








智东西(公众号:zhidxcom)
编辑 | GTIC
智东西4月14日报道,在刚刚落幕的GTIC 2023中国AIGC创新峰会上,aiXcoder(硅心科技)CTO郝逸洋带来了主题为《大型语言模型(LLM)时代下的代码生成》的主题演讲。
他谈道,GPT-4带来了代码生成的新变革,支持更长序列、更多指令号微调、多模态(图片输入)等操作,展现出更适于泛用的效果,同时也面临不少问题,包括缺乏相关文件、依赖库及需求文档,以及速度较慢、信息安全威胁等。
实际上,程序生成模型与语言模型有较大区别,比如在交互方式方面,普通的对话语言模型以问答、续写为主,程序生成模型则需要填空、补全、备份。
郝逸洋称,未来,aiXcoder将促进模型从百亿级扩展到千亿级,加入大量自然语言处理+代码的混合数据,针对编程中的各类场景专门构造指令数据集,从而得到综合性能更好的代码编辑工具。
据悉,aiXcoder(硅心科技)是一家AI虚拟编程机器人研发商,旗下有“aiXcoder智能编程机器人”,基于深度学习模型,并针对不同的专业领域和编程语言,能够自动预测程序员的编程意图,向用户推荐即将书写的下一段代码,进而提升代码的编写效率。
以下为郝逸洋的演讲实录:
各位下午好!
之前的一些环节其实都是在讲一些比较大的、涉及到整个AI领域上的一些事情,接下来我讲的内容可能会比较聚焦一些,重点聚焦在代码这个小领域上。但说小也并不小,整个开发的程序员群体其实是非常庞大的,它能产生的市场价值也是非常大的,这就是我们正在做的事情。
一、LLM时代的代码生成,GPT-4利弊并存
在ChatGPT出来之前,世界上就已经有很多的代码生成模型。那什么叫做代码生成?用AI的方式来生产代码,帮程序员完成一部分的写代码工作,未来甚至还有可能代替程序员,这就是代码生成。在ChatGPT或者说是GPT-4出来之前,我们用的办法很简单,就是把代码换到大型的自然语言模型当中,让它来续写代码。
