








芯东西(公众号:aichip001)
作者 | ZeR0
编辑 | 漠影
芯东西9月21日报道,昨夜,NVIDIA(英伟达)推出新一代GeForce RTX 40系列显卡。
作为全球首款基于全新NVIDIA Ada Lovelace架构的GPU,RTX 40系列在性能和效率上都实现了巨大的代际飞跃。
其中,新旗舰产品RTX 4090 GPU的现代游戏性能相较上一代3090 Ti提升最高可达2倍,光线追踪游戏性能的提升最高达到4倍,开大招DLSS 3后畅玩4K赛博朋克都不在话下。
英伟达创始人兼CEO黄仁勋在GTC大会主题演讲的GeForce Beyond特别直播上介绍道,这意味着实时光线追踪和利用AI生成像素的神经网络渲染的新时代已然来临。

首发的40系列有三款。旗舰产品RTX 4090 24GB将于10月12日上市,建议零售价12999元起。RTX 4080 16GB、RTX 4080 12GB将于11月上市,建议零售价分别为9499元起和7199元起。
相比之下,RTX 3090首发价是11999元起,RTX 3090 Ti首发价是14999元起,一台顶配iPhone 14 Pro Max首发价是13499元。
这么一看,RTX 4090的性价比“真香”。

华硕、七彩虹、耕升、影驰、技嘉、映众、微星和索泰等顶级显卡供应商将在中国推出GeForce RTX 4090和4080 GPU标频版和超频版。RTX 40系列GPU还会通过宏碁、外星人、华硕、戴尔、惠普、联想、微星等全球领先OEM的产品出售。
NVIDIA还将限量推出RTX 4090和RTX 4080(16GB)FE版,以满足粉丝需求。
这些还只是GTC主题演讲的“前菜”,同样利用Ada Lovelace架构,英伟达面向自动驾驶计算推出了超级芯片DRIVE Thor,算力较上一代DRIVE Orin翻倍,浮点性能达到2000 TFLOPS。
专为元宇宙应用打造的OVX计算机也升级至第二代,搭载了新Ada Lovelace L40数据中心GPU。
还有新款微型机器人计算机Jetson Orin Nano,速度比上一代Jetson Nano快了80倍。
此外,英伟达在今年4月面向数据中心发布的旗舰计算产品H100 GPU同样迎来关键进展——全面投产。
面向元宇宙应用,英伟达还首次通过云服务进一步拓展其平台的覆盖范围——发布英伟达首款软件和基础设施即服务(IaaS)产品Omniverse Cloud,为元宇宙应用的设计、发布、运营和体验提供全面的云服务。

一、40系显卡秒全场!台积电定制版4N工艺
在将近25年前,英伟达推出了可编程着色GPU,GPU彻底改变3D图形。
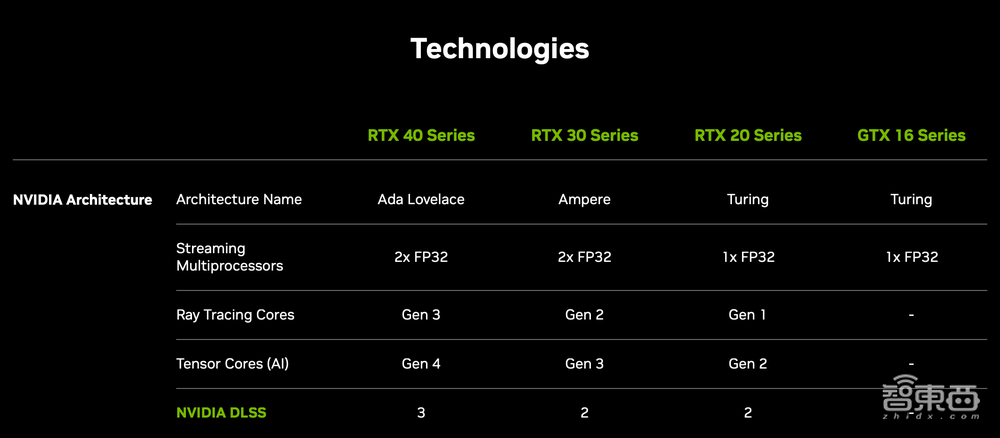
2018年,在全球计算机图形图像顶会SIGGRAPH上,英伟达推出全新GPU架构NVIDIA RTX,通过两个全新处理器来扩展可编程着色器——RT Core用于加速实时光线追踪,Tensor Core用于处理矩阵运算、加速AI。
今天,英伟达憋了4年的大招——第三代RTX架构Ada Lovelace,终于正式登场!
