








智东西(公众号:zhidxcom)
作者 | 心缘
编辑 | 漠影
在AI芯片战场上,存算一体正火力全开。
凭借“用存储器做计算”这一独门绝技,存算一体技术通过底层架构创新,解决了传统AI芯片长久以来难愈的痼疾——存储墙、能耗墙及编译墙。其发展潜能已经被学术界和工业界双双看好。
其中有一家创企亿铸科技,选择了一条目前来看尚属「国内首家」的道路——研发基于ReRAM(RRAM)全数字存算一体大算力AI芯片,落地于云端数据中心、智能驾驶等对算力密度、能效比需求很高的应用场景。
这支有备而来的创业新秀成立于2020年,经过1年时间的准备,自2021年10月正式运营以来,正在全速推进研发。谈及优势,其团队非常自信:亿铸科技不仅在ReRAM芯片设计、架构、软件、系统等方面具有国际领先的实力,而且可以得到从核心IP到工艺的全链国产化。
是怎样的底气,支撑亿铸创始团队走上这条之前无人走过的道路?他们将如何克服技术、量产、生态等方面的诸多挑战?围绕这些问题,智东西与亿铸科技CTO Debajyoti Pal(Debu)博士进行了一场独家对话。
Debu已深耕通信、网络和半导体行业30多年,因其在数字通信领域做出的开创性贡献,于2002年当选IEEE院士。他是宽带接入的先驱,也是AI算法及架构专家,曾在美国EDA巨头Cadence及美国明星AI芯片公司Wave Computing负责领导机器学习/深度学习的研发工作,再往前,还曾任高通技术副总裁,负责固定宽带接入技术的研发。
经过深入交流,Debu向我们讲述了亿铸团队在技术定位和技术战略上的深谋远虑,并分享了其产品研发的最新进展以及对AI芯片产业的长期观察。
 ▲Debajyoti Pal博士
▲Debajyoti Pal博士
一、ReRAM商用时代已至,抢占云端存算一体落地先机
高能效比,是存算一体AI芯片的独门杀手锏。
其实现方法不难理解。传统冯·诺依曼架构下存算分离,数据需在计算和存储单元之间频繁移动,数据搬运的时间甚至会达到计算时间的数百倍,并在此过程造成占比逾60%-90%的功耗,还会导致计算效率的下降。而存算一体架构能够从根本上突破这些瓶颈。
存算一体技术按照计算单元与存储单元在系统中的距离可主要分为近存计算、存内计算等。顾名思义,近存计算是把存储阵列跟计算模块的距离拉近,而存内计算通过对存储器件进行改造,使得存储器件可以直接参与计算。两类方法均能大幅减少数据搬运,实现计算效率数量级的提升。
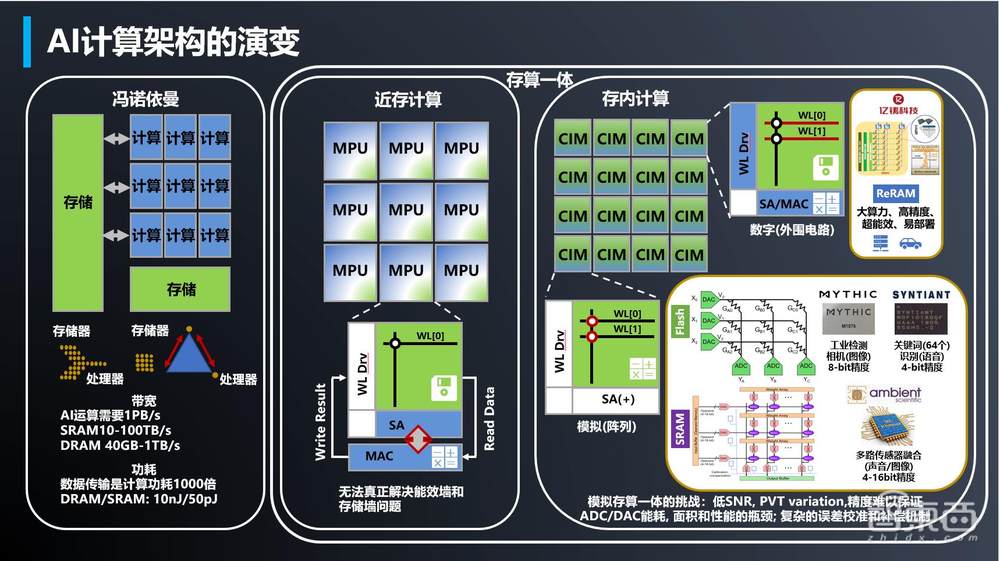 ▲冯·诺依曼、近存计算、存内计算架构对比(图源:亿铸科技)
▲冯·诺依曼、近存计算、存内计算架构对比(图源:亿铸科技)
按存储器件来划分,存算一体有Flash、SRAM、DRAM等成熟存储介质,同时ReRAM、MRAM等新型存储介质也在快速发展。
