








智东西(公众号:zhidxcom)
编译 | 吴菲凝
编辑 | 李水青
智东西4月6日消息,根据Meta官方博客,Meta在本周三推出了一个AI模型Segment Anything Model(SAM,分割一切模型),能够根据文本指令等方式实现图像分割,而且万物皆可识别和一键抠图。
 ▲Meta AI在推特宣布发布SAM模型
▲Meta AI在推特宣布发布SAM模型
Meta在博客中称,SAM的灵活性在图像分割领域内属首创,SAM以交互式方式标注一个掩码(mask)仅需约14秒。英伟达AI研究科学家Jim Fan称,该模型的发布是计算机视觉领域的“GPT-3时刻”,因为该模型能对从未训练过的图片进行精准分割。在推出SAM的同时,Meta还发布了一个图像注释数据集Segment Anything 1-Billion mask(SA-1B),该数据集包含超11亿个掩码,据称是同类数据集中最大的。
目前,Meta内部已经在使用SAM技术来进行标记照片、审核内容以及向Facebook和Instagram用户推荐内容等,同时更多在VR/AR、智慧农业等领域的颠覆性应用畅想也在官网展示了出来。
Meta研发团队在官网上发布了关于Segment Anything的论文细节。
论文链接:
https://ai.facebook.com/research/publications/segment-anything/
一、鼠标停留、手动框选、自动分割,三种方式实现图像切割
