扫码关注智东西Pro服务号登录
请使用微信扫描二维码
绑定手机号
获取验证码
确认绑定
欢迎来智东西
登录
免费注册
关注我们
智东西
车东西
芯东西
智猩猩
智东西
车东西
芯东西
智猩猩
公开课
智猩猩
公开课小程序
线下大会
AI生产力创新奖
快讯
头条
人工智能
芯东西
AIoT
云与智慧城市
机器人
VR/AR
手机通信
活动
杨, 欢
标签
更多
通用
大众
iPhone
华为
三星
英特尔
IDx
谷歌
智东西
腾讯
苹果
高通
微软
5G
360
百度
小米
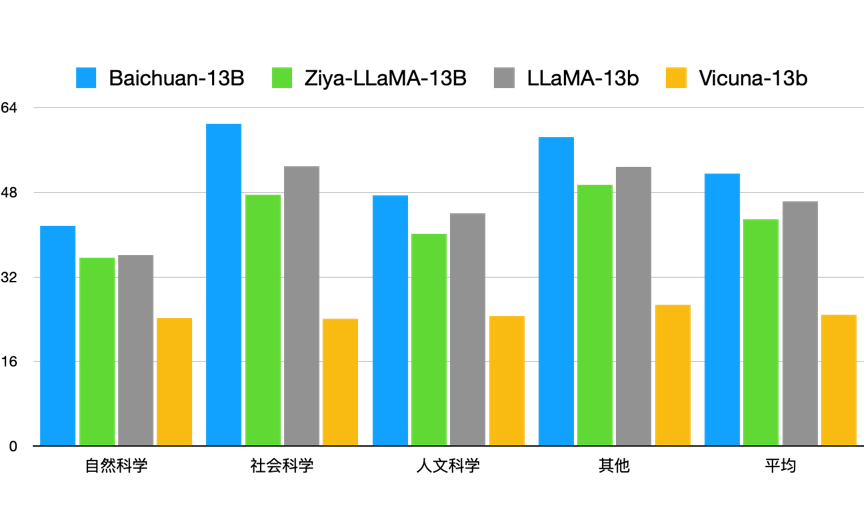
百川智能发布Baichuan-13B,开启中国开源大模型商业化时代
企业新闻
智东西
2023/07/11
25
百川智能
来, 说两句
相关推荐
加载更多...
✕
订阅
智东西晚报通过智东西Pro服务号每天定时推送 一次订阅,不错过每天行业重磅信息
扫码关注,立即订阅