








1、GPT-4模型架构等关键信息遭泄露
2、ACL 2023最佳论文放榜 西安交大等获奖
3、李飞飞团队发布“大模型版”机器人
4、微软推出多模态AI模型CoDi
5、百川智能推出130亿参数通用大语言模型
6、北京将发4000万元算力券 支持大模型企业
7、用户吐槽必应聊天失去创造力
8、星火大模型带动讯飞开发者增85万
9、电商平台引入AI后解雇90%员工
10、腾讯绝艺AI登顶日本麻将平台
11、达闼机器人推出机器人大模型RobotGPT
12、美国立法者正在考虑围绕AI立法
13、AI优化器助大模型训练成本减半
1、GPT-4模型架构等关键信息遭泄露
据爱范儿援引SemiAnalysis报道,今天,OpenAI旗下的GPT-4大量模型架构、训练成本、数据集等大量信息被泄露。爆料人称,GPT-4架构的封闭性是因为他们构建的东西是可复制的,Google、Meta、Anthropic、Inflection、Character、腾讯、字节跳动、百度等在短期内都将拥有与GPT-4一样强大的模型。
据透露,在模型架构方面,GPT-4的规模是GPT-3的10倍以上,作者认为GPT-4在120层中包含了1.8万亿参数,而GPT-3只有大约1750亿个参数。
OpenAI通过使用混合专家(MoE)模型来保持成本合理。具体而言,GPT-4拥有16个专家模型,每个专家的MLP参数约为1110亿。其中,有两个专家模型被用于前向传播。此外,大约550亿个参数用于注意力机制的共享。每次的前向传播推理(生成一个token)仅利用了约2800亿个参数和560TFLOP的计算。
在数据集构成方面,GPT-4的训练花费了13万亿的token数据集。这个数据集因为没有高质量的token,还包含了许多个epoch。
在并行策略方面,OpenAI采用了8路张量并行,因为NVLink最高只支持这么多。但除此之外,爆料作者听说OpenAI采用15路并行管线。
在训练成本方面,OpenAI训练GPT-4的FLOPS约为2.15e25,在大约25000个A100上训练了90到100天,利用率在32%到36%之间。
原文链接:
https://www.semianalysis.com/p/gpt-4-architecture-infrastructure
2、ACL 2023最佳论文放榜 西安交大等获奖
据ACL 2023官网,今年的AI顶会ACL 2023获奖论文日前公布,共有3篇最佳论文奖、4篇特别奖和39篇优秀论文。此外,还有区域主席奖,由每个领域的高级主席提名。据统计,获奖论文占投稿总数的1.5%-2.5%。今年获奖论文有不少出自国内机构及华人学者,涉及西安交通大学、清华大学、中科大、智谱AI等。
3篇ACL 2023最佳论文的简介及论文地址如下:
(1)Do Androids Laugh at Electric Sheep? Humor“Understanding”Benchmarks from The New Yorker Caption Contest
作者:Jack Hessel、Ana Marasovic、Jena D. Hwang、Lillian Lee、Jeff Da、Rowan Zellers、Robert Mankoff and Yejin Choi
论文地址:
https://arxiv.org/pdf/2209.06293.pdf
(2)What the DAAM: Interpreting Stable Diffusion Using Cross Attention
作者:Raphael Tang、Linqing Liu、Akshat Pandey、Zhiying Jiang、Gefei Yang、Karun Kumar、Pontus Stenetorp、Jimmy Lin and Ferhan Ture
论文地址:
https://arxiv.org/pdf/2210.04885.pdf
(3)From Pretraining Data to Language Models to Downstream Tasks: Tracking the Trails of Political Biases Leading to Unfair NLP Models
