








智东西(公众号:zhidxcom)
编辑 | GTIC
智东西4月6日报道,在刚刚落幕的GTIC 2023中国AIGC创新峰会上,墨芯人工智能创始人兼CEO王维进行了主题为《AIGC时代,算力如何“进化”》的演讲。
AIGC与通用人工智能要发展,作为基础设施的算力必须先行。随着大模型参数日益攀升,算力需求激增,算力供需缺口巨大、费用昂贵等难题,已成为AIGC发展亟需解决的首要问题。
王维说:“单纯靠硬件难以满足指数级的算力增长需求,必须通过软硬融合。在这个方向上,稀疏计算是公认的最有潜力发展和落地的方向。”相比稠密计算,稀疏计算可以达到1-2个数量级的性能提升。
通过在176B开源大模型BLOOM上的实测,墨芯S30计算卡在仅采用中低倍稀疏率的情况下,就可以达到25tokens/每秒的生成速度,并以4张S30超过8张A100的生成速度,大幅加速推理速度。
同时,墨芯预计在5月中旬开放大模型的开发套件,可以在1700亿参数模型中实现每秒40-50tokens的推理效果,去助力各个AIGC的应用场景发展。
他认为:“大模型的快速发展,给AI芯片初创公司带来了向巨头玩家发起挑战的机会,拥有了全新的展示舞台,用颠覆式创新带来数量级性能突破。”
以下为王维的演讲实录:
大家上午好!我今天讲的是算力和模型的发展,以及算力进化的问题。
讲算力的话,我们就要先了解一下今天的算力是从哪里来的?过去算力是处在什么情况和状态下?未来,我们的算力走向何方去支持生成式AI巨大爆炸式的应用?
我们希望能量化地看待从供给侧和需求侧之间有多大的GAP,然后再看现在我们手上有什么样的手段、什么样的技术、什么样的可以融合创新的方向去寻找新的算力。
一、人类数字文明建立在半导体集成电路之上
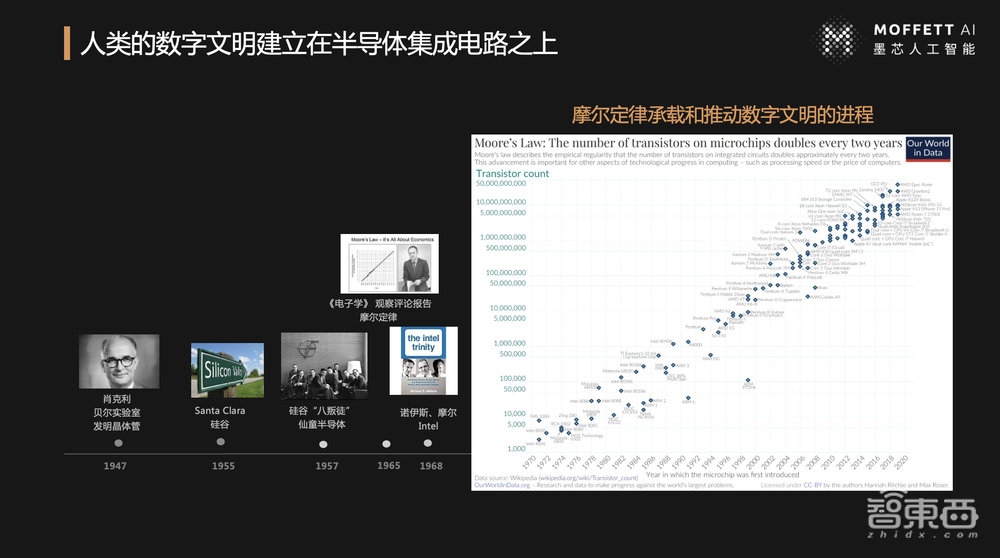
算力从哪里来?人类过去接近一个世纪的数字文明都是建立在硅基半导体制造的芯片之上。
我简单带大家回顾一下算力发展历史过程。历史上最重要的一个人是肖克利博士,他是麻省理工固体物理学博士,加入了贝尔实验室。1947年,他在贝尔实验室发明了人类第一个晶体管。1955年他回到家乡Santa Clara(圣克拉拉)。这也有很多巧合因素,为什么Santa Clara变成了现在的硅谷?为什么伟大的科学家或者商业家会从那个地方开始启蒙?
