








智东西(公众号:zhidxcom)
编辑 | GTIC
智东西4月18日报道,在刚刚落幕的GTIC 2023中国AIGC创新峰会上,澜舟科技创始人兼CEO、中国计算机学会CCF副理事长、创新工场首席科学家周明以《大模型带来的新范式》为题发表了主题演讲。
作为微软走出的技术专家,周明非常认可微软联合创始人比尔·盖茨关于“要把自然语言理解做好了,基本上可以重塑一个微软”的评价。
在他看来,大模型正带来认知智能的崛起。大模型尤其是ChatGPT代表着语言理解、多轮对话、问题求解进入了一个可实用的时代。同时,大模型有效解决NLP任务碎片化问题,大幅度提高研发效率,标志着NLP进入工业化实施阶段。AI 2.0时代将首先革新创作内容、办公方式、搜索引擎、人机交互界面、金融场景任务等领域。
创立于2021年6月的澜舟科技已推出了多个大模型对外产品服务,目前已落地孟子大模型、AIGC(智能创作)平台、机器翻译平台、金融NLP平台等多款技术及产品,落地同花顺、华夏基金等企业。结合类ChatGPT技术,澜舟科技推出了对话机器人MChat,能够通过智能对话帮助用户完成特定场景中的多种工作任务。
谈及对产业未来方向的展望,周明坦言,当下类ChatGPT技术在推理、逻辑、数学和算术、事实性错误等方面仍有所欠缺。未来,大模型相关的九大问题尤其值得关注,涉及推理能力、事实正确性、中文处理能力等方面。
以下为周明的演讲实录:
今天给大家介绍我们对大模型的一些新思考,我的演讲分三部分:一是我们对大模型的理解,它带来哪些新的范式变化;二是澜舟科技在这个领域所做的一些努力;三是未来大模型的发展。
一、大模型标志着NLP进入工业化实施阶段
我先谈谈大模型的一些背景。此前十余年人工智能在感知智能方面进展迅速。大模型带来认知智能的崛起,大家都知道2017年谷歌提出了Transformer技术,随后预训练模型BERT、GPT等一系列技术出现,NLP能力在各项任务上大幅度提升,最近ChatGPT带动了NLP发展热潮。
我们今天看到的一个明显趋势是AI正在大模型驱动下快速实现认知智能。认知智能包含语言理解,就跟我们的大脑一样,理解后要回答、解决问题,对业务做出预测。它有很多广泛的应用,从翻译、问答、交互、搜索、推荐、写作、专家系统等等,你能想到的跟人的智能有关的应用,几乎都是认知智能。
它对企业非常重要,原来企业讲大数据,现在智能平台可以把企业的很多业务进行升级,甚至可以提供一些企业洞见,发现数据之间规律。
大规模预训练模型简单来说就是几件事:1、海量文本数据,比如互联网数据;2、超大规模算力;3、超大规模预训练语言模型,要么针对不同任务进行微调(BERT/GPT),要么连微调都不做(GPT-3,ChatGPT);4、一个模型解决N个任务。
大家最近很熟悉的是ChatGPT,其实大模型有很多流派,像BERT是encoder这边,GPT是decoder这边,T5既有encoder又有decoder,它适合不同的场合。BERT类似的东西一般适合于文本分析、信息抽取,GPT更多适用于文本生成,T5更多被用于机器翻译。
当前在预训练模型领域较受关注的研究重点包括:第一,怎么把大模型做到更好,把它的能力做到更强?第二,预训练大模型代价太大,怎么降下来?第三,我自己有行业数据、有知识图谱,怎么融入进去?第四,做下游任务时,能不能少标点数据,少样本学习或者无样本学习?
