








智东西(公众号:zhidxcom)
编辑 | GTIC
智东西4月18日报道,在刚刚落幕的GTIC 2023中国AIGC创新峰会上,云知声联合创始人兼副总裁李霄寒带来了名为《从理解到生成,云知声的AGI之路》的主题演讲。
李霄寒通过回顾过去近30年AI的发展历程,总结出了AI演进3点规律。首先,AI的演进从以算法为中心逐步变为以模型为中心,这将影响科技企业未来在相关资源上的投入比例;其次,AI项目逐渐从小而美的工程变为一项大工程,如果一家科技企业过去没有AI相关的积累,而未来又没有大规模的投入的话,那么发展起来是非常困难的;最后,AI在解决复杂任务时,将通过端到端的方式,中间任务将面临凋零。
李霄寒认为,ChatGPT的推出,对当下AI技术路线、社会分工以及AI企业发展产生深远影响。在技术路线层面上,此前,虽然国内外的许多家科技企业认为实现通用人工智能(AGI)需要一个“线性输入——线性输出”的过程,但是这家企业对这条路径信心不足。ChatGPT验证了这条路径的可行性,即只要持续地线性投入,那么当模型参数达到一定规模时,就可能出现涌现效应。
在社会分工层面,李霄寒指出,未来从事文稿撰写、客服、儿童成长陪伴师这样的岗位将会被淘汰,因为这些岗位实际上只是在做一些简单的输入输出工作。在AI企业发展上,李霄寒展望了未来两种不同模式下的AI企业生态。其中一种是基于通用大模型的公司,它们通过通用大模型底座对外提供服务,从而获取规模性的用户,另一种是基于垂直场景大模型提供精细化服务的公司,这种公司的大模型可能达到几百亿参数的规模。
最后,李霄寒分析了ChatGPT的进步性以及局限性所在。他认为,ChatGPT的出现,让AI真正进入了CGG时代。这不仅体现在人类有机会告别人工智障,还体现在AGI有望成为现实。但ChatGPT目前生成的信息并不完全准确,同时知识更新和自动化的程度不够。
以下为李霄寒的演讲实录:
非常荣幸有机会来跟大家做一下分享,云知声是一家AI公司,也是这波ChatGPT的浪潮下最受关注的公司类型之一。大家纷纷关心我们这种AI公司在想什么、做什么。同时,也有人在问,这波浪潮会对AI公司有什么影响?AI公司将如何破局?