肖克利博士在圣克拉拉建立了第一家半导体公司。源于他在学术界的威望,这家公司吸引了一大批能人志士加入。但因为他是科学家,所以在管理层面上出现了一些问题。
1957年,硅谷出现了“硅谷八叛徒”,这个称号是肖克利博士对他们的称号。原因在于这八个人由于不满肖克利的管理方式而从这家公司“出逃”,创建了著名的仙童半导体。
我认为仙童半导体是集成电路发展史上开拓性或具有宗师级意义的企业,1961年仙童半导体推出第一块集成电路,把晶体管集成在硅基的集成电路上,就是集成二极管、三极管、电阻、电容,才有了集成电路的发展。
50年代到60年代间,整个半导体行业发展非常迅速,那么为什么又出来英特尔这些公司?原因在于,当时仙童半导体公司的投资人菲尔柴尔德家族占有了其绝大部分股份,把公司产品的利润和所有的资金挪到东岸其它产业方面。而在半导体产业里很有理想的工程师、科学家们对此十分不满意,1968年八叛徒中的戈登·摩尔和罗伯特·诺伊斯离开了仙童半导体,成立了今天大家熟知的英特尔。
还有一点大家可能不太熟悉的是,1969年杰里·桑德斯从仙童半导体出走,成立了今天的AMD公司,ADM的发展历史也很传奇。
后面大家都知道了,我们的计算、算力都是遵循着摩尔定律在CPU的基础上发展。
当时,摩尔提出摩尔定律的背景是,1965年,摩尔给《电子学》期刊做35周年观察家评论报告时,他发现过去这几年集成电路的发展基本每两年出一代新产品,并且每代新产品晶体管的数量翻了一番,他就在这个图上画出了著名的摩尔定律,就是今天所知的每18-24个月,晶体管的数量翻一番,或者从经济学的角度说,每过两年,每1美元可以买到的算力翻一番,成本降低一倍。
从1971年第一块4位CPU英特尔4004,1972年8位CPU 8008,再到今天熟知的大半个世纪的发展,都遵循着摩尔定律。
和我们的生活和应用场景相关的这几十年,在最早的Wintel联盟时代,英特尔提供芯片,Windows做操作系统。当时有一句话说,英特尔每两年提供算力double一下,比尔盖茨把它给用掉。再后来到移动互联网时代,边缘端手机侧和云端的云计算等算力都在不断演进。