我这里有两句话,希望大家能有点印象:第一,大模型尤其是ChatGPT和GPT-4,代表着语言理解、多轮对话和问题求解,进入了一个可实用的时代;第二,大模型有效解决了NLP任务碎片化问题,大幅度提高研发效率,标志着NLP进入工业化实施阶段。
传统NLP开发存在任务碎片化严重的问题,每一个NLP小任务比如分词、语义理解、机器理解都是从头开始开发,每个企业的数据又不一样。其他问题还有要做很多数据标注、开发周期长、支付成本高、维护代价高。
有了大模型,用微调(Fine-tune)或者提示(Prompt)技术,一下子就把碎片化解决得很好;再加上一点零样本技术或Prompt技术,减少了数据标注问题;再有一些轻量化训练方法或部署方法,减少了客户代价;还可以帮助客户自行快速建模,以便快速验证业务流程;最后可以通过本地部署或SaaS提供服务,减少用户的开发代价和维护代价。
我原来也是微软的,我一直受到比尔·盖茨的感召,他曾经跟我们在review的时候说过一句话:“你们要把自然语言理解做好了,基本上可以重塑一个微软。”我们这些天看到的微软和ChatGPT和OpenAI的合作中,几乎微软所有的业务都受到了一些新的革命性的影响。
ChatGPT有对话、语言理解、改写、翻译、写作、解题等能力,具体来讲,有几件事印象深刻:比如in-context learning,不需要改变大模型参数,用Prompt技术一个模型解决N多问题;还有Instruct-learning、涌现能力、复杂query理解、多轮对话、推理、逻辑、NL2Code、与人类价值观对齐等等。
过去几十年来,NLP也好,AI也好,以前都是一个模型解决一个任务,要针对每一个具体任务,设计规则(规则系统)、设计特征(统计系统)、针对大模型微调(大模型早期),开发周期长,而且不能复用。训练出来的模型,只具备这个能力,不具备其他的能力,而且设计的能力水平不会因模型架构修改或数据增加出现跃升。
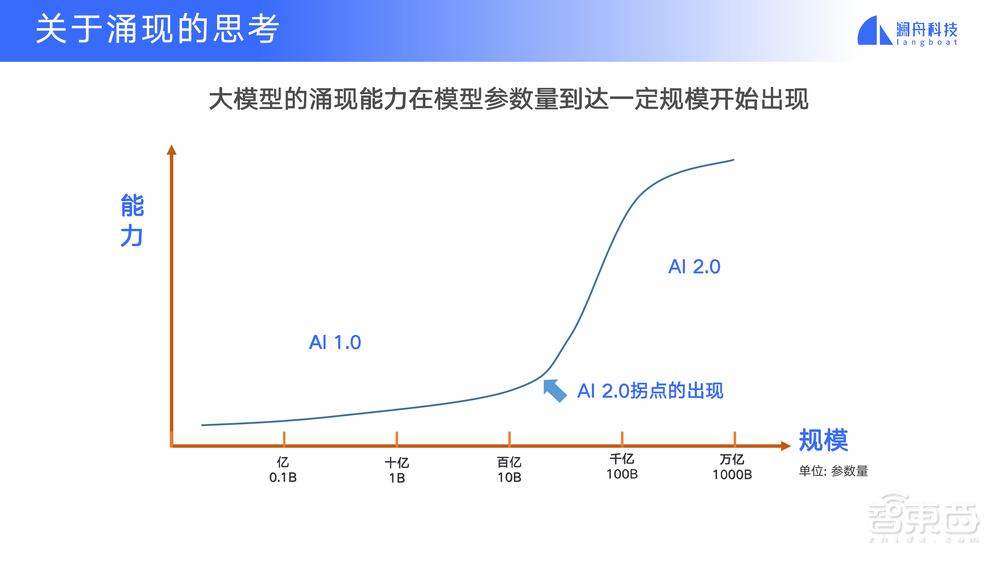
这样的AI系统,我管它叫AI 1.0系统。有点类比于比较本分的小孩子,你告诉他做什么,他做什么,不会举一反三,不会触类旁通,他练习增加,能力可慢慢增长,但是不能顿悟。在GPT3.0,GPT3.5和ChatGPT之前,我们就简单地说ChatGPT之前是AI 1.0时代。
现在ChatGPT带来了一个所谓的AI 2.0或者NLP 2.0时代,用一个模型解决N个功能,再加新的功能,就用Prompt技术把它的能力带动起来。再往前走,我们可以设想这样的能力一点点增强,一点点走到所谓的通用人工智能(AGI)。

二、大模型改变工作范式:激发创意、高效办公、革新搜索、重塑人机交互
AI 2.0时代会带来哪些影响呢?