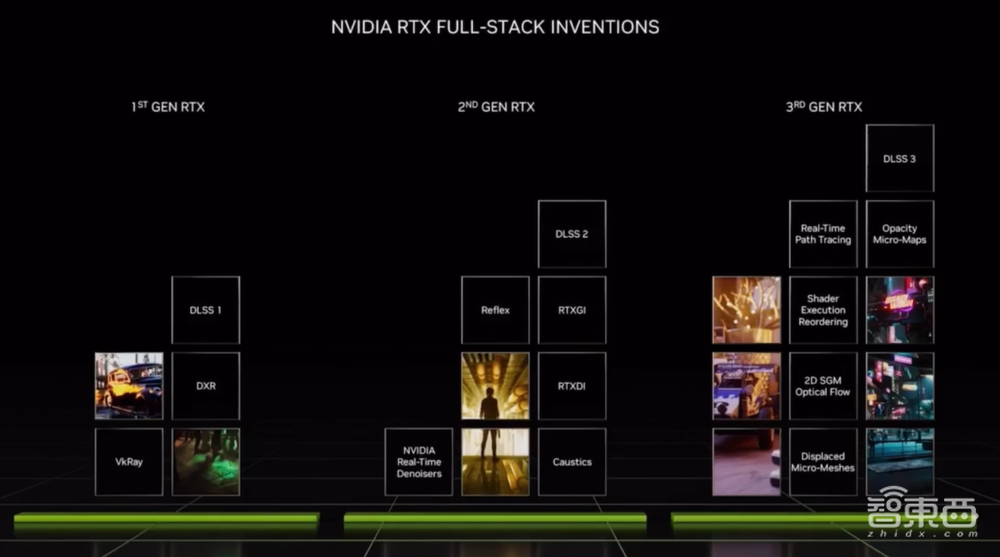
这代RTX以数学家Ada Lovelace的名字命名,她被公认为世界上第一位计算机程序员。
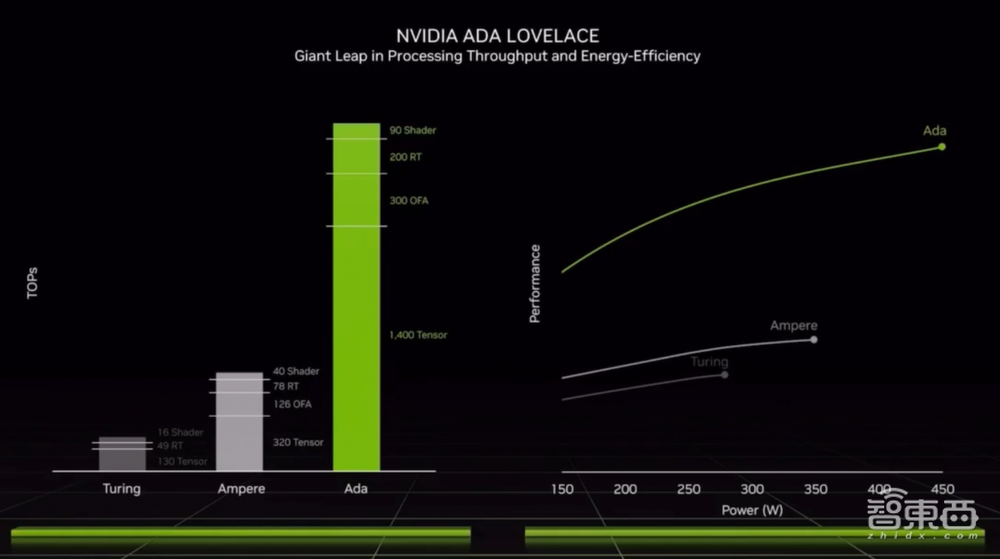
据介绍,Ada GPU可实现2倍的传统光栅化游戏性能提升,对光线追踪游戏的性能提升可以高达4倍。相较上一代Ampere架构,Ada在相同功耗下可带来超过2倍的性能提升。
“Ada正在为完全基于仿真的未来游戏铺路。”黄仁勋说。
今天英伟达推出的基于Ada Lovelace架构的GPU有三款:GeForce RTX 4090提供24GB版本,GeForce RTX 4080提供16GB和12GB版本。

GeForce RTX 4090 GPU是全新GeForce RTX 40系列的旗舰产品,是全球首款基于全新NVIDIA Ada Lovelace架构的游戏GPU。
RTX 4090拥有760亿个晶体管、16384个CUDA核心和24 GB高速美光GDDR6X显存,在4K分辨率的游戏中持续以超过100 FPS运行,在功耗、静音、散热等方面的提升都非常显著。

在完整的光线追踪游戏中,与前一代采用DLSS 2的旗舰GPU RTX 3090 Ti相比,采用DLSS 3的RTX 4090的性能提升可达4倍。
在现代游戏中,RTX 4090的性能提升高达2倍,同时保持了跟RTX 3090 Ti相同的450W功耗。
实现性能飙升的一个关键,是Ada引入了全新的NVIDIA DLSS 3超分辨率技术。该功能可在不影响画质和响应速度的前提下,使用低分辨率内容作为输入,并运用AI技术创造更多高质量帧。