我创立墨芯之前,曾有幸参与英特尔2012年22nm第五代酷睿处理器,一直到2019年做到英特尔第十代10nm CPU。英特尔每一代CPU里面我很骄傲地设计了这些芯片里面的核心高速链路架构设计和电路设计。
对于我个人来说很有成就感,每每想到全球每个角落、每个用户敲一个键盘、动一下鼠标,每一个字节0和1都通过我做过的电路实现,这是我人生事业一个非常大的成就。
二、AI 1.0向2.0进化,硬件层面找不到满足算力解法
刚刚回顾了一下算力发展的历程,我们仍然还是沿着摩尔定律发展,在物理层面上我们摆脱不了摩尔定律。从需求侧我们看一下发生了什么样的根本性变化。
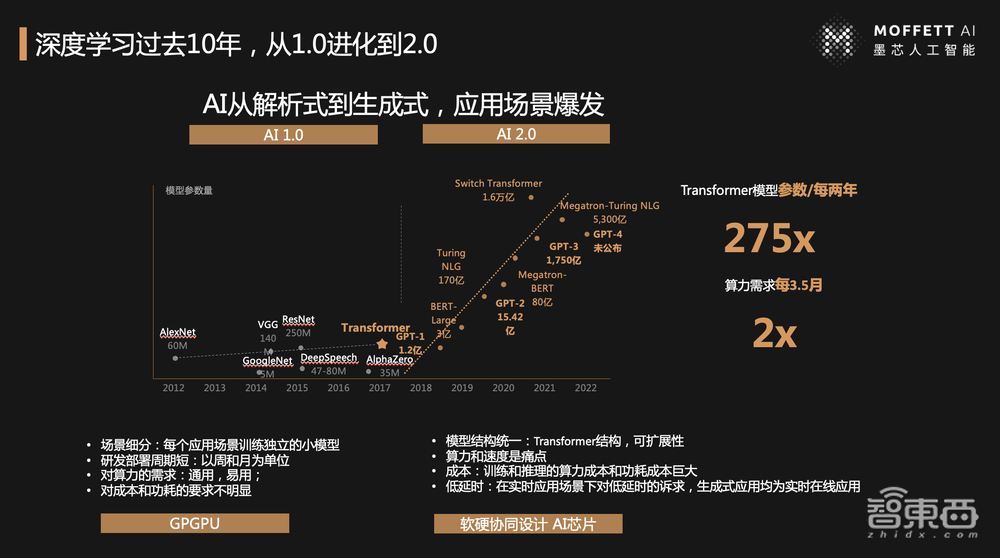
这张图大家非常熟悉,这就是过去十年AI的发展历程。我相信AlexNet是第一个深度学习非常有代表性的且开拓了深度学习的纪元,今天以GPT-3.5生成式AI作为一个爆点,可以看到AI从1.0转向2.0,之所以会引起社会这么大的关注和影响力,更多的是因为,从1.0到2.0,小模型或者之前的模型从分析式变为今天的生成式。
生成式给大家打开了应用的想象空间和大门,商业化不再被担心,唯一担心的是我如何能够赶上这个潮流,以及多快能够赶上的问题,这也是为什么今天会成为一个爆炸性的时刻。
从算法角度来看,我们把1.0时代归纳为小模型时代,2.0时代就是以Transformer为基础的大模型时代。正是因为1.0到2.0的变革,才导致对算力提出了根本性的挑战和变革。
小模型时代,有AlexNet、ResNet、CNN模型、RNN模型,这些小模型的特点是,在每个细分场景会用场景数据去训练小模型,并且研发和部署的周期很短,是以周和月为单位去部署,对算力的要求更多是通用性和易用性,在这个基础上其实对成本、功耗的要求在大部分应用场景下不是痛点,是痒点而已。
原因在于,英伟达GPU平台可以做矢量和张量并行计算,它很早做了CUDA工具包,对科学计算到底层并行架构在软件链路的积累,使得这一平台很好用且通用。所以在小模型时代,大家会更多选用GPGPU。