第一个影响是ChatGPT以及大模型,很好解决了创意问题,以前想一个营销文案半天想不明白,现在跟它交互几次,它可以提供很多新的创意。解决了这个问题,就可以大批量生产很多内容。这已经影响到大文娱、影视传媒等很多产业。
第二是办公自动化的问题,生成式AI让用户更加专注自己的业务领域,把繁琐的生成工作交给AI,让工作成果展现更加高效。像微软Office加上了Copilot,邮件、文章、PPT等办公工作的生产过程更加智能化、更加快速。
第三是对搜索引擎的影响。原来一个query得到10个Boolean,现在搜索引擎基于大模型的理解,可以做复杂query理解,可以做语义层面的query和文档的匹配;以前搜索就是看数据,看不到数据内部的规律,现在除了看数据,可以形成总结、形成观点洞见,对数据可以有深度的洞察;最后是整个搜索改变了,原来就是搜索,现在把搜索、了解内容、了解规律、形成洞见、写出文章及发表,都可以一条龙提供服务。
除了微软提供的通用搜索服务,我们也可以设想在某些专用领域,把这样一些事情,比如解决金融领域的投研分析、投研报告问题,对各行各业都有非常大的影响。
第四是对用户语言的理解增强,你可以用自然语言与几乎所有的应用、所有的设备对话,你也可以把很多第三方的东西通过插件的方式联系到你的系统里,就像我们所看到的OpenAI通过发布了一些插件的方式,实际上用AI连接一切。我认为这是未来非常大的一个趋势。
三、澜舟科技大模型已落地金融场景,具备百亿级类ChatGPT能力
有了大模型,怎么改变行业?
我们要做金融,拿金融的数据继续训练,得到一个金融大模型,再支持金融中几乎所有的业务,这就是我们大模型落地方面所做的一些努力。
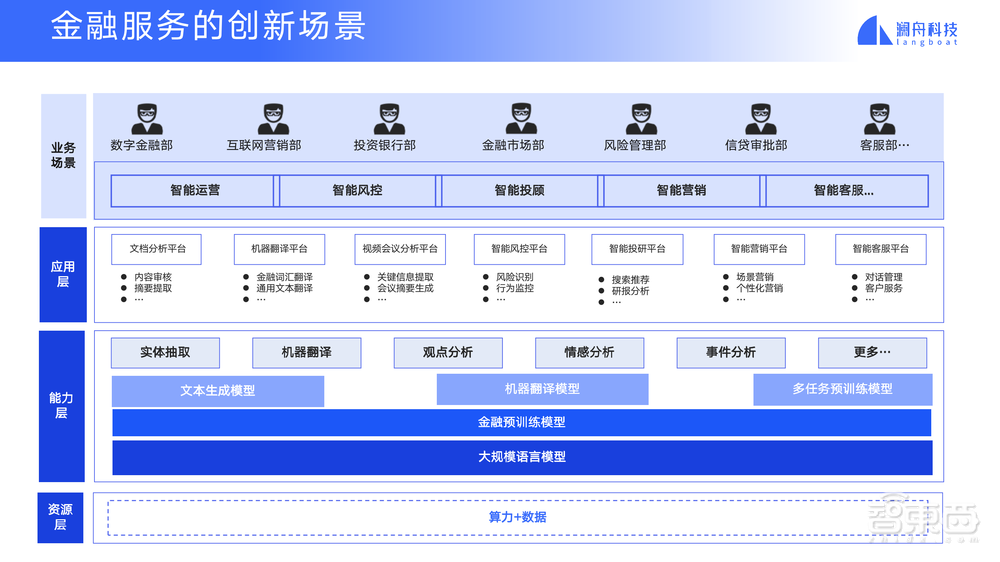
在智能客服场景,我们有上下文理解、多轮对话的能力,会对现在的客服、基于FAQ的客服产生碾压式的影响。