其中,DRAM多用于近存计算,适合数据中心等大算力场景;此前大部分存内计算采用模拟计算的方法,多选取Flash、SRAM等工艺相对成熟的存储器。由于难以做到足够高的精度、算力,这些技术方案大多被用在低功耗、低精度和中小算力的场景。
但亿铸团队并不担心,相反,这是他们经过深思熟虑做出的决定——作为业界公认的未来存储器挑大梁者,ReRAM的商业化条件已经成熟,亿铸科技也准备好成为第一个“吃螃蟹的人”。
相较传统存储介质,ReRAM拥有存储密度高、能耗低、读写速度快及可下电数据保存(非易失性)等特点,且生产工艺与CMOS完全兼容,可以通过制程工艺的升级迭代持续提升性能和密度。
而且围绕ReRAM的研发及商业化进展,国内的产业链发展也在突飞猛进——中国台湾的台积电和中国大陆的昕原半导体,成为唯二实现28nm制程ReRAM量产的公司。
如今,ReRAM已经被业内知名头部企业采用设计下一代芯片。在2021年台积电的年报中,以ReRAM为代表的新型存储介质市场份额在持续提升。亿铸的紧密合作伙伴昕原半导体目前也已经实现28nm制程ReRAM产品的量产出货。
这些进展持续传递出一个信号:ReRAM技术在存算一体方向的应用和量产已经具备了相应的产业链配套保证。
也正因此,亿铸科技的技术能够实现从软件、架构、芯片设计、工艺、制造的国产化,且核心IP均为亿铸自研以及与合作伙伴共同研发。
二、高精度+高能效比,单板卡突破1000TOPS
目前来看,亿铸将会是世界上率先将存算一体架构切实在AI大算力芯片中设计完成并商用落地的公司。
Debu说,亿铸基于ReRAM全数字存算一体大算力AI芯片,具有高能效比、高精度、高时延确定性、易部署等特点。
存算一体架构芯片的能效比,理论上可以做到传统冯·诺依曼架构芯片的几十倍甚至百倍以上。基于这一思路,亿铸团队在存算阵列架构、模拟域全数字化计算、存算一体芯片架构、自动编译等诸多方面创新设计,实现了亿铸AI芯片可以满足大算力、高能效比、高精度计算等不同方面的要求。
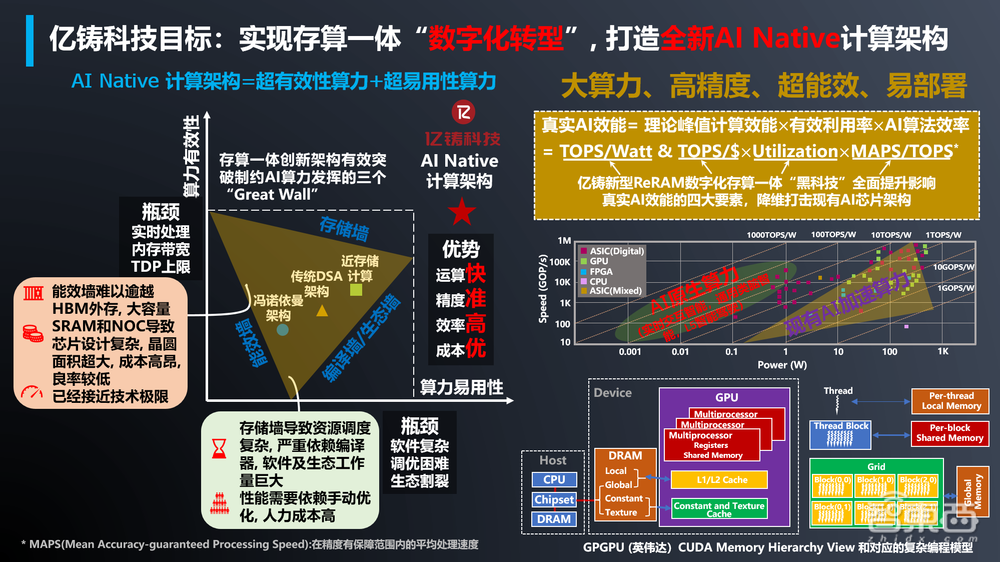 ▲亿铸目标打造AI原生计算架构,用存算一体打破芯片“三堵墙”(图源:亿铸科技)
▲亿铸目标打造AI原生计算架构,用存算一体打破芯片“三堵墙”(图源:亿铸科技)
许多存算一体厂商选择的模拟或模数转换的计算路径,精度往往会受信噪比的影响,精度上限在4-8bit左右,因此多用在对能效比要求较高、对精确度容忍空间大的小算力场景,不适合用在云端数据中心。
而亿铸做的全数字化方案,无需ADC/DAC模数和数模信号转换器,不会受到信噪比的影响,精度可以达到32bit甚至更高,既不会产生精度损失,也不会面临模拟计算带来的诸如IR-DROP等问题。
因为解决了存储墙的问题,相比传统AI芯片方案,存算一体AI芯片能在相同算力下只需更低的功耗,从而节约耗电量和成本;在标准功耗规格的PCIe计算卡上提供更高算力,同在75W功耗的前提下,亿铸ReRAM存算一体大算力板卡算力可达1POPS(INT8)以上(1POPS即1000TOPS)。