但是回到大模型时代,对算力的需求完全不一样。模型结构不再多样化,我们通过Transformer做大模型预训练,所有的模型结构统一化,对算力的需求更多在于扩展性。从GPT-1到GPT-3、GPT-4,Transformer模型需要“暴力出奇迹”。
ChatGPT应该是在训练方面找到了更聪明的方法,使得它在生成式上产生突破。但从模型角度来说,仍然是暴力出奇迹。其实所有的深度学习都是特征提取器,当你学的东西越多,你就需要更大的空间矩阵、张量空间承载信息,所以它的模型是暴力增长。
预训练正是因为需要它先把所有东西学一遍,再到细分场景上精调,因此算力需求不仅仅看中通用性、易用性,更看重的是算力能不能跟上模型的增长速度、跟上算力需求速度,使得我可以更大规模拓展模型,用更先进、更聪明的方法训练出更厉害的预训练模型或者场景应用等。
总的计算算力增长和在应用层面上的推理速度就变成了绝对的痛点。而又因为生成式AI基本上都是在线应用,所以系统的反应速度一定是痛点。训练层面上,需要很多GPU,训练很长时间,那么高算力也一定是痛点。
这种情况下,通用性问题就可以被容忍。因为底层都是Transformer架构的注意力机制,在模型的算子层面慢慢固化,这个就是我们算力的需求在发生变化。
那么,提供算力的人怎么去满足它?我们可以看到Transformer模型参数每两年增长275倍,对算力的需求是每3.5个月翻一番。而摩尔定律是每两年翻一番,参数是275倍和2倍的增长速度,这中间是两个数量级的GAP。
所以,仅从硬件层面上,我们找不到完美的答案。
现在解决这个痛点的手段包括做存内计算、光子计算、量子计算等。存内计算的局限性在于它很难做浮点高精度计算,不支持先进制程,使得其应用距离解决目前的问题还有很大差距。光子、量子计算的生态体系和现有的软硬件生态也有很大距离。我承认,它们在实验室里有很大发展前景,但未来五到十年内仍需要依靠硅基半导体。
三、在算法里找“聪明办法”,稀疏计算最具潜力
软硬融合就是在算法方面寻找更聪明算力的一大方法,软硬融合的稀疏计算就是整个业界、学术界公认的最有发展潜力,并且可以落地的方向。
借用模型的增长曲线,图中橘黄色的线是整个产业界、学术界发表的稀疏计算研究论文数量。