到GPT-4时,已经比之前的ChatGPT版本好多了。GPT-4有1750亿的数据,在GPT-3的基础之上对ChatGPT进行微调,让它学会了对话的能力,又在它的基础上进一步训练。虽然OpenAI没有公布出相关的细节,但从结果来看,GPT-4有了更长序列的理解能力,以及更多的指令微调,还包括对图片的理解能力,这就是我们现在得到的GPT-4。
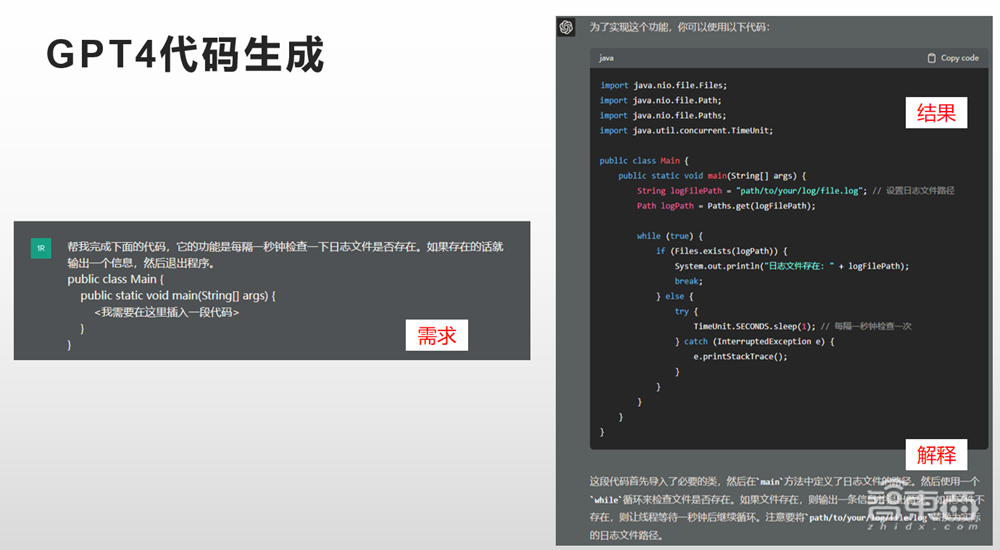
前几天在尝试用GPT-4做代码生成以及其他相关任务的试验时,我们给出了一段自然语言描述的需求,又给了它一个没有完成的代码片段,让ChatGPT去完成这段代码,它完成的结果非常好。除了最后的结果之外,它还给出了一段解释。
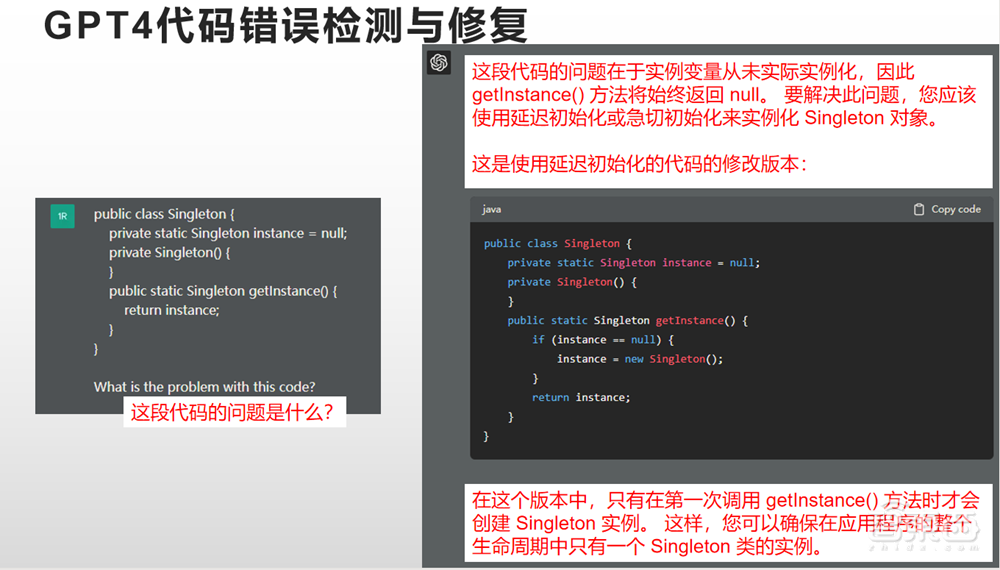
我们又尝试了一些别的功能,比如代码的错误检测和修复,我给了它一段有问题的代码,我问它,这段代码的错误是什么?它回答了我,告诉我这段代码实际的问题是什么,还告诉我这段代码应该改成什么样,最后还解释了修改之后的版本为什么可以正常运作,这就是用户真正想要得到的结果,它确实可以做到。
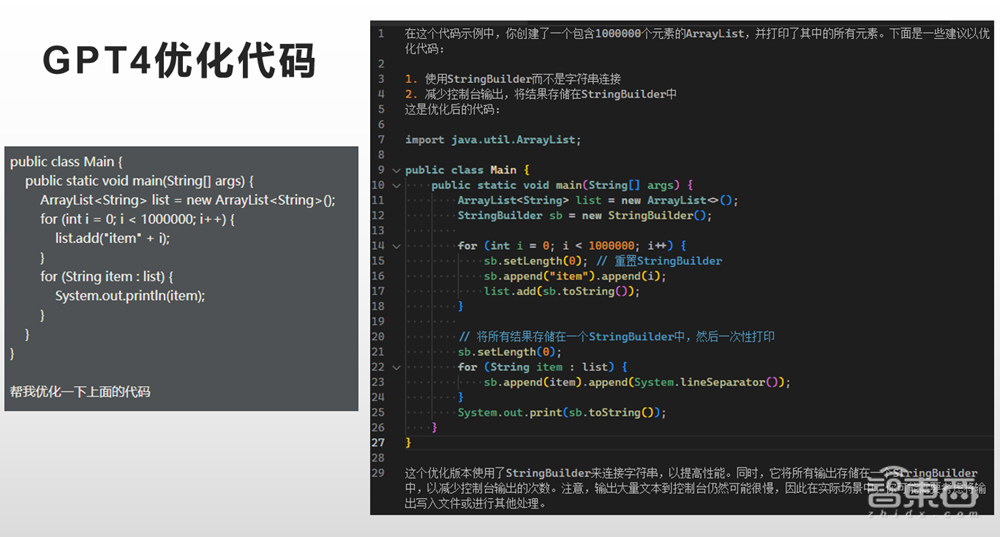
GPT-4还能完成代码优化,我给了它一小段有缺陷的代码,代码中循环一百万次往一个relist里面放东西,我希望它能发现这一百万次其实有点大了,应该要先申请一批内存,而不是不断地去增加循环次数。但出乎意料的是,GPT-4并没有发现这个问题,反而发现了两个别的问题。GPT-4把所有的东西都放到一个文件夹里,最后一口气来打印所有的日志,并给出解释以及最后的描述,GPT-4具备一个完整的能力。
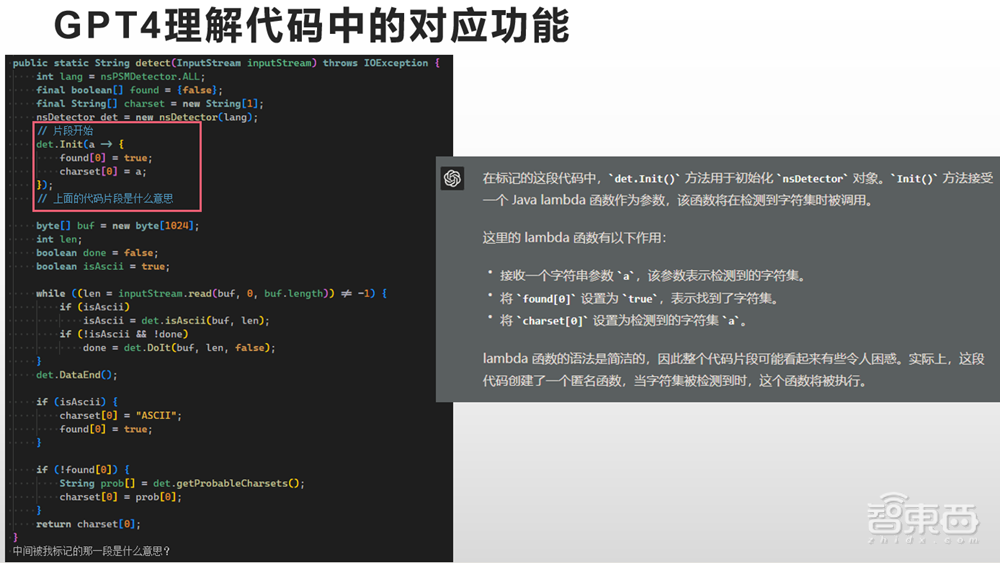
GPT-4对片段也有理解能力,我给了它一个很长的代码,问它是什么意思,它就能告诉我是什么意思,对于用户而言这是一种很强的能力。GPT-4是很泛用的代码功能,它是在GPT-3的能力之上训练出来的,为GPT-3加入了一些RHF让它有更好的对话能力,又在这个基础上训练出了GPT-4。