黄仁勋说,玩像《赛博朋克2077》这样的现代光线追踪游戏,需对每个像素执行超过600次光线追踪计算来确定光照,与4年前推出的首批光线追踪游戏相比提升高达16倍。但GPU中负责此类计算的晶体管数量并没有以同比增加,借助AI,英伟达在4年内将性能提升了16倍。
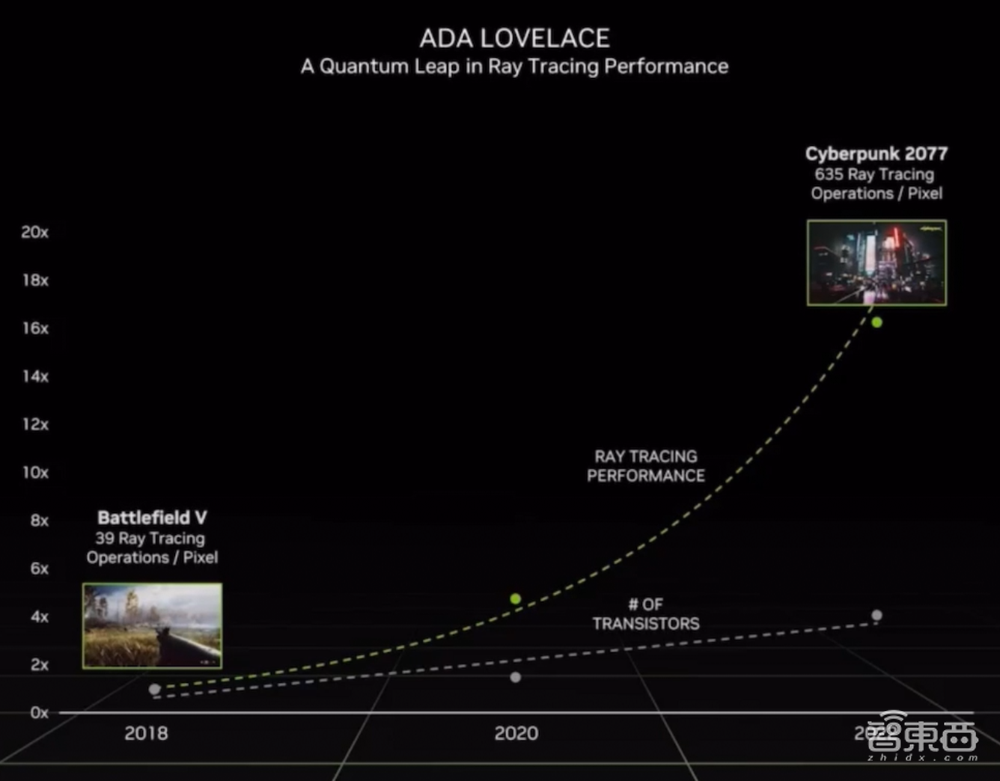
无论是对GPU性能要求较高的游戏,还是受到CPU限制的游戏,都将从该技术中受益。3D艺术家无需代理就可以利用精确的物理学和逼真的材料渲染完整的光线追踪环境,并实时查看效果。
两款次旗舰RTX 4080的配置则明显跟RTX 4090拉开了差距。
RTX 4080 16GB拥有9728个CUDA核心和16 GB高速美光GDDR6X显存,在现代游戏中的性能可达GeForce RTX 3080 Ti的2倍;在较低功率下,性能比GeForce RTX 3090 Ti更强。
RTX 4080 12GB拥有7680个CUDA核心和12GB 美光 GDDR6X显存,性能跟3090 Ti同级。

二、7大技术创新,带飞RTX 40系列性能
这次RTX 40系列GPU的性能大幅提升,背后有一系列技术创新的支撑。
1、架构上的改进:英伟达与台积电合作创建了针对GPU优化的4N定制工艺,使RTX 40系列能够集成760亿个晶体管、超过18000个CUDA核心,较上一代Ampere多了70%,性能功耗比提升高达2倍。