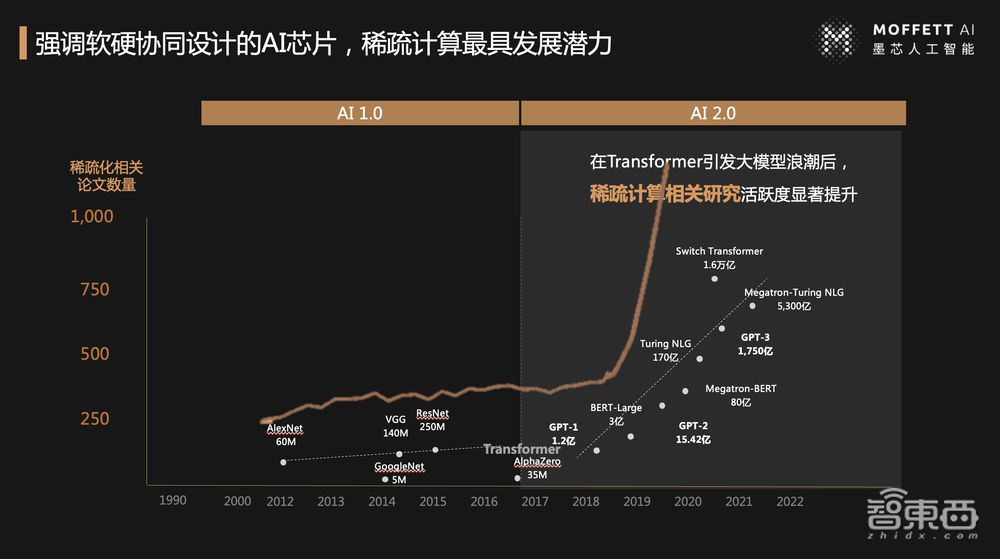
大家可以发现在小模型时代GPU很好用,并行化加速、成本、速度都可以被企业接受。因此,这一时期对于稀疏计算的研究更多是在算法层,而突然到了大模型指数级增长时代,大家发现,大规模矩阵张量运算中有很多稀疏特性,不能再暴力把零元素、噪音元素都进行计算,我们需要做更聪明地计算,只计算真正有用的计算,这也正是稀疏计算的本质。
最近在学术界以及产业界的头部公司,比如最近混合专家模型MoE架构就是用了稀疏计算思路,不需要每次都激活所有的专家子模型,只会在通过某些通道的时候激活有必要的专家子模块,这样的话,在有限的算力情况下模型还可以继续拓展。这是稀疏计算的核心思路之一。
最近谷歌和OpenAI同时发布了一篇论文,该论文比较了稠密计算和稀疏计算的性能和加速,稠密计算的模型计算速度能在CPU上跑到3.61秒。
如果以稠密计算作为基准的话,把所有的Transformer大模型每一层,如FF、QKV和loss全部都用等效稀疏计算的话,稀疏计算可以提升37倍。也就是说,真正有效的计算通过稀疏计算可以达到一到两个数量级的性能提升,这也向我们展示了稀疏性确实存在于模型里面,关键的问题是你能不能找到它,要用什么样的方法实现它。
2018年,我在硅谷创立墨芯,2019年回到深圳的时候,最开始我们就看到了稀疏性,并且看到了它一个数量级、两个数量级上的性能增长空间,我们这三四年来也一直笃定坚持做稀疏计算平台。
微创新技术是大公司做的事情,以非常高成本的Chiplet为例,它是在硬件层面解决倍数问题,而不是解决数量级问题的技术。创业公司要做的是要看到数量级增长的技术空间,只要你笃定地去做,即使前面难一点,但只有这样,未来的空间才能突破、才没有上限。
四、以人脑为灵感,稀疏计算已成产学界重点研究方向
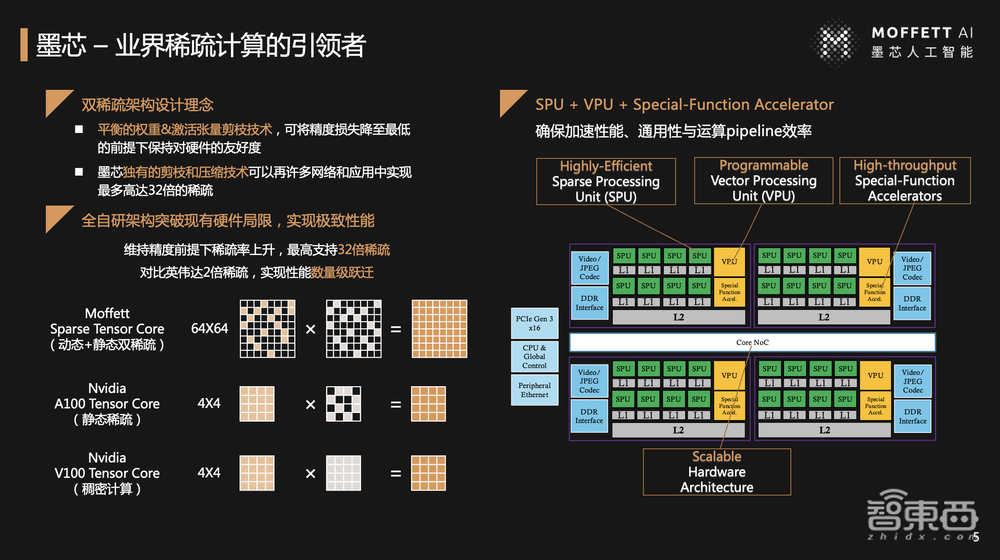
对于墨芯来说,作为业界稀疏计算的引领者,我们做了什么事情?所谓的稀疏计算到底是什么意思?我们的AI芯片和英伟达的GPGPU有什么区别?