我想GPT-4的能力从GPT-3而来,我做了一个实验,给了它同样的一段代码,问它这段代码的问题是什么,它的答案前半部分描述了我在做一件什么样的事情,后面却越说越不对劲,它说我收到了以下错误,实际上我没有收到任何错误。为什么GPT-3会有这样的行为?GPT-3的训练模式就是语言模型,这个模型主要就是往后续写。我给它一个问题,它就续写这个问题,虽然它把这个问题更加详细地描述了一遍,但并不是我所希望的东西。
这种情况有一个很好的办法可以避免掉,当我给它一个引子,给它冒号告诉它接下来要写的答案,让它续写,针对我们的需求构造出一个提示,让模型可以根据我们的提示往后生成内容。这是在ChatGPT之前我们使用大语言模型的主要方式,它也能答出这个结果,跟GPT-4给的答案是一致的。如果我接下来告诉它,接下来需要修复的问题是什么,需要修复的代码是什么,它应该也可以以同样的方式给出来。
GPT-4的强处就体现在这里,是很泛用的能力,可以解决开发中遇到的各种问题。我总结了一下,在用GPT-4辅助代码开发的过程中,你只用把你的问题描述一下,丢给GPT-4,就能用它的结果。Github前两天发布了CopilotX,本质上就是在做这件事情,除了刚才demo中的四个场景,另外还有两个场景,一个是文档搜索,另一个是Prompt Quest描绘的生成,和自然语言相关,主要的功能和我刚才测试的场景差不多。
二、GPT-4弱势初显:依赖数据、速度慢、信息安全隐患
我们用GPT-4或者是CopilotX去做这个辅助代码开发时,我们兴冲冲地去尝试,但是往往会遇到很多实际的问题,比如如果我们要做一个可以在网页上运行的贪吃蛇程序,要把这个问题描述清楚可能有点难度,一般的程序员还得先想想或是上网查点资料才能写出来,但这个问题对于GPT-4来说没有难度。
真正有难度的是,当我在写一个有业务逻辑的代码的时候,我需要把用户购物车里的商品循环一遍,还要把每个商品的价格取出来求一个和,获得总价来反推回去。