简单来讲,云知声是一家垂直类的AI公司,它有两方面业务,分别是智慧物联和智慧医疗。近期我们会推出医疗版的预训练大模型,因为这件事情还正在进行中,所以我今天没有太多关于这件事情的分享。我还是更多讲一下关于AI从业者、AI公司如何看待最近这波ChatGPT浪潮。我们可以从中总结一些规律、展望一下未来,同时看一下这波浪潮将会带来哪些机会,以及存在哪些风险。
一、AI历史回顾与3大规律总结
首先,我们来回顾一下,AI在过去近三十年间的重大事件。自我从业以来,云知声整个创始团队碰到的第一个、也是最重大的事件就是,1997年,IBM开发的象棋电脑,也就是我们熟知的深蓝计算机击败了世界围棋冠军卡斯帕罗(Гарри Кимович Каспаров)。
2012年,AlexNet横扫ImageNet的榜单,让人认识到深度神经网络的力量,那一年,云知声把深度神经网络应用在语音方面,并且达到了当时普通话的最佳水平。
2016年,AlphaGo打破人类围棋不可战胜的神话,在那一年,云知声完成了过去几年比较基础的技术积累,并且在那个时间点形成了一直延续至今并且还在不断发展壮大的两大业务——智慧物联和智慧医疗。
最近OpenAI推出了ChatGPT,一方面,我们感受到了巨大的压力,另一方面,我们也感到非常欣喜——从业这么多年,终于有机会真正看到AGI在未来几年成为现实。所以云知声也积极地融入到整个大模型浪潮之中。
回顾历史,我总结了AI演进的3点规律。首先,AI的演进将从以算法为中心逐步变到以模型为中心。早些年的专家系统基本上都是规则。上世纪90年代,统计学习模型兴盛以后,模型逐步开始占比较大的比重,拿典型的语言识别关键词检测任务来讲,原代码的大小和模型大小基本在同一个量级,现在看来像一个玩具。而随着深度学习模型的引入以及到最近预训练模型引入,整个模型占的比重越来越大,这就导致我们的投入——资源、人力、硬件以及比例跟过去相比完全不一样。
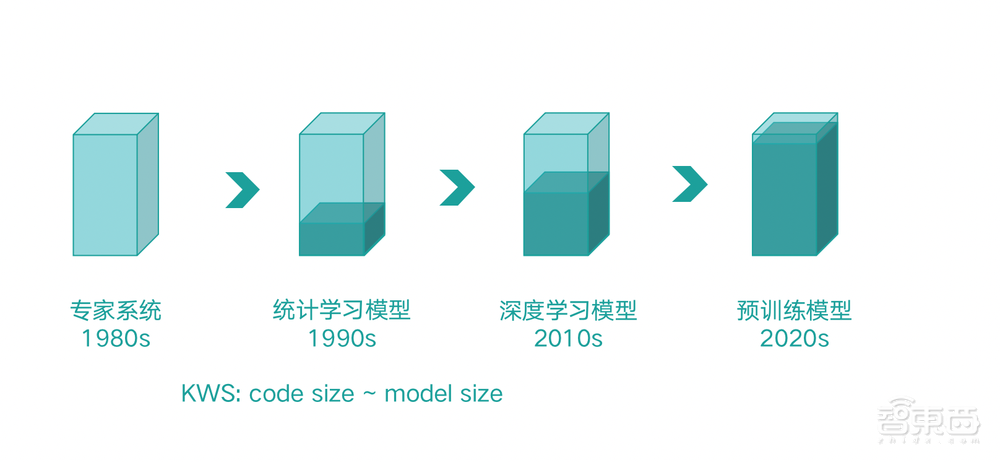
第二个规律,AI项目逐渐从小而美的工程变成大工程。在过去的5年或者10年前,一家企业找几个人搭一个班子,买一些服务器数据就可以做出一个AI产品,这个AI产品可以面向某个特定场景解决一些特定问题。

在未来,这件事情将会变得不可行。AI真正变成一个大工程。虽然还会有人想找一个非常小的领域去做AI,但是问题是,当这个大模型解决完所有通用的问题之后,只需要在上面延伸出一个垂直就可以把原来辛辛苦苦做的东西颠覆掉。现在,一家企业如果在AI领域没有一定的积累,未来又没有大规模投入的话,那么发展AI还是比较困难的。