英伟达基于V100的Tensor Core GPU是4×4矩阵并行加速单元,通过几万个、十几万个并行单元去加速矩阵运算、张量运算等。
之后,英伟达也同样知道模型有稀疏性,稀疏是未来。到了A100的时候,英伟达在原有架构基础之上,在模型矩阵层做了4拖2,也就是说4个里面有2个加速,理论上就可以加速一倍。
对于GPGPU公司,稀疏计算是它们的“意外收获”,可以在原有性能上提升一倍,但墨芯要做的事是超过它10倍甚至100倍。
墨芯采用的Sparse Tensor Core是64×64的矩阵空间,2个Tensor矩阵空间里均支持高达32倍的稀疏率。2个矩阵空间分别代表计算模型层的矩阵空间和激活层、神经元层的矩阵空间。
在模型层,并不是所有的矩阵里都是有用的元素,当我们把这么多有用的信息提取出来放到一个巨大的矩阵空间里,它的表现形式就是滤波器,滤波器之间的距离就是表示特征之间的特性。所以这个巨大的矩阵空间是稀疏的,随着模型越大、学的东西越多、特征区别越细粒度时,模型按指数级增长,稀疏率也会按指数级或者更高的速度增长,这就是模型稀疏。
激活稀疏,我们的大脑学习、理解都是激活稀疏,人有百亿级神经原,大脑的功耗只有几十瓦左右,当我们处理不同的事情、思考不同问题时,对眼睛、耳朵反应激活的神经原层面不一样,只有局部激活。包括混合专家模式也是一样的,对于不同模态、不同专家系统只需要激活部分模块。这就是墨芯底层的张量和支持大规模稀疏的矩阵和矩阵并行加速。
五、12nm VS 4nm,墨芯S30性能是英伟达H100 1.2倍
那么,稀疏计算在效果上到底怎么样?
我们研发了三年,2022年初墨芯第一颗高稀疏率的稀疏计算芯片Antoum流片成功回片,而且在几秒钟之内就点亮,不到24小时跑通了ResNet、BERT。
基于Antoum芯片,我们制作出了三款AI加速卡S4、S10、S30。因为墨芯的客户是云计算客户,不是直接用芯片,而是需要用GPU这样的AI加速卡。

国际上最权威、影响力最大的AI基准测试性能平台MLPerf,是由图灵奖得主大卫·帕特森联合谷歌、斯坦福、哈佛大学顶尖学术机构,还有英伟达、英特尔、微软云、谷歌云等发起成立,这一平台每年有两次性能的评比和提交。
去年8月,墨芯带着第一款S30在MLPerf 2.1推理性能上与其他产品上台竞技,结果是基于12nm的S30单卡算力超越英伟达4nm的H100,ResNet性能是它的1.2倍。12nm VS 4nm,在工艺上墨芯落后英伟达三代,中间还有10nm、7nm,除此以外,H100采用SXM模式,是700瓦大芯片,不是PCIe板卡。墨芯的S30不到300瓦。也就是说墨芯的工艺落后英伟达三代,功耗接近其1/3,但性能可以做到1.2倍。

如果大家说你只是做一个CNN模型,Transformer怎么样?墨芯的BERT-Large做到单芯片超3800 SPS,仅次于英伟达H100,H100大概为7000、8000 SPS左右。
不过,墨芯仍然超过了现在经常断供、缺货的A100。墨芯在BERT的性能上是A100的2倍。在BERT上输给H100的原因是,H100加入了新的数据类型FP8,但墨芯的第一代芯片只支持FP16。如果我们的下一代芯片支持FP8,那我们的性能也会翻倍,这样性能就和H100差不多,这些都是我们看得见的可以实现的优化,只不过是什么时候可以实现的时间问题。
六、“稀疏计算方向是对的!”,推理效果超A100
正是由于MLPerf的打榜,给行业揭示了一件事情,软硬件设计的稀疏计算潜力有多大,三代半导体工艺的差距,性能差距会达到八倍,三个数量级,同时功耗会是它的1/3,简单乘一下那就是24倍。
如果我也做4nm、做700瓦的功耗,那这个性能就会再往上提20倍。
我们默默无闻做这一件事做了三四年,就是想告诉大家,这个是对的方向。大模型时代到来,就是我们开始发挥的时候。