在数据中心场景中,计算芯片不是单打独斗,而需形成多芯片扩展、多集群通信管理,这对芯片架构本身及软件均提出了更高的要求。Debu表示亿铸团队非常有信心实现这个技术要求。
三、打破AI芯片的“第三堵墙”
除了存储墙、能耗墙外,AI芯片领域还长期面临第三堵墙——影响芯片易用性的编译墙。
对于云端数据中心客户来说,他们主要关心两件事:一是拥有成本优势,二是能否得到与以前方法一致的用户体验。而满足客户对用户体验的要求,则需在软件上下功夫。
“对于任何AI加速公司来说,你需要建立自己的软件栈。”Debu强调道,软件栈能够利用存算一体架构的优势,更充分地挖掘硬件性能。
由于存算一体芯片主要用于AI推理,更注重部署能力,只要容量足够的情况下,其在软件生态方面没有特别的限制,由于没有存储墙问题,无需优化十分复杂的动态数据流,它的软件优化方面会比传统架构简单很多。
在底层软件上,亿铸SoC及基础软件支持当前绝大部分的硬件算子及软件算子,确保上层软件可以支持绝大多数的AI网络模型。值得一提的是,其AI芯片可以支持Transformer等复杂的神经网络算子,并预留有算子扩展能力。
在功能上,亿铸会提供大部分应用场景的网络及示例代码,并确保成熟度,绝大部分情况下用户可以拿去略加修改后使用。
在工具链上,亿铸会提供相应的模型转换工具,量化工具等方便各种模型进行转换,从而在亿铸平台顺畅运行。
目前,亿铸科技正在开发业界首套针对存算一体架构的包括编译、资源优化和部署的软硬件协同EDA设计工具和应用开发平台。
Debu说,亿铸团队希望在为整个行业开发编译器、映射优化器等软件工具方面处于先锋地位,突破编译墙,推动存算一体芯片商业化落地及生态构建,让更多客户愿意采用存内计算方案来作为其业务应用的底层支撑。
四、明年亿铸第一代芯片落地
据Debu透露,当前他的首要目标是确保亿铸第一代芯片的顺利推出以及规划第二代芯片,亿铸科技第一代芯片将于2023年落地,并于同年投片第二代芯片。
亿铸第一代AI芯片采用28nm工艺,具备数倍能效比优势,尤其二代芯片的计算加速卡的能效比或将实现当前主流AI计算加速卡的10倍左右。
目前,亿铸在上海、深圳、杭州、成都以及美国硅谷设有分支机构。Debu称,随着公司进一步发展,他们还考虑在印度设立研发中心。
融资方面,亿铸科技在去年12月宣布其首笔融资——超亿元天使轮融资,由联想之星、中科创星和汇芯投资(国家5G创新中心)联合领投。
五、业界大牛联手创业,组建全栈式研发团队
由于亿铸科技的芯片相关技术都是在国内本土研发及制造,Debu认为这为亿铸带来另一重优势——不易受到地缘纷争的影响。
Debu在电子半导体行业从业超过30年,是IEEE Fellow、曾任美国斯坦福大学EE系的外部特聘教授,在业内不少知名企业中负责管理大型芯片设计项目/团队。
他曾就职于英特尔公司,是英特尔286微处理器的设计核心成员之一,在美国高通公司担任印度研发团队的负责人,在美国AI CGRA架构的明星独角兽Wave Computing公司担任AI芯片架构设计副总裁。他也是Amati联合创始人,该公司后被TI德州仪器成功收购。
