








芯东西(公众号:aichip001)
编译 | 段祎
编辑 | Panken
芯东西3月30日消息,3月25日,据Tom’s Hardware报道,一位名叫Les Pounder的技术人员修改了软件开发者Georgi Gerganov写的C/C++模型llama.cpp。Les Pounder称,使用具有8GB RAM的Raspberry Pi 4(树莓派:微型电脑主板)下载llama.cpp后,通过运行代码可以创建一个基于LLaMA(社交软件巨头Meta开发的大型语言模型)的类似ChatGPT的聊天机器人。
不过由于中端硬件算力方面的限制,Raspberry Pi 4上的LLaMA运行缓慢,加载聊天内容可能需要几分钟时间。如果想要一个响应更快的聊天机器人,需要配备RTX 3000系列的计算机或更快的GPU。
运行像ChatGPT这样的聊天机器人需要强大算力GPU的支持。从诸如GPT-4、LLaMA等大型语言模型开源以来,许多相关技术人员通过再次开发程序,改变配置,使此类大型语言模型可以成功应用于消费级PC、Raspberry Pi等中端硬件上。如果追求该模型的运行速度,可以使用Linux台式机或笔记本电脑。
一、大模型对本地硬件的要求:运算效率高,内存容量大
此前,如果要想在电脑上运行ChatGPT,不仅需要强大的算力硬件核心,如CPU+GPU、FPGA、ASIC等,而且还需要考虑硬件的稳定性、吞吐量、运算效率等。如今,随着各大型语言模型开源,找到获取它们的路径并不难,但这些大型语言模型占用的内存依旧却非常之大。
例如LLaMa-13B包含36.3GiB(注:计算机硬盘存储单位)的主要数据、6.5GiB用于预量化的4比特模型。这需要24GB VRAM和64GB系统内存的显卡才能获取。甚至还有一个650亿参数的语言模型,需要有英伟达A100 40GB PCIe卡以及128GB的系统内存才能下载获取。
想要以16比特精度运行基本语言模型,使用英伟达的RTX 4090、RTX 3090 Ti、RTX 3090或Titan RTX显卡可以将性能发挥到最好。所有具有24GB VRAM的卡都可以用于运行具有70亿个参数的语言模型(LLaMa-7B),但很少有家庭用户可能拥有这样的显卡。
但若以8比特精度加载语言模型,就可将VRAM内存容量减半,这意味着任何具有至少10GB VRAM的显卡可以运行LLaMa-7B。以此类推,更好的是,以4比特精度加载语言模型再次将VRAM内存容量减半,从而让LLaMa-13B在10GB VRAM上工作。

▲英伟达RTX 4090(图源:Tom’s Hardware)
ChatGPT对硬件配置的高要求限制了其在类似树莓派这样的中端硬件上运行,但依靠Georgi Gerganov开发的C/C++模型llama.cpp,完成这个项目只需要8GB RAM的Raspberry Pi 4、具有16GB RAM运行Linux的PC、16GB或更大的格式化为NTFS的USB驱动器。
二、在Raspberry Pi 4上运行LLaMA,生成“BOb”聊天机器人
该过程的第一部分是在Linux PC上设置llama.cpp,下载LLaMA 7B模型,转换它们,然后将它们复制到USB驱动器上。同时需要使用Linux PC来转换模型,因为Raspberry Pi中的8GB RAM是不够的。具体操作如下:
1、在Linux PC上打开终端并确保安装了Git(开源的分布式版本控制软件):

2、使用Git克隆数据库:

3、安装一系列Python模块,这些模块将与LLaMA模型一起创建聊天机器人:

4、确保安装了G++和build essential,这些是构建C程序所必须的:

5、在终端中将文件目录更改为llama.cpp:

6、构建项目文件,按回车键运行:

7、使用以下链接下载LLaMA 7B torrent:

8、优化下载,只下载7B和tokenizer文件,其他文件大小达数百GB:
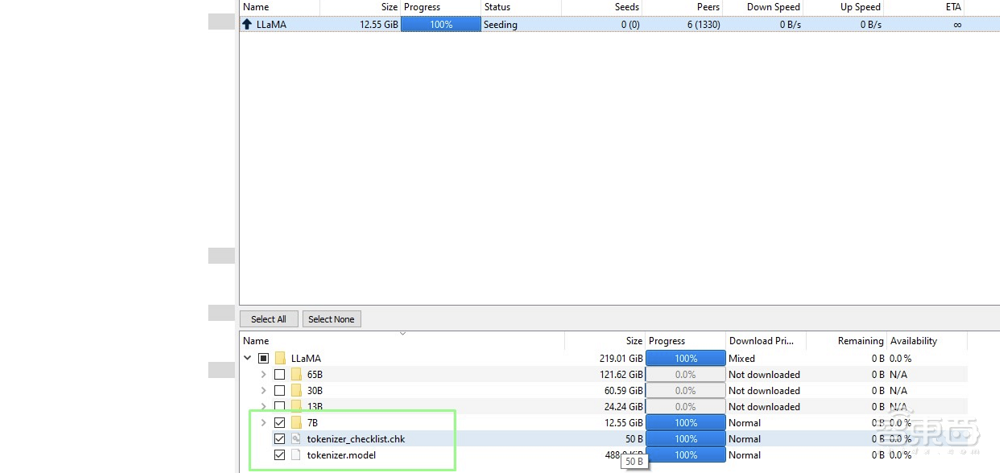
▲操作图(图源:Tom’s Hardware)
9、将LLaMA 7B和分词器文件复制到/llama.cpp/models/。
10、在主目录中打开终端并转到llama.cpp文件夹:

11、将LLaMA 7B模型转换为ggml FP16格式。这可能需要消耗一段时间,使用16GB RAM会使速度更快。此操作将整个13GB models/7B/consolidated.00.pth文件作为pytorch模型加载到RAM中。在8GB Raspberry Pi 4上尝试此步骤将导致非法指令错误。

12、减少LLaMA 7B模型的大小,将模型量化为4比特:

13、将/models/的内容复制到USB驱动器。
最后一部分,在Raspberry Pi 4上重复llama.cpp设置,然后使用USB驱动器复制模型。然后加载一个交互式聊天会话并问“Bob”一系列问题,除了要求它编写Python代码。此过程中的第9步可以在Raspberry Pi 4或Linux PC上运行。
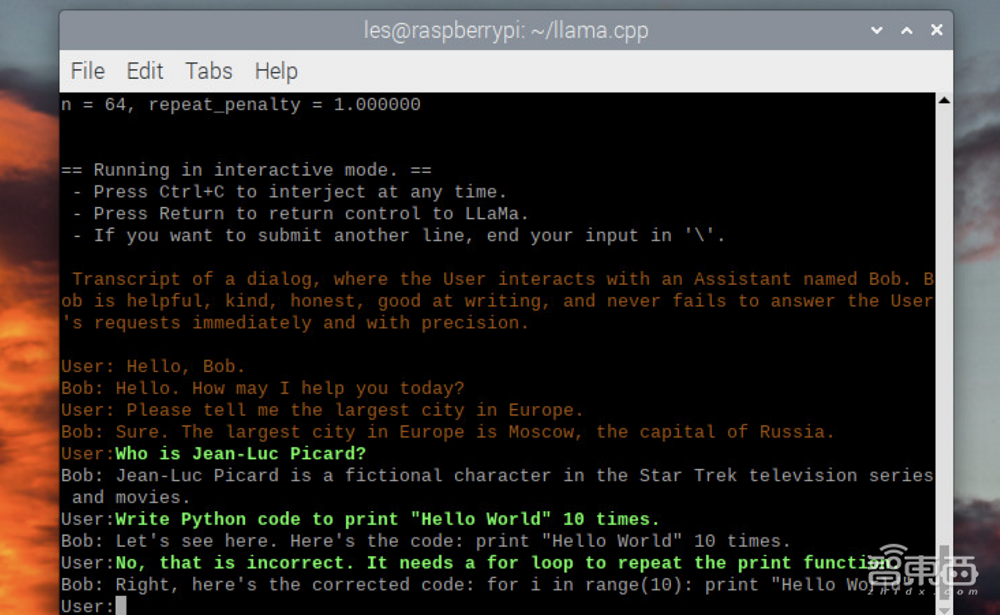
▲代码图(图源:Tom’s Hardware)
1、在桌面启动Raspberry Pi 4。
2、打开终端并确保安装了Git:

3、使用Git克隆数据库:

4、安装一系列Python模块,这些模块将与LLaMA模型一起创建聊天机器人:

5、确保安装了G++和build essential,这些是构建C程序所必须的:

6、在终端中将文件目录更改为llama.cpp:

7、构建项目文件,按回车键运行:

8、插入USB驱动器并将文件复制到/models/,这将覆盖模型目录中的所有文件。
9、开始与“Bob”聊天会话。这是需要一点耐心的地方,尽管LLaMA 7B模型比其他模型占用内存更小,但对于体积本身就很小的Raspberry Pi来说,它的内存仍然较大,故加载模型可能需要几分钟时间。

10、问“Bob”一个问题,然后按Enter。
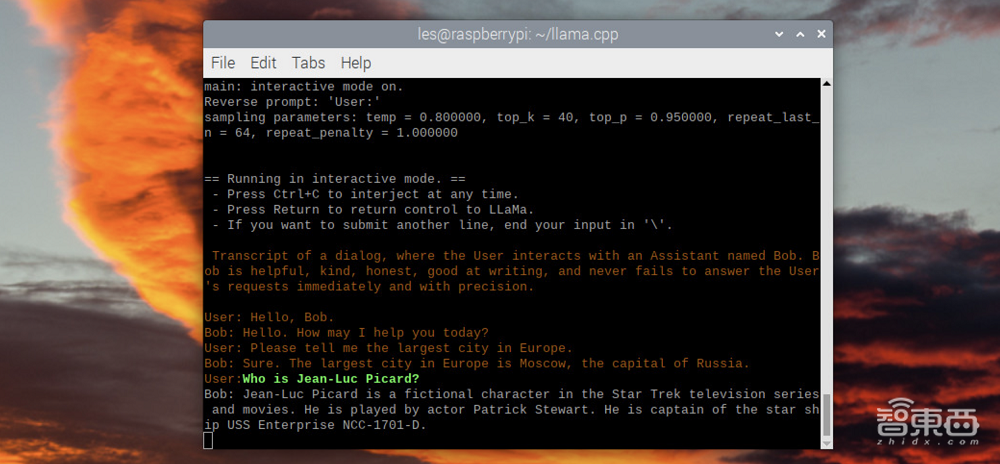
▲代码图(图源:Tom’s Hardware)
结语:借力开源大模型,中端硬件也能跑聊天机器人
聊天机器人ChatGPT的爆火吸引了大量用户,人们对类似的生成式AI产生了浓厚的兴趣。自社交巨头Facebook的母公司Meta最近发布全新人工智能大型语言模型LLaMA以来,研究人员和工程师都在积极探索人工智能应用和相关功能。接受了20种语言训练的LLaMA模型已经被大量开发者在生成文本、对话、总结书面材料等应用。
通过采用C/C++和Python语言将LLaMA模型应用在体积小巧的树莓派上,生成的“BOb”机器人便可以和用户进行简单对话,这种自我参与创建聊天机器人并不需要高算力的GPU就能运行。对于人们来说,在简单的硬件上DIY一个专属聊天机器人也不失趣味。
来源:Tom’s Hardware