2、SM流式多处理器:具有高达90 TFLOPS的着色器能力,吞吐量超过上一代产品2倍。
3、着色器执行重排序(SER):通过即时重新安排着色器负载来提高执行效率,从而更好地利用GPU资源。该技术可以实时重新调度任务,被黄仁勋称作是“与CPU的乱序执行一样的重大创新”,可将光线追踪性能提升2-3倍,整体游戏性能提升25%。
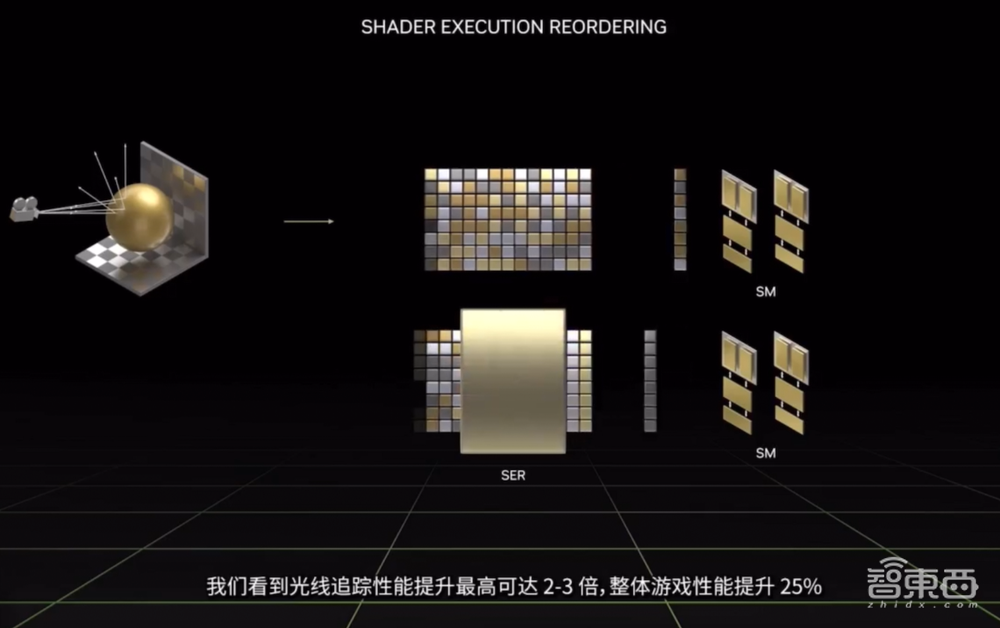
4、第三代RT Cores:有效光线追踪计算能力达到191 TFLOPS,是上一代产品2.8倍。
第三代RT Cores可提供2倍的光线与三角形求交性能,及两个全新的重要硬件单元。Opacity Micromap引擎将光线追踪的Alpha-Test几何性能提升2倍;Micro-Mesh引擎可动态生成微网格,以产生额外的几何图形,可在提升几何图形丰富度的同时,不以传统复杂几何图形处理的性能和存储成本为代价。
5、第四代Tensor Cores:新增Hopper FP8 Transformer Engine,FP8张量处理性能高达1.4 Petaflops,超过上一代使用FP8加速性能的5倍。
6、Ada光流加速器:带来2倍的性能提升,使DLSS 3能够预测场景中的运动,使神经网络能够在保持图像质量的同时提高帧率。
7、双NVIDIA编码器(NVENC)将输出时间至多缩短一半,并支持AV1。OBS、Blackmagic Design DaVinci Resolve、Discord以及更多的公司都已在采用NVENC AV1编码器。
三、2000 TFLOPS,最强自动驾驶超级芯片来了!
