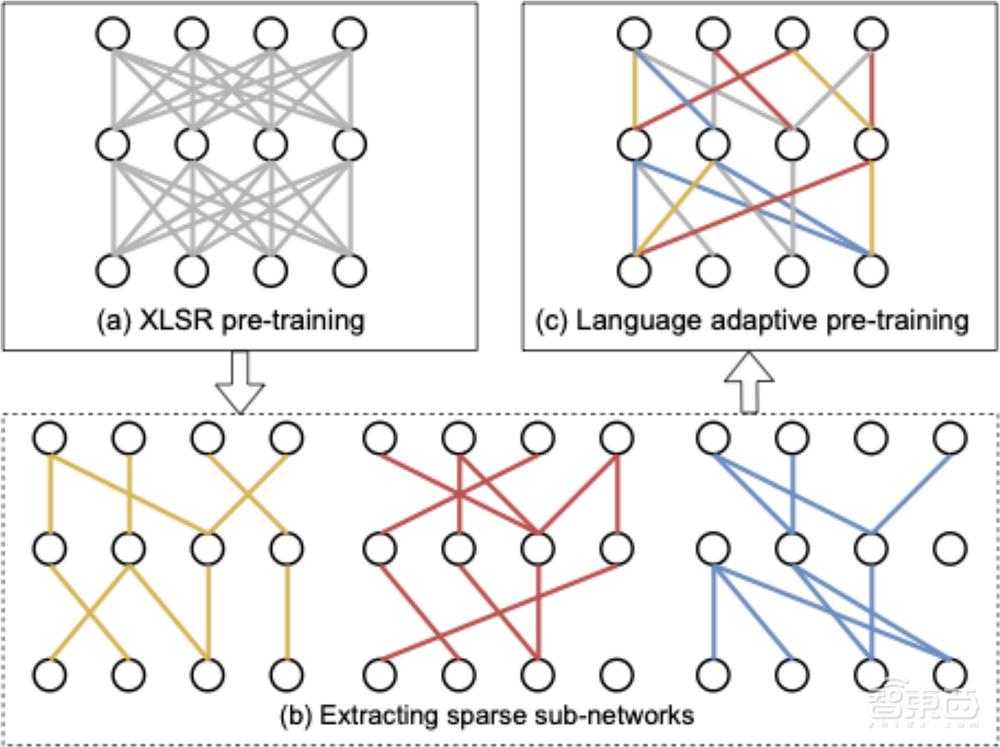 ▲基于稀疏共享结构的多语言预训练流程
▲基于稀疏共享结构的多语言预训练流程
在国际化背景下,为了满足不同语言的字幕、审核和翻译等需求,需要针对各个语言去搭建语音识别系统。多语言语音识别的目标是用单一模型去支持多个语言的语音识别,可以有效的减轻部署和维护的成本,并能在一些低资源场景下提升识别效果,具有非常重要的意义。
结语:AI语音正在业务场景释放更大价值
字节跳动火山语音团队是原字节跳动AI Lab Speech & Audio智能语音与音频团队,致力于为公司各个业务提供音频理解、音频合成、对话交互、音乐检索和智能教学等AI能力与方案。
自2017年成立以来,字节跳动火山语音团队研发的AI智能语音技术,已经为今日头条、抖音、剪映、西瓜视频、番茄小说、飞书办公套件等字节跳动旗下重量级产品提供了各类AI解决方案。
截至目前,该团队已服务上百个业务合作伙伴。伴随字节跳动业务的快速发展,其语音识别和语音合成覆盖了多种语言和方言,已有多篇论文入选各类AI顶级会议,未来希望继续发展70+语言和20+方言,用于满足内容创作与交流平台的需求。随着字节跳动火山语音团队不断探索AI与业务场景的高效结合,我们期待看到其智能语音技术实现更大的用户价值。