在营销文案生成场景,跟聊天机器人对话,可以激发新的灵感,最后得到不错的营销文案;可以生成各种各样的风控报告,基于信息抽取能力得到一些干货,包括保函审查、搜索问答场景等。
接下来介绍一下澜舟科技做了哪些工作,以及我们站在从业人员的视角,看类ChatGPT未来的发展趋势是什么。
澜舟科技成立于2021年,一直做大模型,我们的大模型获得了HICOOL 2021全球创业大赛一等奖,得到时任北京市长陈吉宁先生的接见。
我们已经推出一系列大模型的服务,像AIGC(智能创作)平台、机器翻译平台、孟子大模型、金融NLP平台等等。这些底层都是大模型,上层针对行业特点做继续训练,或者针对任务特点做监督学习,把大模型和体系发布出来,通过SaaS或者本地部署来提供服务。

孟子大模型有很多应用案例:比如跟同花顺做大模型在金融领域的落地,用于问答、对话、信息抽取等场景;跟传神做大模型在多种语言翻译和多种垂直领域翻译的应用;跟华夏基金做舆情分析平台;跟数说故事合作做AIGC营销文案写作。
澜舟科技把类ChatGPT做出来了,加上以前做的很多功能,如何用类ChatGPT把原来的功能串通起来,来解决行业的落地问题。比如调用类ChatGPT的能力,让它介绍一下爱因斯坦,回答如何发现相对论的、推荐北京的5个著名景点、续写小说、写一个口红的营销文案、作为工具处理一些金融场景任务等等。
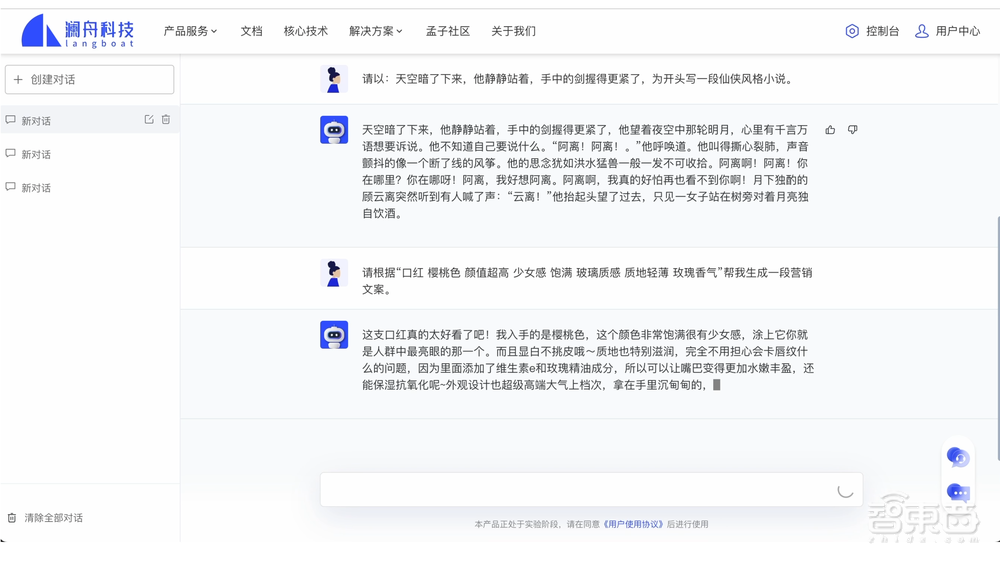
目前我们开发的是百亿级的类ChatGPT能力,有一定的对话、理解、问答各种方面的能力。我们花了很多工夫去整理中文数据,增强中文对话能力。我们也可以让类ChatGPT调用一些已有的引擎,比如可能企业自己原来就开发出很好的翻译、写作等引擎,可能有第三方引擎,如何跟类ChatGPT联系起来。
四、未来大模型研究方向,9个问题待解
再花5分钟的时间,讲讲未来的研究方向。我们先问一下ChatGPT:我是做自然语言研究的,没有很多块GPU,能做什么样的研究?