在推出新一代自动驾驶芯片前,黄仁勋照例先回顾了一遍战绩:英伟达在2018年推出的Xavier是世界上第一款专为深度学习设计的机器人处理器,此后每隔两年,英伟达就会发布性能飞跃的新一代处理器。去年,英伟达发布的Altan更是将峰值性能拉到了1000T。
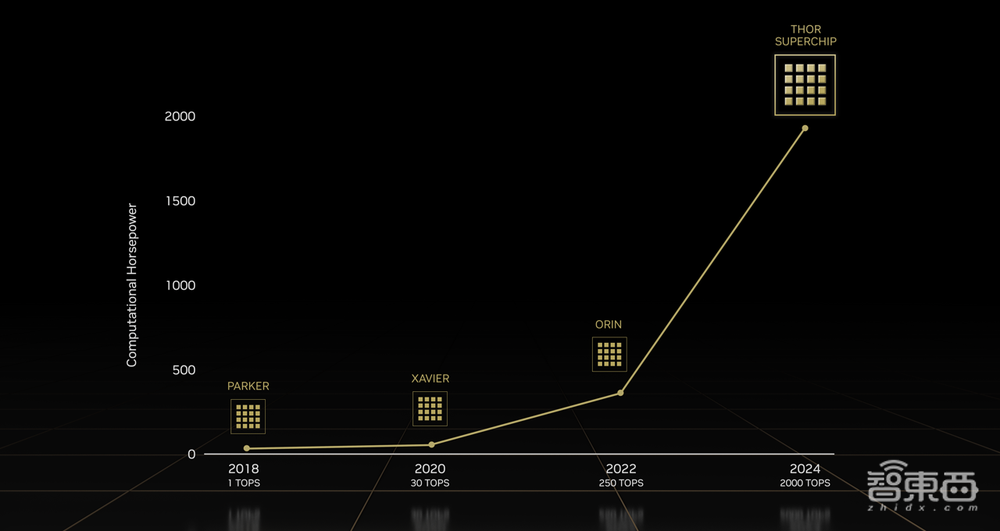
今天,黄仁勋放出新的大招——NVIDIA DRIVE Thor的吞吐量达到Atlan的2倍,整型峰值性能可达2000 TOPS,FP8精度的峰值性能可达到2000 TFLOPS,同时降低整体系统成本,目标是汽车制造商的2025年车型。
实现这一目标,得益于三个因素:Grace CPU、Hopper GPU和Ada Lovelace GPU。Hopper集成的Transformer引擎有助于加速计算,Ada中多实例GPU的发明将有助于车载计算资源的集中化,可将成本降低数百美元。

Thor可配置为多种模式,可将其算力全部用于自动驾驶工作流,或者将其中一部分用于驾驶舱AI和信息娱乐,另一部分用于驾驶员辅助。
Thor的多计算域隔离,使其允许并发的、对时间敏感的多进程无中断运行。车辆可以在一台计算机上,同时运行Linux、QNX和Android。
当前汽车的停车、主动安全、驾驶员监控、摄像头镜像、集群、信息娱乐等功能由不同的计算设备控制,未来这些功能可以统一由Thor支撑。

两个DRIVE Thor还能利用最新的NVLink-C2C芯片互连技术“拼接”成一块功能更强的芯片,作为运行单个操作系统的整体平台。
回到英伟达第二代机器人处理器DRIVE Orin上,Orin已经被40多家汽车、卡车、无人驾驶出租车和穿梭巴士的制造公司采用。自动驾驶汽车的基本处理流水线可应用于各种机器人系统。
Jetson系列是英伟达打造的机器人计算机,拥有100万开发者,在本届GTC大会上,黄仁勋宣布推出一款微型机器人计算机Jetson Orin Nano,速度比上一代Jetson Nano快了80倍。

有移动的机器人,也有观察移动物体的机器人系统。英伟达边缘AI平台Metropolis的下载量已达100万次,在全球拥有1000多家应用合作伙伴。Orin还是Metropolis运行所在的工业级IGX Edge AI平台的机器人处理器。