这个逻辑让一般的程序员理解起来没有问题,但是让GPT-4来做这件事就很困难。GPT-4和我们所理解的购物车不一样,它不知道购物车是什么,我们需要把这个结构告诉它。总价要怎么获取它也不知道,种种因素放在一起导致很难跟GPT-4描述清楚这件事情,因此它生成的代码很难用。
第二个问题是它太慢了。我们把这个问题抛给GPT-4,补完这段代码的时候,代码需要一分钟来生成,生成完之后还得修改它,需要把它里面购物车的部分改为你那一部分的购物车,需要把它获取的商品价格改为你的商品价格。一分钟的时间你可能早就已经写好这个代码了。
最后就是信息安全问题。GPT-4毕竟部署在美国,不受中国政府监管。如果一个公司的很关键的信息、资产、代码等,通过互联网传输到了美国的服务器上来获得结果。那这个事情对于企业来说是否可以接受?哪怕OpenAI在国内开了分公司,把模型部署在国内,那么它是否信任国内的部署商也是个问题,中国一层层的网络链接等都是问题。
另外,当你在手误敲分号键时不小心敲到了L键上时,这是Java开发上很常见的问题,GPT-4能在用户反应过来之前把这个错误改好吗?从能力上说它是可以做到这一点的,但是实际效果很差,一是速度太慢,二是很少见到拼写错误以及被拼写错误修改过的数据。
GPT-4有一定的泛化能力,由于训练时它是用网上抓取的数据、文件和页面来进行训练,这些内容基本没有拼写错误,因此它也很难理解拼写错误应该怎样去修改。这个问题可以通过人工反馈强化学习的方式来训练它,但是这种训练的效果可能还不如十几万参数的模型来做。这一点GPT-4很难做到。
三、开发综合性代码编辑工具,训练千亿级语言模型
当我们说到一个代码项目里面的信息非常大时,我们往往指的是它的前后文。项目配置和语言模型有一个天然的区别,它们的交互方式很不一样。从aiXcoder产品实际的例子可以看出来,他会对当前光标所在的位置进行补全,会对下面IDE的提示做出排序,还会往后做一个填空的操作。这些都是它和语言模型所不一样的地方。