加入亿铸之前,他在EDA巨头Cadence担任机器学习的首席科学家,在此期间,他负责所有关于算法、架构、性能分析和建模的前瞻性工作,以及所有下一代深度学习处理器和加速器的算法和架构,包括DNA100及其后续产品。
Debu还领导了系统性能要求(SPR)、性能分析(PA)、体系结构定义(AD)、模型压缩、量化和再训练算法以及软件包开发等工作,此外他还曾负责下一代DL技术和产品的战略规划,研究和开发基于SRAM的存内计算AI Core,包括架构、电路设计、模拟和性能评估。
除了Debu外,亿铸的其他几位核心团队成员,同样在AI加速、芯片设计、通信网络等领域积累深厚,拥有主流架构SoC量产交付、系统软件研发交付及AI算法研发等方面的丰富经验。
亿铸科技董事长兼CEO熊大鹏在1983年本科毕业于西安电子科技大学,硕士毕业于华南理工大学,在美国德州大学奥斯汀分校获得博士学位,其间还获得应用数学硕士、电气和计算机工程硕士学位。
他曾任美国知名AI芯片公司Wave Computing的中国区总经理,曾带领老牌芯片公司埃派克森的芯片产品线干到世界第二,早在2015年就开始用GPU支持AI算法的芯片规划和设计落地,对于不同技术路径应用于AI大算力场景的优缺点以及该赛道用户面临的痛点有着深刻的技术洞察和企业经营实践。熊大鹏和Debu还都有过半导体风险投资从业经历。
 ▲熊大鹏博士
▲熊大鹏博士
谈及人才方面的竞争力,Debu说:“亿铸的研发团队学历背景非常豪华。”
据他介绍,亿铸研发人员来自哈佛大学、斯坦福大学、德州大学奥斯汀分校、清华大学、上海交通大学、复旦大学、中国科学技术大学等国内外知名院校,成员过往发表的顶级期刊或顶会论文总计达40+篇;且产业实践经验丰富,核心团队成员的半导体从业经验均为30+以及20+年,且均来自业内知名半导体企业。
结语:存算一体,驱动下一代云计算底层创新
看向未来,Debu对存算一体的前景满怀信心。
当摩尔定律趋近极限,制造更先进制程芯片的成本愈发高昂,以存算一体为代表的架构创新被视作进一步提升性能的关键突破路径,3D堆叠技术方案也正走向主流,这同样是Debu非常看好的技术趋势。
他谈道,云端数据中心场景中,CPU和GPU各司其职,但特定领域计算兴起后,却一直没有寻找到真正能给这种工作负载带来大幅性能提升的底层计算架构,而存算正是解决该问题的关键。
随着数据中心支撑的计算规模越来越大,他相信存算一体会产生深远的影响,包括提高大型数据中心的算力部署密度,降低扩容成本,满足大型数据中心对节省电力的需求。这也与“双碳”目标下AI数据中心节能减排的趋势相契合。
而当存算一体AI大算力芯片向数据中心市场展示出其运行AI工作负载时的成本、功能等优势,同时易用性方面更加成熟,相信数据中心客户将逐渐消除对存内计算大算力AI芯片可编程性的顾虑,下游市场的发展又将反哺底层芯片的发展,推动基于存算一体AI芯片架构设计及制造工艺的创新与升级。