SAM可以识别图像和视频中的任何物体,即使是在此前的训练过程中从未遇到过的。Meta官网中提供了SAM的免费演示,并为用户提供了三种分割图像部分的方法:
一是“悬停和点击(Hover&Click)”,当用户把鼠标放在想要分割出的部分上并点击时,SAM会自动提取出该部分。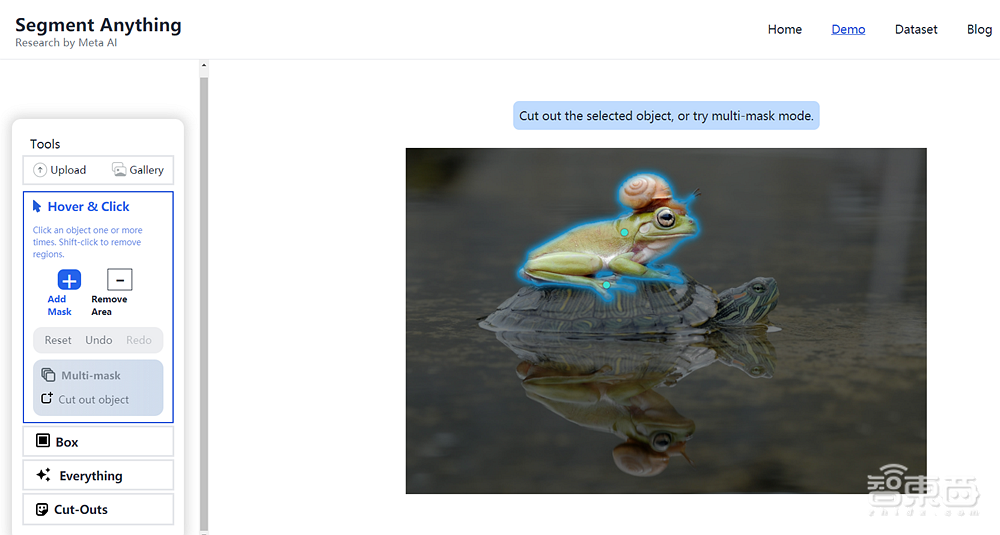
二是“方框(Boxing)”,用户将自己想要的部分框定出来,SAM会识别其中的物体并将其与背景进行分割。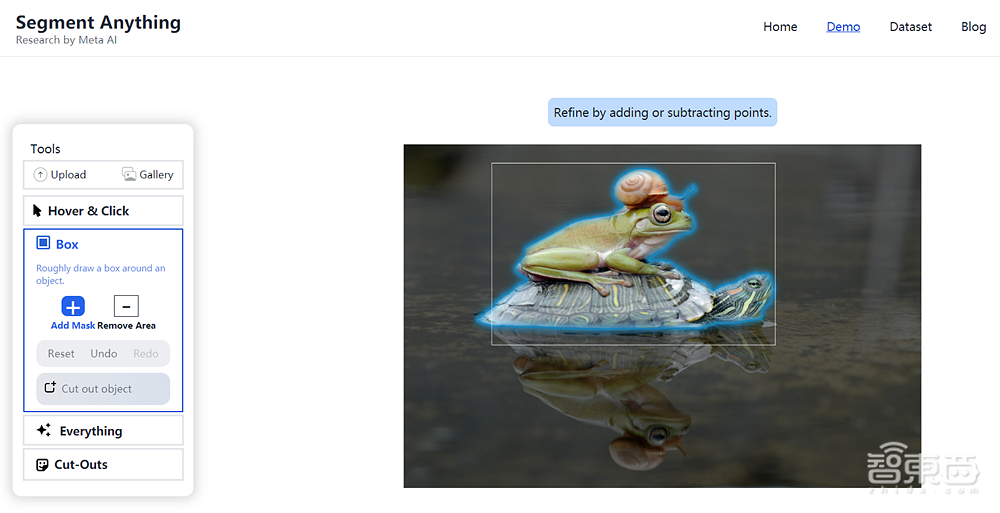
三是“全选(Everything)”,在这种模式下SAM会自动识别图像内的所有物体。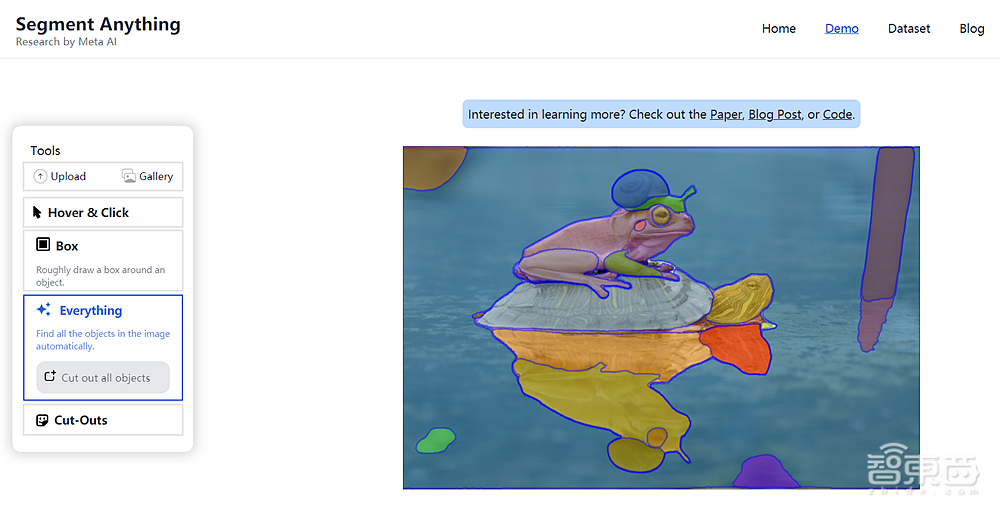
虽然还没有发布产品,但Meta已展示了SAM的部分功能,目前官网介绍的功能包括:用交互点式和手动框定来选择物体;
SAM自动分割图像中的所有内容;
自动给不明确的提示生成多个valid mask(有效掩码),让用户能精准选中图像;
此外,SAM还可与其它系统灵活集成,从其它系统中获取输入提示,比如,从AR/VR头显中获取用户的视线范围来选择对象,甚至还能将看到的物体转换成为3D对象。
SAM还能启用文本框输入来检测界定对象,当用户在文本框中输入“cat(猫)”这个单词时,SAM会框定住图像中所有的猫,并在框中精确选取猫的整个图像轮廓。