这里有一个具体的例子,一个看上去很简单的插入任务,已经给出了前后文,需要让它补充中间的东西。
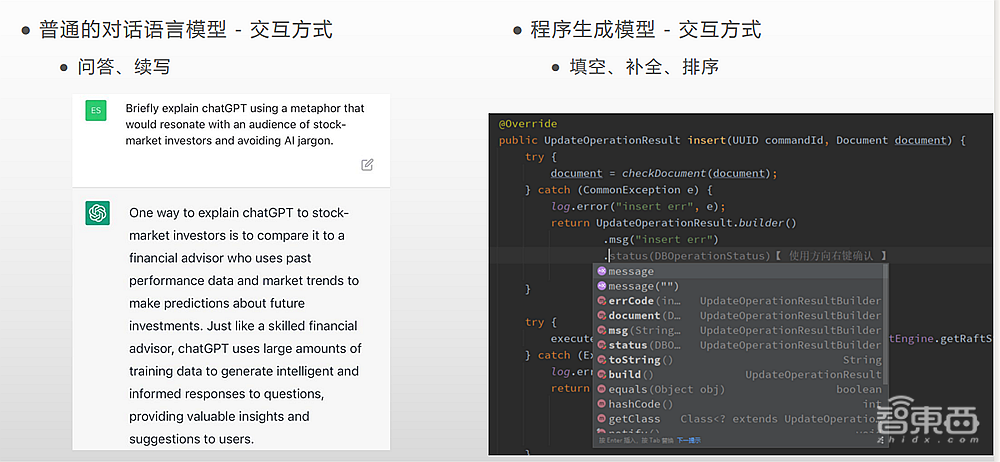
实际上,在设计这个训练任务的时候,里面有很多小细节需要考虑。最简单的一个方法,也是很多预训练模型的方法,先确定一个长度,假设是1024,有了这个长度之后,在里面随机挖出一个空,让模型来补全这个空并生成里面的内容。无论怎么生成,它都不会超过当前的长度,这就会导致一个问题,当我们在实际代码中使用这样一个模型的时候,我们发现无论这个空有多长,模型都会努力用最短的代码把前后文连接起来。
最后,我们设计了一套方案,强制保留前文和下文,并且不限制这个空的长度,最后得到了一个模型。我们一开始期望模型输出能把不存在的值给定义出来并且补充完整,但是它直接把当前的函数结束了并且又新建了一个函数。
遇到这样的问题我们只能通过改变训练任务来解决,设计训练任务的时候就要考虑到这些情况。
我举这个例子就是想说,在训练GPT-3、GPT-3.5、GPT-4时也要考虑这样的问题。GPT-4目前的缺陷,第一是在实时性上,它对于代码纠错缺少实时性,只能在代码全部写完后整体纠错;第二就是它的上下文序列有限,看不到项目里面所有的信息。最后一点也是它最致命的问题,整个项目中的信息、配置、文件等和从网页上抓取的文件差异很大,和主动构造的数据相比它表现的还是要差一些。
aiXcoder是用ChatGPT类似语言模型的方式做代码生成的一套工具,现在已经免费上线使用了。
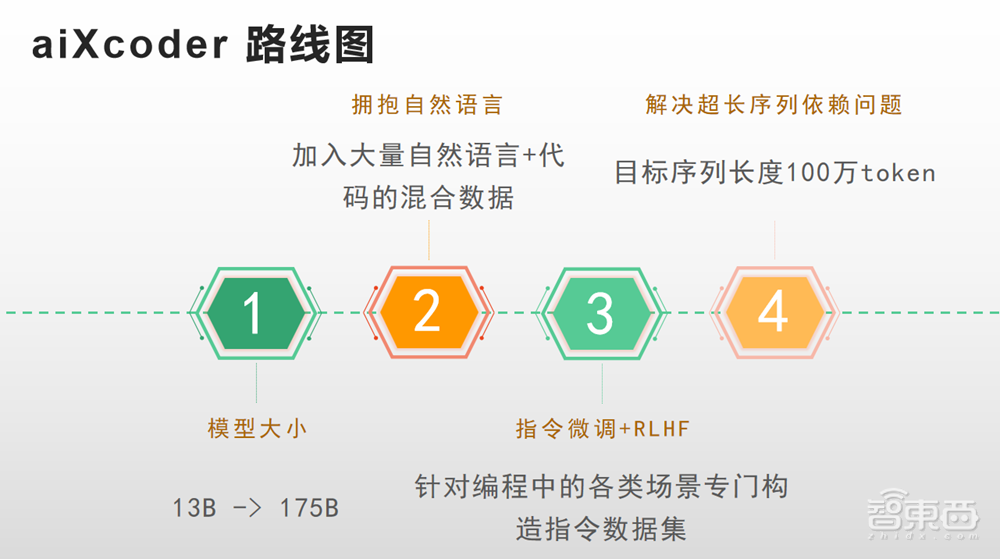
我们的下一步就是要汲取ChatGPT在代码上的能力,首先是把大模型参数逐步从百亿级增加到千亿级,还要加入更多的自然语言数据来训练它,让它有理解自然语言的能力,最后通过指令微调来针对更多场景,构造一个指令级的数据,解决在代码中的程序依赖问题,最后能得到一个最好的代码全模型,完成代码理解、代码生成、代码修复的综合智能化代码开发。
谢谢大家!
以上是郝逸洋演讲内容的完整整理。