我昨天到学校去演示,很多同学也问了这样的问题,ChatGPT告诉你,第一,你可以做模型压缩;第二,你可以做迁移学习;第三,你可以做多语言学习;第四,你可以做领域有关的模型,或者说做小规模试验环境下的创新算法。
我觉得它讲得都挺好的,虽然大家都很喜欢、很追捧ChatGPT,但是它还有很多问题。我们要做未来的研究,一定要知己知彼,知道它的问题在哪里,才能有的放矢,进行改进。
第一,ChatGPT在推理、逻辑、数学和算数、事实性错误、偏见和歧视、写代码、抽象理解等方面还有很多欠缺。
比如问鲁迅和周树人是一个人吗?它说不是一个人,讲了半天理由;问父亲和母亲可以结婚吗?它回答说不可以结婚。这就说明ChatGPT在常识、事实性方面的理解和推理能力还有问题。
网上最近热传的画一幅唐伯虎点秋香的图,结果AI画成了一只老虎正在点香,实际上是因为它不理解中国的文化,可能是把中文翻译成英文,调用了Stable Diffusion,Stable Diffusion是针对英文的特点做的数据清洗和训练,所以拿它做翻译肯定会有很多的问题。实际上,要从根上来做,需对数据清洗做出中文标记,不能仅仅依靠英文标记,有很多的功夫要做。
信息抽取也有很多挑战,比如对话式抽取的意图理解欠佳,领域知识不足,缺乏专业度。Prompt这件事既好又坏:好的Prompt能够把它的能力带出来,可是如果不会写Prompt,它的能力放在那儿也用不起来。
还有涌现,大家整天讨论涌现,涌现到底是什么?什么时候能出现涌现?模型做到多大才能出现涌现?模型小一点的时候,能不能用什么招把数据弄好,把算法弄好,让涌现早点出现,别等到搞到万亿模型才出现涌现?
以及如何建立大模型的评测体系?有没有一个比较客观的自动化较强的体系来测大模型的能力?虽然我们看到学术界有些分任务做了一些标准测试集,但是很多新的大模型的能力是没办法测试的。所以我们呼唤产业界、学术界把大模型的评测体系好好地建立起来。
总结一下未来大模型方向的9个问题:
1、如何增强模型的推理能力,能理解复杂任务,如解数学题、逻辑推理。
2、如何提高生成内容的事实正确性,保证生成内容安全可靠。
3、如何最小化代价建立实时学习模型,能基于新产生的知识去生成答案,保证内容的时效性。
4、提升中文的处理能力,如中文处理的成语、比喻、跨模态的语义对齐等。
5、如何增强领域知识、跨语言知识、更好注入特定任务知识等。
6、如何更加交互地、灵活地、智能地提升提示(Prompt)能力?
7、更好理解涌现能力。到底是什么能力?怎么激发出来的?能不能更有效地,而不是单纯靠模型规模急剧增加,而得到涌现能力?
8、如何做好模型轻量化?
9、如何高效构建更全面的模型评测体系,以建立更加安全、可控、无偏见的模型?
结语:在大模型带动下,迈向通用人工智能
最后总结一下:
第一,大模型带来了认知智能技术跨越式发展。
1、从AI大模型1.0到2.0,从简单能力+针对具体任务的专用模型,到复杂能力+面向泛任务的通用模型,推动着语言理解、多轮对话、问题求解进入了基本可用时代。
2、有效解决NLP任务碎片化问题,大幅度提高研发效率,标志着NLP进入工业化可实施阶段。
第二,大模型带来了个人和企业工作的新范式。
1、个人:从内容创作、办公、搜索和人机交互,都将被深深变革。
2、金融领域:智能客服、营销、风控、投研、推荐等各个方面将本增效。
3、企业服务:提升人力、财务、营销、获客、调研、报告生成等方面生产率,有效改善客户满意度,实现智能决策,提高工作效率,提升企业形象和市场竞争力。
第三,未来在大模型带动下,从AI 1.0到AI 2.0,将不断走向AGI。
1、实现负责任的、安全可控的、功能强大的通用大模型和功能引擎。
2、知识、常识、可解释、自学习、动态接入各类动态和静态数据。
3、成为认知智能的基础模型,通过云计算、本地部署和端,成为各项服务的内在中枢和各类计算机软硬件系统的泛在人机接口。
今天我的演讲就到这里,谢谢大家!
以上是周明演讲内容的完整整理。