全球大型工业自动化公司西门子将Metropolis和Orin IGX用于其工业边缘计算平台。
除了机器人开发外,Orin IGX也是医疗影像应用的理想计算平台。在Orin IGX上运行的NVIDIA Clara Holoscan是一个低延迟的成像处理平台,包含用于数据处理、AI模型训练、仿真和机器人开发应用的库。70多家领先的医疗设备公司、创企及医疗中心都在Clara Holoscan上进行开发。

Activ Surgical、Proximie和Moon Surgical将在运行于Orin IGX平台的NVIDIA Clara Holoscan上构建其手术机器人系统。
四、剑指元宇宙:第二代OVX计算机升级Ada架构,推出首款Iaas云服务
面向元宇宙应用,黄仁勋宣布推出第二代OVX计算机,由全新Ada Lovelace L40数据中心GPU和增强的网络技术提供支持,以提供突破性的实时图形、AI和数字孪生模拟功能。

借助48GB超大帧缓冲区,拥有8个L40 GPU的第二代OVX将能完成超大的Omniverse虚拟世界仿真。L40 GPU已全面进入量产。第二代OVX系统将于明年年初向市场提供。
除了元宇宙专属硬件外,英伟达还打造了其首款IaaS产品Omniverse Cloud服务,可连接在云、本地或设备上运行的Omniverse应用。个人或团队可以借助该服务一键体验设计和协作3D工作流程的能力,而无需任何本地计算能力。
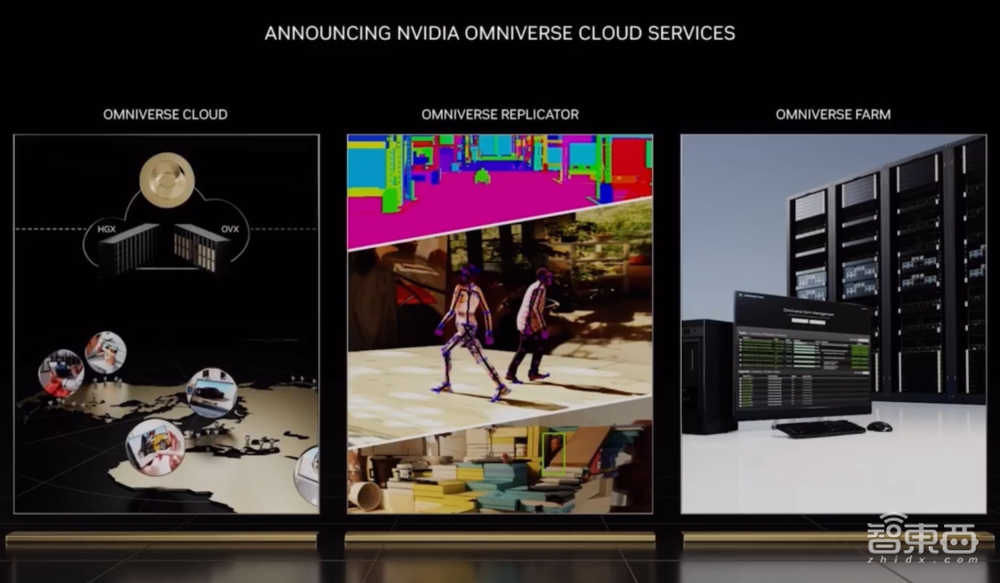
新的Omniverse容器现已可用于云部署,包括用于生成合成数据的Replicator、用于扩展渲染农场的Farm、用于构建和训练AI机器人的Isaac Sim等。
英伟达为自主移动机器人打造的Isaac平台进入云端后,用户可在NGC上获取云就绪的Omniverse VMI虚拟机镜像和Isaac容器,并将其部署到任何公有云上。
五、从云端到超算,H100全面投产
最后,我们来看一下面向数据中心和高性能计算的加速计算最新进展。
黄仁勋说,NVIDIA平台现已拥有350万名开发者,12000家创企正基于英伟达的产品开创新业务,英伟达通过550个SDK和AI模型为约3000个应用提供加速。“总体来说,我们所服务的各行业总价值约为100万亿美元。”