SAM的有效输出掩码(valid mask)还可以用作其他AI系统的输入,如当用户选中一张椅子的图片后,SAM可以精确选中,并在视频中跟踪物体遮罩,自动启用图像编辑应用程序,把静态物体转化为3D或是碎片拼贴等状态。
二、领域内首创:由1000万张图片训练,可提取11亿+掩码
在自然语言处理和计算机视觉领域,基础模型是其发展的重要基础,基础模型可以使用“prompting(促进)”技术对新数据集和任务执行零样本和少样本学习。Meta从中汲取了灵感,并对SAM模型进行训练。
在Meta发布一篇论文中,研发团队人员详细介绍了SAM的相关细节。
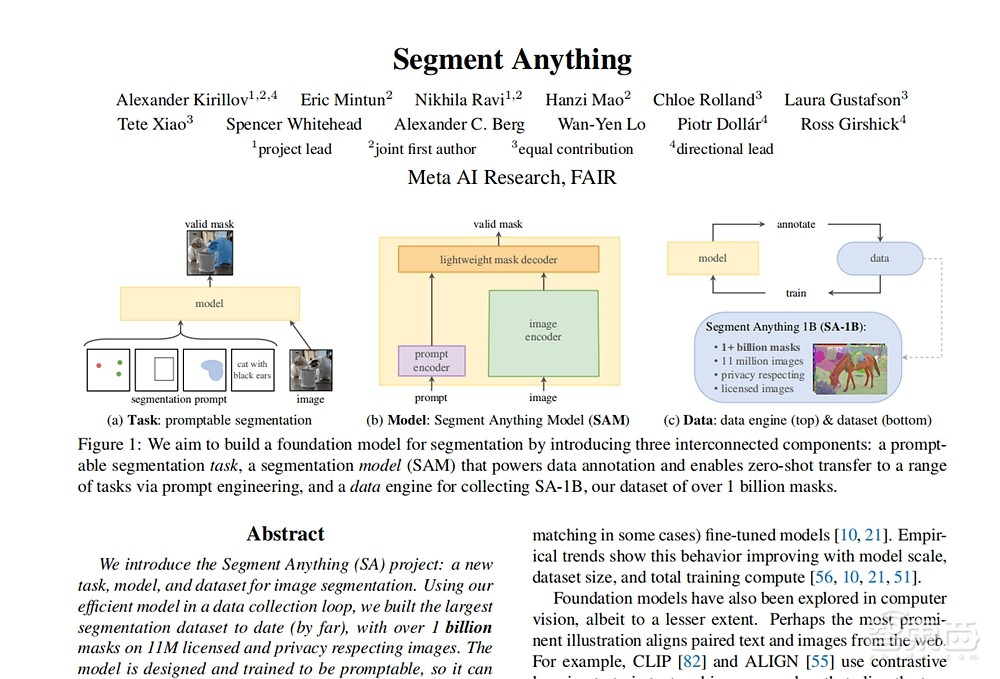
 ▲基础分割模型的三个关联组件
▲基础分割模型的三个关联组件
常见的图像分割方式包括两种,一是交互式分割,二是自动分割。前者需要工程师通过迭代完善一个遮罩来指导模型,后者是模型在经过数百或数千个注释对象的训练后自行完成,但同样需要训练者手动标注分割对象。
这两种方法都无法实现全自动的图像分割,而SAM将二者的功能进行融合。在模型的提示界面上,用户只需要为模型提供正确的提示,比如点击、框选或是文本指令,模型就可以完成全自动的图像分割任务。这就意味着,用户不再需要收集自己的细分数据来微调模型。
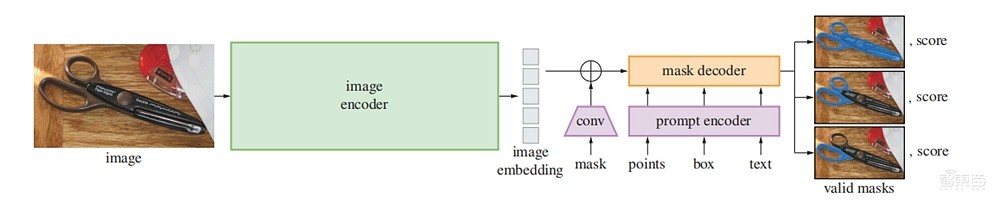
 ▲在Web浏览器中,SAM有效映射图像特征和一组提示嵌入来生成分割掩码