第三个规律,就是中间任务的凋零。过去AI解决一个复杂问题的时候,会把这个任务划分成一系列子任务,然后再把它们串起来。这样一来,前一个子任务的输出可能只是为了下一个子任务的输入,这是所谓的中间任务。
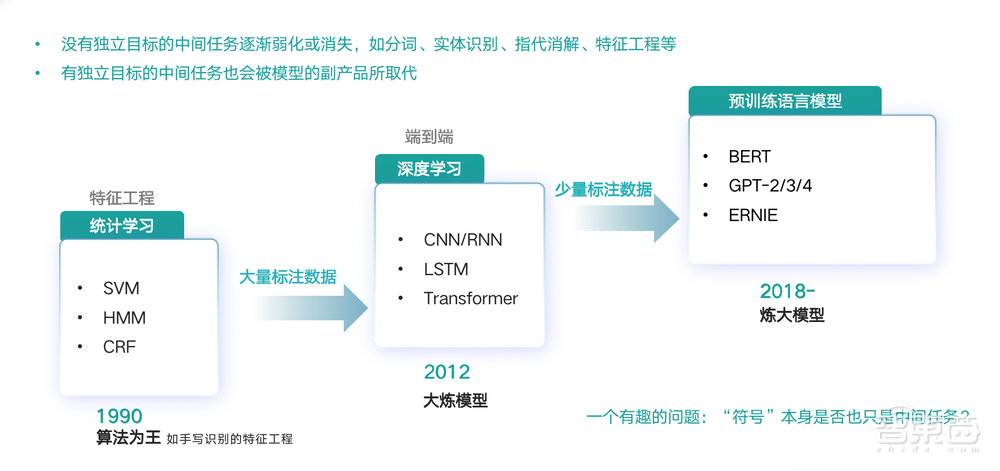
2000年前后,手写识别功能特别流行。当用户在手机上用手写输入,AI就可以从一张原始图片里面提取出相应的特征,然后再将这个特征输入到后面的分类器中从而实现手写输入的功能。但现在,大家都是通过端到端的方式来实现,未来人们将用大模型来实现。这种中间任务慢慢就没有人做了,或者说,这种中间任务没有存在的意义了。类似的中间任务里面还有NLP里面的分词、指代识别等等,这些都将被弱化或者消失。
这里面也延伸出一个有趣的问题。ChatGPT输入、输出都是文字,其实文字本身是人类对整个物理世界翻译以后形成的符号系统。这种符号系统仍然被看作是一项中间任务,那么ChatGPT这种文字类的输入输出是不是也只是一种中间任务呢?这是一个开放性话题,还有待大家的讨论。
二、ChatGPT对当下技术路线、社会分工、AI企业之影响
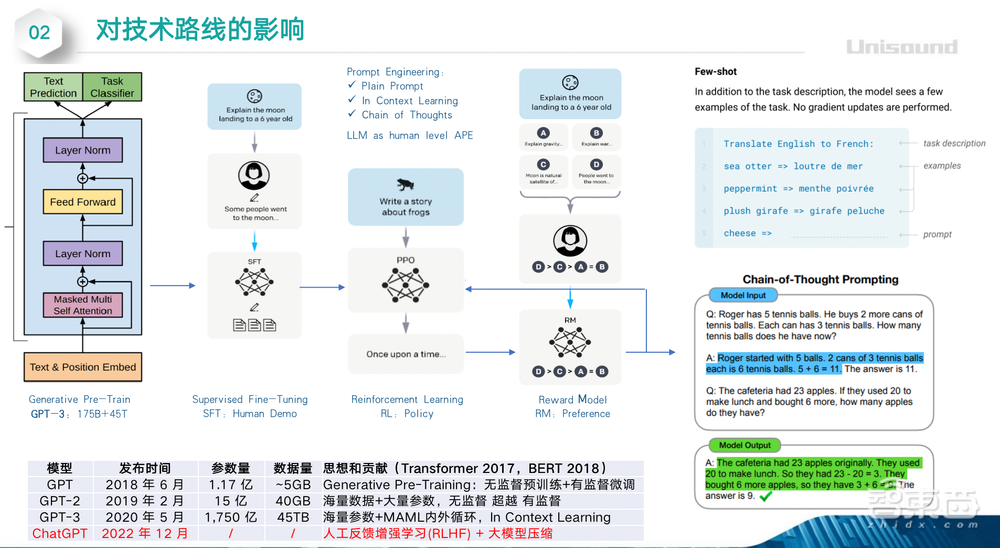
事实上,ChatGPT还对当下AI的技术路线、社会分工以及AI企业发展产生重要影响。首先,从对技术路线的影响上来看,2022年及以前,国内的AI公司或者大厂都在做大模型,但是可能各家公司可能没有那么强的信心。ChatGPT对国内的最大影响,就是验证了这条路的可行性,告诉各家公司:只要你线性持续投入,模型参数达到一定规模就会获得涌现效应,实现非线性的、爆炸式的输出。它让所有人相信大模型是AGI的必经之路。
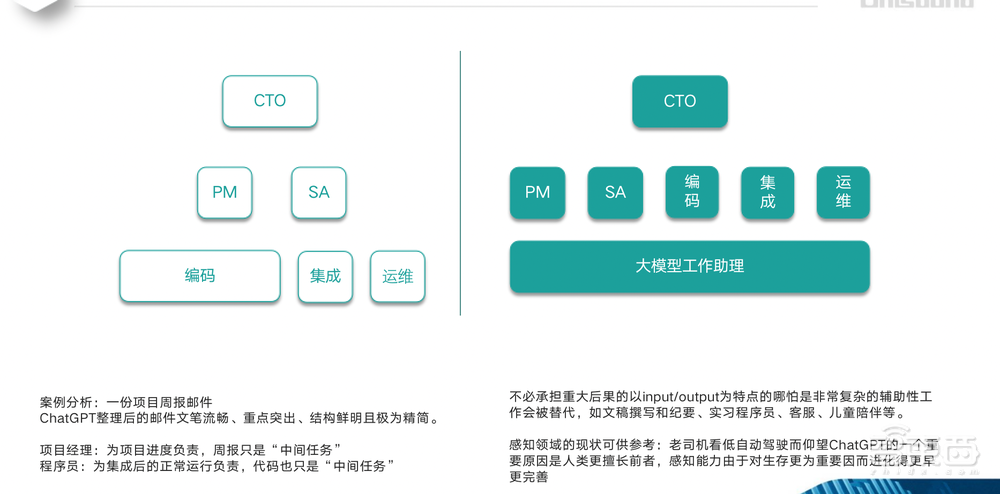
在社会分工层面,我们将项目经理提交的有关项目进度的一封邮件交给ChatGPT重新组织一下,我发现:组织以后的文本文笔特别流畅、精简、结构鲜明,而且重点突出、没有废话。对比来看,项目经理提交的项目进度书中废话还是蛮多的。这就让我自然而然地产生一个问题:项目经理这样的角色未来在我们的公司是不是还会存在?