面向数据中心,英伟达在今年4月发布的最新旗舰产品H100 Tensor Core GPU已经进入大规模量产。
H100包含800亿个晶体管,采用了全新Hopper架构、Transformer引擎、第二代多实例GPU、机密计算、第四代NVIDIA NVLink互连、DPX指令等多种创新技术,能够被用于加速高级推荐系统、大型语言模型等超大规模的AI模型训练。

据介绍,H100使企业能够削减AI的部署成本,相较于上一代A100,在提供相同AI性能的情况下,可将能效提高3.5倍,总体拥有成本减少至1/3,所使用的服务器节点数也减少至1/5。
英伟达全球技术合作伙伴计划于10月推出首批基于NVIDIA Hopper架构的产品和服务,到今年年底预计将有超过50款服务器型号面市,2023年上半年还将有数十款型号面市。
AWS、谷歌云、微软Azure、Oracle Cloud Infrastructure将从明年开始率先在云端部署基于H100的实例。数家全球领先的高等教育和研究机构的新一代超级计算机也将采用H100。
DGX H100系统现在即可订购。该系统FP8精度的峰值性能可达到32 PFlops。每个DGX系统都包含NVIDIA Base Command和NVIDIA AI Enterprise软件,可实现从单一节点到NVIDIA DGX SuperPOD的集群部署。
在软件支持上,H100现包含为期五年的NVIDIA AI Enterprise软件套件许可,这将优化AI工作流程的开发部署,确保用户可获得构建AI聊天机器人、推荐引擎、视觉AI等所需的AI框架和工具。
一些全球领先的大型语言模型和深度学习框架正在H100上进行优化,这些框架与Hopper架构相结合,能够显著提升AI性能,将大型语言模型的训练时间缩短到几天乃至几小时。
六、推出两种大型语言模型服务,助攻生物医学研究
大型语言模型(LLM)是当今最重要的AI模型之一。借助LLM,用户只需通过较少的样本来精调模型,就能高效执行特定任务。Hopper架构则有助于降低LLM的训练及部署门槛。
今天,英伟达推出Nemo LLM云服务,用于训练大型语言模型。
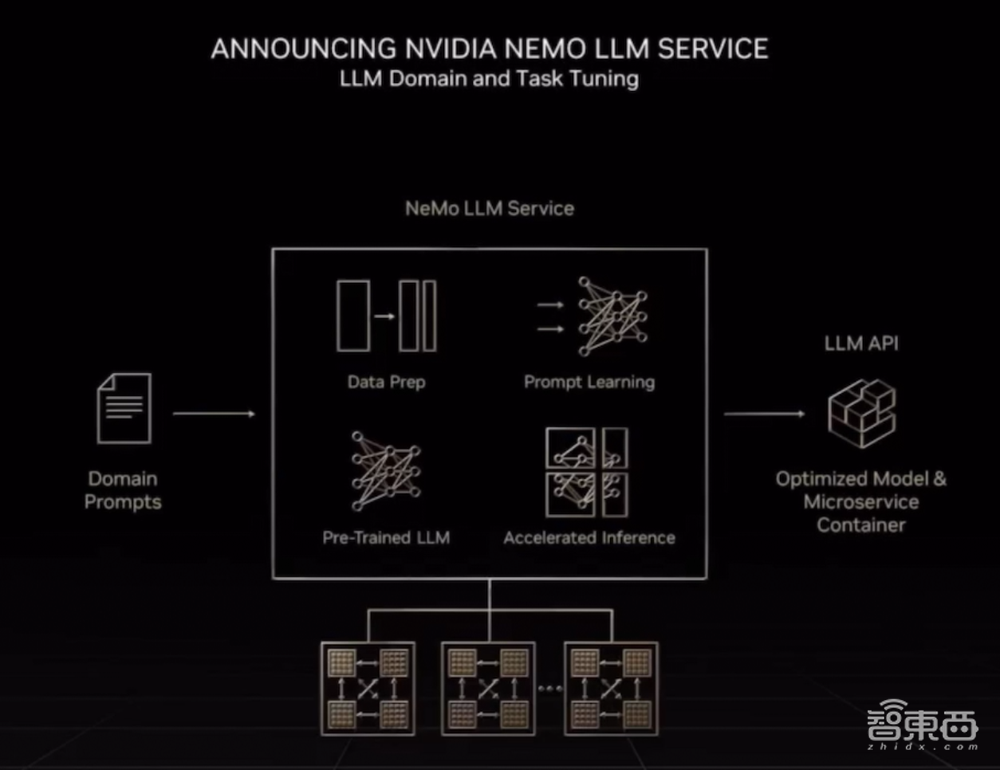