▲在Web浏览器中,SAM有效映射图像特征和一组提示嵌入来生成分割掩码
在引擎盖下,轻量级编码器将任何提示实时转换为嵌入向量(embedding vector),然后将信息源组合在一个预测分割掩码的轻量级解码器中。在计算图像嵌入后,SAM 50毫秒内就能根据网络浏览器中的任何提示生成一个切割好的图像。
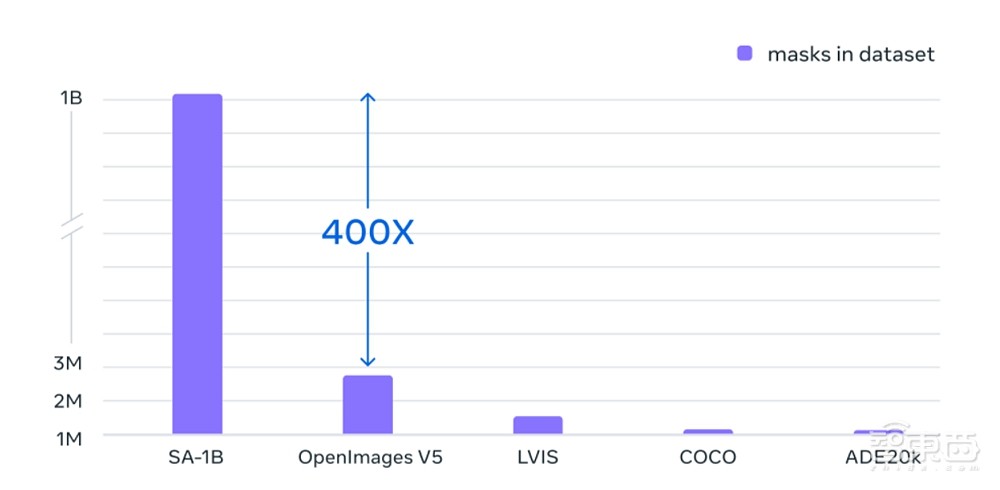
论文中称,SAM能根据输入提示为图像中所有对象生成高质量的对象掩码(mask),用于训练SAM的SA-1B图像数据集目前包含超过11亿个掩码,这些掩码是从1100万张已经获得许可、并且保护隐私的高分辨率图像中收集的,这些图像的分辨率达到了1500×2250 pixels,平均每张图像约有100个掩码。
 ▲原始图片和SAM提取的图像进行对比
▲原始图片和SAM提取的图像进行对比
Meta在论文中指出,有了SAM模型,收集新分割掩码的速度远超以往,交互式标注一个掩码现在只需要约14秒。其数据集数量也是现在任何一个数据集的400倍。这种高自动化、高灵活性的图像分割技术为领域内首创。
三、CV领域的“GPT-3时刻”,或变革VR/AR
Meta官方称,通过在业内共享这项研究和数据集,公司希望进一步加速对分割图像视频的研究。这款可提示分割模型可以作为更大系统中的组件来执行分割任务。Meta预计,SAM或将成为AR/VR、内容创作等领域的强大组件之一,有望创造出更为通用的AI系统。
