








芯东西(公众号:aichip001)
作者 | ZeR0
编辑 | 漠影
芯东西7月11日报道,今日下午,英特尔面向中国市场发布可便捷扩展运行大语言模型的云端AI训练芯片Gaudi2新品,并公布面向中国市场的英特尔AI战略。

在中国市场推出的Gaudi2 AI加速器,将通过其合作伙伴浪潮提供给中国客户。浪潮信息高级副总裁、AI和HPC总经理刘军现场发布搭载Gaudi2的新一代AI服务器NF5698G7。

会后,英特尔执行副总裁、数据中心与人工智能事业部总经理Sandra L. Rivera,英特尔旗下Habana Labs的首席运营官Eitan Medina,英特尔数据中心与人工智能集团副总裁兼中国区总经理陈葆立接受了芯东西等媒体的采访。
陈葆立说,英特尔过去6个月在软件优化上做了很多工作,此次不仅是向中国市场带来芯片,而且带来了可以大规模部署、训练和推理大模型的整体方案。英特尔对方案的成熟度非常有信心。
据介绍,此次英特尔发布的Gaudi2新品是中国特供产品,在出口和支持中国客户方面没有任何问题。相比国际版Gaudi2产品,面向中国市场推出的加速卡在性能上差别不大,集成以太网端口数量从24个端口减到21个。Gaudi2及下一代Gaudi3都会在合法合规的情况下继续支持中国客户。
据Eitan Medina介绍,英特尔Gaudi2运行ResNet-50的每瓦性能约是英伟达A100的2倍,运行1760亿参数BLOOMZ模型的每瓦性能约达A100的1.6倍。

Sandra L. Rivera谈道,英特尔致力于为中国客户不断创造更高价值,通过异构产品组合,交付具有性价比的AI解决方案。英特尔中国成立于1985年,中国员工数量超过1.1万人,截至2022年总投资额超过130亿美元,中国市场营收约占英特尔全球营收的27%。

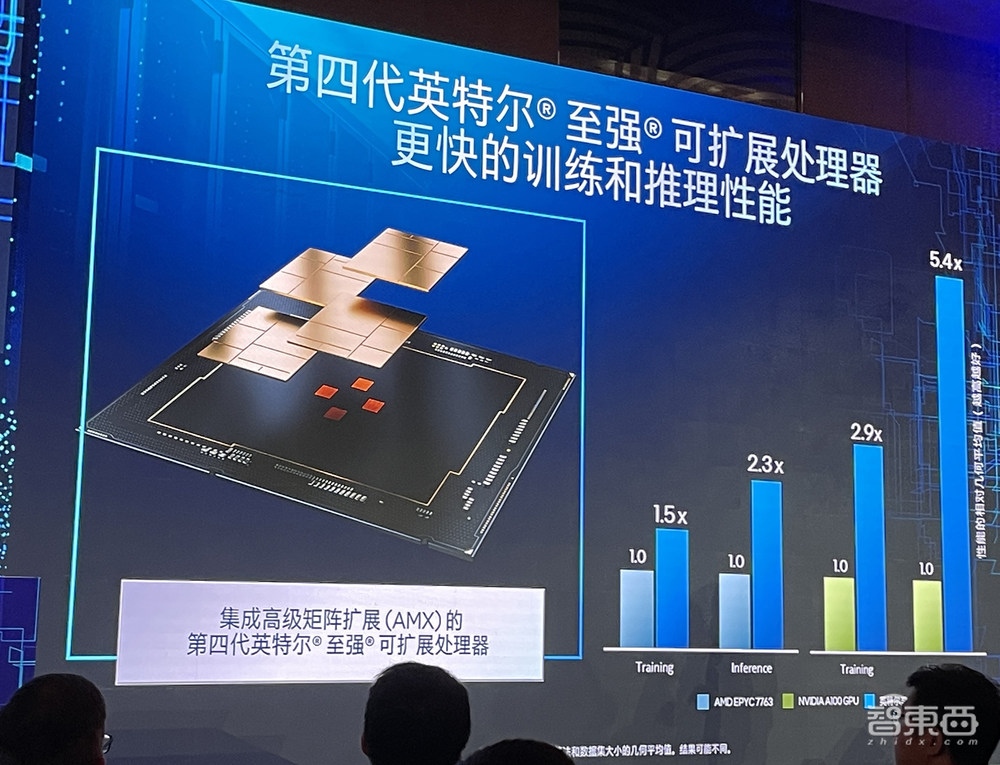
据她分享,部署AI需要异构芯片,集成高级矩阵扩展(AMX)的第四代英特尔至强可扩展处理器,能实现比A100更快的训练和推理性能。
英特尔现场演示了在第四代至强可扩展处理器上通过AMX加速指令运行文生图模型Stable Diffusion,用5.34秒就生成一张图片。