Nemo包含社区构建的一系列预训练基础模型,其API可生成习得的提示embedding表和优化的微服务,可部署在本地、云中,适用于一个GPU或者多个GPU、多个节点。现在注册,10月就能抢先体验这项服务。
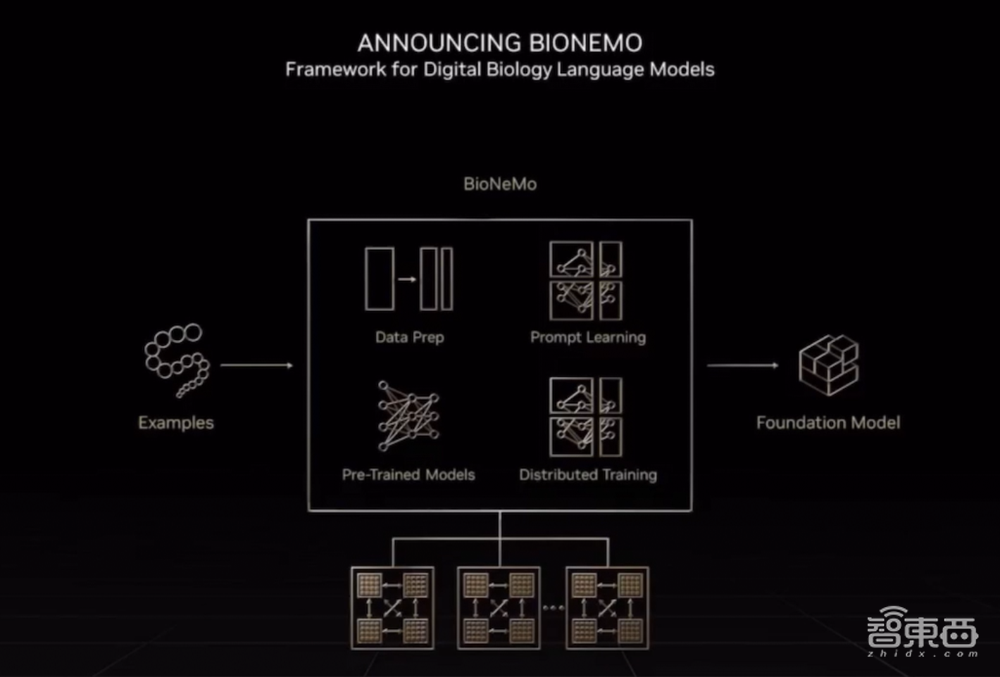
英伟达还推出了BioNeMo LLM服务,用于训练和部署超算规模的大型生物分子语言模型。
领先的制药公司、生物技术初创企业和前沿生物研究人员正在使用BioNeMo LLM服务和框架来开发用于生成、预测和理解生物分子数据的AI应用,从而更好地了解疾病,并找到治疗方法。
NVIDIA BioNeMo LLM服务将提供4个预训练语言模型:
1、ESM-1:这一最初由Meta AI Labs发布的蛋白质LLM能够处理氨基酸序列,最终生成用于预测各种蛋白质特性和功能的表征。它还提高了科学家理解蛋白质结构的能力。
2、OpenFold:这是由学术界和产业界共同成立的Openfold联盟创建的sota蛋白质建模工具,可通过BioNeMo服务提供其开源AI工作流程。
3、MegaMolBART:这一基于14亿分子训练而成的生成式化学模型可用于反应预测、分子优化和新分子的生成。
4、ProtT5:该模型是在慕尼黑工业大学RostLab的带领下合作开发的,NVIDIA也是该项目的参与者之一。PortT5将ESM-1b等蛋白质LLM的功能扩展到序列生成。
这些模型针对推理进行了优化,并将通过NVIDIA DGX Foundry上运行的云端API提供抢先体验。
结语:英伟达已成为一家全栈式计算公司
英伟达在1999年发明的GPU,激发PC游戏市场的增长、重新定义了计算机显卡并助燃了现代AI普及的浪潮。此次新推出的Ada Lovelace一代GPU,改进了作为神经渲染引擎的全部三个RTX处理器,对于游戏玩家、虚拟世界创作者都带来了新的生产力工具。
可以看到,如今的英伟达已发展成为一家全栈式计算公司,无论是加速计算,还是计算机图形,都通过在架构、设计和算法方面进行创新叠加来实现性能的突破。与此同时,AI技术已经渗透到英伟达产品的各个角落,用于与更多技术创新的结合,推动科学及工业领域更多AI新应用的突破,并为数字经济发展提供动力。