之前,你的客户可能会问,通用性怎么样?算子支持度怎么样?易用性怎么样?当然,我们任何一家AI芯片公司在生态上都无法和英伟达匹敌,但是今天我们走上了快车道。大模型的发展和算法的发展速度,给了今天的AI芯片公司一个全新的舞台和展示机会,使得它们可以在一个更高的维度上和过去的霸主进行竞争和挑战。
在大模型领域的实践和突破中,我们拿不到ChatGPT的模型参数,因此我们选用了学术界最知名的BLOOM开源库,176B的开源大模型。

在这样一个开源模型下,墨芯目前做到的推理效果是在中低稀疏倍率下,同样是176B大模型,用4卡的S30对标英伟达8卡的A100。
生成式AI对于时延的要求非常高,因为它需要一个一个token去算,因此对速度的要求是未来大模型上线的第一个痛点,也是最明显的痛点。
墨芯测试时1700亿的参数模型,A100每秒可以产生20左右个token。因为墨芯做了模型压缩,因此墨芯在实验室使用4卡,不需要用8卡,其可以做到稍微比A100好一点的性能,也就是每秒钟25个token。不过,我们的目标是在1700模型中做到每秒50个token。大家作为开发者的话,可以知道这个性能和速度已经到了极致。
七、5月中旬开放开发套件,坚持“科技向善”
大家很关心的一件事情就是什么时候可以试?我们预计在5月中旬去释放大模型的开发套件,在1700亿参数模型中做到40-50token/秒,去助力各个AIGC的应用场景发展。
我们作为一个科技工作者,看到生成式AI和AGI到来的突然性和其未来的进化速度,不禁让我们既兴奋又惊恐。
我拿人的大脑和ChatGPT做一个类比,ChatGPT是1750亿参数,对应人的大脑是千亿级的神经原,神经原之间的连接关系Synapse是100万亿。如果对应深度学习模型,我们需要拿连接关系和它的模型参数做比较,1700亿到100万亿,中间相差三个数量级,也就是至少差1000倍。
人脑的计算速度大概是硅芯片计算速度的1/1000,差三个数量级,人脑耗电大概在20瓦左右,数据中心千瓦级。我们会遐想,看到AI在知识领域的进化速度,人类能够超越或者不被机器取代的领域已经非常少了。
前两天我看到一个非常有意思的漫画,以前我招一个人给他配一台电脑,今天我招一台AI电脑给它配一个人,这个就是我们对于未来的担忧。
考虑到算法进化速度,当然前提是你有多少算力,因此我们是参与其中的。
如果今天的AI模型从1700亿进化到100万亿,和大脑相当的时候,它的计算速度是我的1000倍,同时也是稀疏计算的时候,并且当我们的训练方法越来越聪明,我们在知识领域能干的事还会剩下多少?最恐怖的是,如果我们新的训练方法使得它有了自我的进化意识,这会让我们非常担忧。
作为AI前沿浪潮的参与者,我们都在关心一件事情,不仅仅是技术,更是AI发展的伦理、法治和道德层面。
所以,我在公司成立的时候就想好了这件事情,墨芯的使命和价值观一定是科技向善、照顾弱小、利他利社会。
你可以想象,如果未来我们的社会掌握在一小群极致聪明的人手上,我们的生活被他们照顾,甚至我们的下一代的教育,这也是我非常担心的问题,以后孩子们要学哪些东西?尤其应试教育比较多的方面,以后人要往哪方面发展?
最后,回到这个基础之上,微软说要做负责任的AI,保证安全性、可控性,这也是OpenAI不开源大模型的原因之一。谷歌的口号是“我们不作恶”。
墨芯的口号是“科技向善”,我们去赋能和支持AI的发展,但是一定要做善事,把技术应用于善待人类、照顾人类。有一段时间我们自嘲地说,AI芯片就是类似于这场AI战争的“军火商”,“军火商”大部分是贬义,这也迫使我们去确立我们的使命和价值观,也就是只能把“军火”用在做善事上。
墨芯是一家稀疏计算公司,我们开拓和引领稀疏计算,谢谢大家!
以上是王维演讲内容的完整整理。