一、专供中国的Gaudi2新品:规格符合出口规定,支持大规模横向扩展
Gaudi2处理器是一款高性能、完全可编程的AI处理器,整合了多项技术创新,具有高内存带宽/容量和基于标准以太网技术的纵向扩展能力,并支持使用外接网卡通过PCle接口实现横向扩展,可满足多节点集群需要。
该训练处理器基于与第一代Gaudi相同的高效架构,采用7nm制程工艺,在性能、可扩展性和能效方面均实现了飞跃,其性价比相较于AWS云中基于英伟达的解决方案高出40%。
它利用Habana完全可编程的TPC和的TPC和GEMM引擎,支持FP8、BF16、FP16、TF32和FP32等数据类型。TPC核心旨在支持深度学习训练和推理工作负载。TPC是一款VLIW SIMD矢量处理器,其指令集和硬件经过定制,可高效处理上述工作负载。

第二代Gaudi2 AI深度学习夹层卡HL-225B专为数据中心实现大规模横向扩展而设计。HL-225B处理器符合美国工业与安全局(BIS)的有关规定。该夹层卡符合OCP OAM1.1(开放计算平台之开放加速器模块)规范。因此客户可从符合规范的多种产品中做出选择,灵活地进行系统设计。
HL-225B夹层卡内置Gaudi HL-2080处理器技术。HL-2080处理器拥有24个完全可编程的第四代张量处理器核心(TPC)。这些核心原生设计能为广泛的深度学习工作负载加速,同时还赋予用户按需进行优化和创新的灵活性。
该处理器还集成了96GB HBM2e内存和48MB SRAM,支持600瓦夹层卡级热设计功耗(TDP)。Gaudi Al训练处理器在芯片上集成了RDMA(RoCEv2),可与成熟且广泛使用的以太网进行连接。HL-2080芯片互连技术基于42对56Gbps Tx/RxPAM4 SerDes(配置为21个100 GbE端口)发挥作用。
中国专供版Gaudi2处理器具备出色的2.1Tbps网络容量可扩展性,原生集成21个100Gbps RoCE v2 RDMA端口,可通过直接路由实现Gaudi处理器间通信。该处理器还集成了用于图像和视频解码及预处理的专用媒体处理器。
二、训练GPT-3实现近线性95%扩展性,FP8版Gaudi2性价比将超H100
业内普遍认为生成式AI和大语言模型仅适宜在GPU上运行。英特尔显然正努力用Habana Labs的AI芯片打破这种“刻板印象”。
截至2023年6月,英特尔Gaudi2和英伟达H100是仅有的两个提交了AI性能基准测试MLPerf GPT-3模型训练成绩的半导体解决方案。根据最新MLPerf结果,384个Gaudi2加速器训练GPT-3的时长为311分钟。

在GPT-3模型上,从256个到384个加速器实现近线性95%的扩展效果。这种出色扩展性部分归功于其芯片上集成的100GB以太网端口以及96GB HBM2e内存。
Gaudi2在四种主流计算机视觉以及自然语言处理模型的基准测试中亦优于英伟达A100。在计算机视觉模型ResNet-50(8个加速器)和Unet3D(8个加速器)以及自然语言处理模型BERT(8个和64个加速器)上取得了优异的训练结果。与去年11月提交的数据相比,BERT和ResNet模型的性能分别提高了10%和4%,证明Gaudi2软件成熟度的提升。

Gaudi2支持“开箱即用”功能。其客户在本地或在云端使用Gaudi2时,可以获得与本次测试相当的性能结果。本次MLPerf 3.0的Gaudi2结果以BF16数据类型已提交。英特尔预计在2023年第三季度发布对FP8的软件支持与新功能时,届时Gaudi2的性价比预计将超越H100。

Gaudi2加速器已经被知名AI和机器学习开源软件工具提供商Hugging Face采用。
根据Hugging Face发布的对Gaudi2性能的测试结果,从预训练BERT模型到Stable Diffusion、1760亿参数大型开源聊天模型BLOOMZ的推理,Gaudi2均领先于英伟达A100 GPU。与英伟达A100相比,2.44倍调优3B参数T5语言模型;与英伟达A100相比,Stable Diffusion推理时延显著降低。

结语:为中国市场提供有竞争力的AI训练加速选择
训练生成式AI和大语言模型需要服务器集群来满足大规模且更加复杂的计算要求。英特尔正通过多元化硬件和软件产品技术组合,来将各种AI负载的推理和训练性能提升至新的水平。
随着Gaudi2产品进入中国市场,凭借在AI训练方面经权威基准测试验证的高性价比,英特尔将为寻求摆脱效率与规模限制的中国客户提供又一有竞争力的AI加速方案选择。