我的思路是,要看他为什么负责。我认为,项目经理应该为项目的进度负责,并不是为周报负责,周报只是一个中间任务,被替代掉没有关系。大模型的输出这种功能可能最终会去服务于项目经理,而不是替代项目经理。
当下,“程序员被替代”的消息频频引爆互联网。我对程序员的看法与对项目经理的看法相同。程序员并不是为输出代码负责,他负责的是功能的正常集成,以及集成后的正常运行,他为debug(计算机排除故障)负责,而所谓代码只是一种中间任务。
未来,云知声的开发体系里,产品经理、项目经理、架构师、编码、集成、运维等等,每个人都将获得大模型的辅助。同时,我认为,未来从事文稿撰写、客服、儿童成长陪伴师这样的岗位将会被淘汰,因为这些岗位实际上只是在做一些简单的输入输出工作。
在AI企业发展上,我认为,未来将会有两种不同模式下的AI企业生态。其中一种是基于通用大模型的公司,它们通过通用大模型底座对外提供服务,从而获取规模性的用户。除此之外,由于这种服务的成本会较低,最后它的售价也会非常低。
另一种是基于垂直场景大模型提供精细化服务的公司,我坚信,通用的大模型并不能解决垂直领域的所有问题,哪怕它在技术上解决掉,在真正的应用过程中,还会有很多行业壁垒。所以云知声希望成为这种基于垂直场景大模型提供精细化服务的公司。但目前,云知声还没有那么大参数规模的模型,一开始的时候,云知声的大模型可能不会到千亿参数级别,但一定会在百亿参数级别,那样也将会有涌现效应存在。
三、理性分析:ChatGPT的进步与局限
下面,我将简单谈一下ChatGPT的进步性与局限性所在。ChatGPT的出现,让AI真正进入了CGG时代。所谓CGG,第一个指的是会话式AI,ChatGPT让我们有机会告别人工智障,这给我们带来了非常大的兴奋点。

第二个是生成式AI,语音、文字、图像,视频皆可生成;第三个就是AGI,我们将有幸看到,AGI在未来几年真正成为现实,然后从这个时间点往后,巨量的投资也好,或者AI企业的人员投入也好,都会集中在AGI层面。
ChatGPT当然也存在一些局限,我们关注这些局限不是为了挑毛病,而是去反思在我们所从事的领域如何解决这些问题,避免这些问题。
第一是“幻觉”,就是所谓的一本正经地胡说八道;第二是知识更新的速度和自动化的程度,当我们去做垂直场景的时候,存在大量的行业知识,这些行业知识在不断地产出,我们也需要迅速地吸收,让它被搜索到,另外在To B场景中,我们需要赋予客户本身一定的能力,让其能够自己“灌知识”,而不是所有事情都依赖服务公司;第三是推理资源的微型化,也就是私有化;第四是伦理和价值观的问题,这个问题通过前置或者后置审查,相对可控。