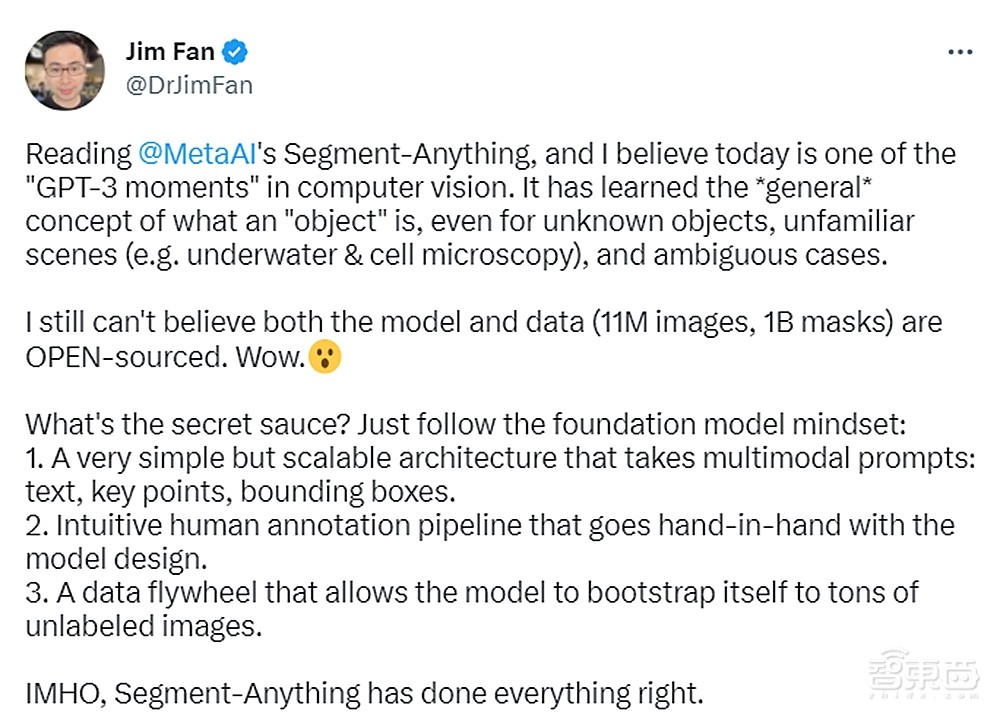
英伟达AI研究科学家Jim Fan称“今天是计算机视觉领域的‘GPT-3 时刻’之一”,SAM已经了解了“对象”的概念,甚至对于不熟悉乃至未知的场景和那些模棱两可的情况,它都能进行切割。Jim称难以想象它的模型和数据居然都是开源的。
他指出了SAM的秘诀:
1、一个非常简单但可扩展的架构,采用文本、关键点、边框等多种提示模式;
2、与模型设计密切相关的人工操作渠道;
3、一个数据飞轮,允许模型自主学习那些未标记的图像。
扎克伯格称,将这种生成式AI作为“创意辅助工具”纳入到Meta的应用程序中是今年工作目标的重中之重。
目前,SAM模型和数据集仅在非商用许可下提供下载,用户在将自己的图片上传到原型上时,必须承诺不将其用作研究。
未来,SAM可用于通过AR眼镜识别日常物品,向用户发出提醒和指示。
SAM也将对其他领域产生影响,比如指导农民进行粮食生产或协助生物学家进行研究等。
结语:图像分割再进化,Meta掀起CV革命?
图像分割技术并非是新鲜事,但SAM能识别出训练数据集中不存在的物体,或许将会引发新一轮AI视觉应用潮。未来,Meta通过分享他们的研究和数据集,将会使这类组合系统设计在多个领域得到广泛应用。SAM将会是内容创作、图像生成等更为普遍的AI领域的一个强大组件,让图像识别和视觉内容的语义理解之间更好耦合,释放出更强大的AI潜力。
来源:Meta官方、路透社