最后是ChatGPT学习及处理的仅仅是人类世界从现实世界翻译来的符号化知识,缺乏与物理世界的互动。这个问题是相对比较长远的一个方向,但它也是我们解决上述问题之后,必须面临的下一个问题。
四、云知声的AGI路径展望
云知声于2012年成立,公司拥有自研的技术架构,包括自建的超算中心、全栈式算法,以及这么多年积累的海量数据。云知声一开始是用AI 1.0的方式在做云知大模型,现在正将其进化到预训练大模型的方式。
云知声下游覆盖智慧物联与智慧医疗两大场景,未来会从智慧医疗入手,应用我们的大模型,面向医院、医生及医管部门,提供AI医学大脑。那么,ChatGPT在医疗场景有哪些用途呢?ChatGPT的回答是:医疗问答、聊天机器人、疾病诊断、医学文献检索、患者跟踪等,归根结底,它也是在做虚拟医生。
云知声对ChatGPT做了比较长时间的分析,并根据我们积累的行业知识做了一些推导,发现除了上述一些通用的局限之外,ChatGPT在垂直领域还有进一步的应用局限:
1.在某些问题上可以给出一个很好的答案,但它没法对自己作出的回答援引资料进行背书,没法对自己可能出现的错误负责,医生较难为模型的错误买单;
2.在医疗领域的生成文本,难以保证可控,可信和可靠——场景更关注短板而不是长板;
3.尚不能整合电子病历、影像、基因组等多模态医学数据;
4.难以导入医院内部数据和知识;
5.难以及时更新最新文献结果;
6.使用成本尤其是监管成本的问题。
云知声的主要工作重心就是解决大模型在垂直场景落地的这些具体的局限。例如,我们会做行业知识的增强以解决“幻觉”的问题,会做企业检索的增强、API的增强、微型化以及IO审查,所有这些问题都是可解的,都会在有限的时间内解决。
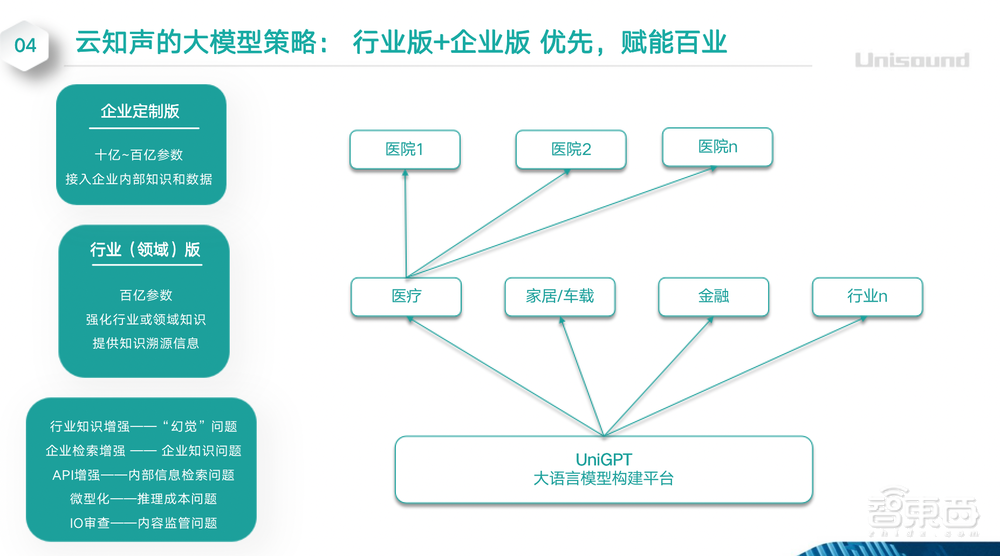
在这个基础上,云知声会推出面向医疗行业的行业版大模型,并在行业之上,面向客户提供企业定制版大模型。从2016年进入医疗行业以来,云知声经过多年积累,在数据层面、在大模型以及知识图谱方面都取得了一定的进展和成效,有一个非常好的起点。
云知声的愿景,就是从医疗版着手,逐步覆盖到其他专业版,最后把各个专业版联合起来,基于MoE(Mixture of Experts)技术做模型集成,训练得到通用增强版。
从业那么多年,这是第一次感觉AGI距离我们那么近,以前用AI技术去解决某个场景的某些问题,一旦涉及到业务本身如何真正赋能行业时,就会遇到各种各样的应用层面问题。今天这个时间点给了云知声一个新的机会,我们可以真正通过AI的方式把我们原来的愿景和梦想真正落地。谢谢!
以上是李云霄演讲内容的完整整理。