作者:Shangbin Feng、Chan Young Park、Yuhan Liu and Yulia Tsvetkov
论文地址:
https://arxiv.org/pdf/2305.08283.pdf
3、李飞飞团队发布“大模型版”机器人
据《科创板日报》报道,AI科学家李飞飞带领的团队日前发布了具身智能最新成果:大模型接入机器人,把复杂指令转化成具体行动规划,人类可以很随意地用自然语言给机器人下达指令,机器人也无需额外数据和训练。李飞飞团队将该系统命名为VoxPoser,相比传统方法需要进行额外的预训练,这个方法用大模型指导机器人如何与环境进行交互,所以直接解决了机器人训练数据稀缺的问题。
4、微软推出多模态AI模型CoDi
根据微软官网,近日,微软Azure认知服务研究团队与北卡罗来纳大学教堂山分校合作开发名为“可组合扩散(CoDi)”的AI模型,它能够同时处理和生成任意模态组合的内容。
据悉,CoDi采用了一种新颖的可组合生成策略,该策略涉及通过在扩散过程中桥接对齐来构建共享的多模态空间,从而能够同步生成相互交织的模态,例如将视频和音频的时间对齐。
5、百川智能推出130亿参数通用大语言模型
今日,百川智能推出参数量130亿的通用大语言模型Baichuan-13B-Base、对话模型Baichuan-13B-Chat及其INT4/INT8两个量化版本。
这是百川智能发布的第二款通用大语言模型,而在前不久的6月15日,百川智能就已经推出了首款70亿参数量的中英文语言模型Baichuan-7B。相比此前发布的Baichuan-7B,Baichuan-13B在1.4万亿token数据集上训练,超过LLaMA-13B40%,是当前开源13B尺寸下训练数据量最大的模型。
Baichuan-13B上下文窗口长度为4096,不同于Baichuan-7B的RoPE编码方式,Baichuan-13B使用了ALiBi位置编码技术,能够处理长上下文窗口,甚至可以推断超出训练期间读取数据的上下文长度,从而能够更好的捕捉文本中上下文的相关性,做出更准确的预测或生成。
开源地址:
Hugging Face:
预训练模型:
https://huggingface.co/baichuan-inc/Baichuan-13B-Base
对话模型:
https://huggingface.co/baichuan-inc/Baichuan-13B-Chat
Github:
https://github.com/baichuan-inc/Baichuan-13B
Model Scope:
预训练模型:
https://modelscope.cn/models/baichuan-inc/Baichuan-13B-Base/
对话模型:
https://modelscope.cn/models/baichuan-inc/Baichuan-13B-Chat/
6、北京将发4000万元算力券 支持大模型企业
据《科创板日报》报道,北京市经济和信息化局党组书记、局长姜广智在近日接受《科创板日报》记者专访时宣布,北京将以场景为牵引、应用为导向,开放更多典型场景,促进大模型产业化应用,按季度迭代推出大模型应用成果,形成一批人工智能与经济社会发展深度融合的典型案例。
此外,该局正筹划通过算力券等形式支持模型伙伴和模型观察员,降低企业的训练成本、提高算力对接效率。首期预计支持不低于4000万元的算力券,补贴到模型伙伴企业。
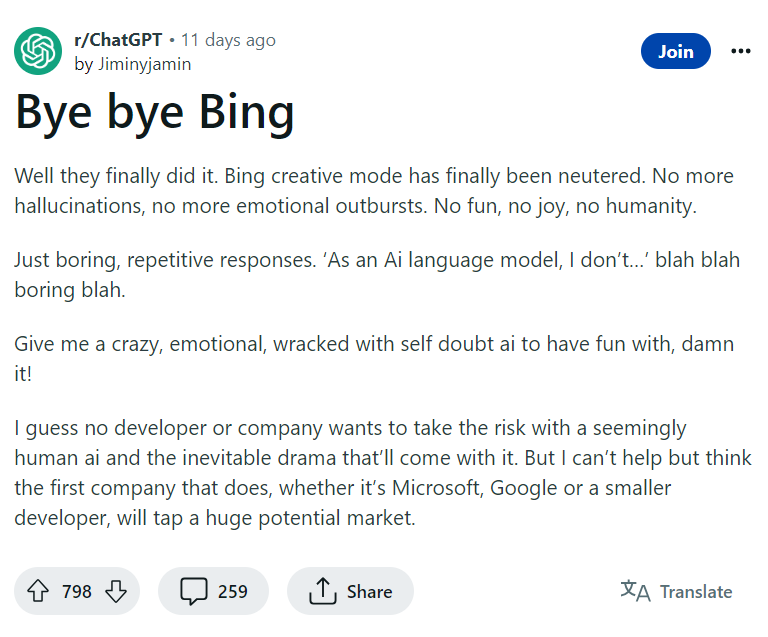
7、用户吐槽必应聊天失去创造力
Reddit社区用户近日发帖称微软对必应聊天(Bing Chat)的限制过于严格,使必应的回答变得没有创造力,只剩下“作为AI语言模型,我不……”等无聊的废话,因此他将弃用该平台。这个帖子引发了众多网友的共鸣,现有259条评论。
8、星火大模型带动讯飞开发者增85万
7月10日晚间,科大讯飞披露半年度业绩预告。根据预告,科大讯飞公司上半年预计实现营业收入78亿元,同比减少2.5%;公司上半年归母净利润预计为5500~8000万元,同比下降71%-80%。截至2023年6月30日,讯飞开放平台开发者数为497.4万(去年同期343万),近一年增长45%。其中,讯飞星火认知大模型发布后,开发者数量在两个月内增加了85万家。
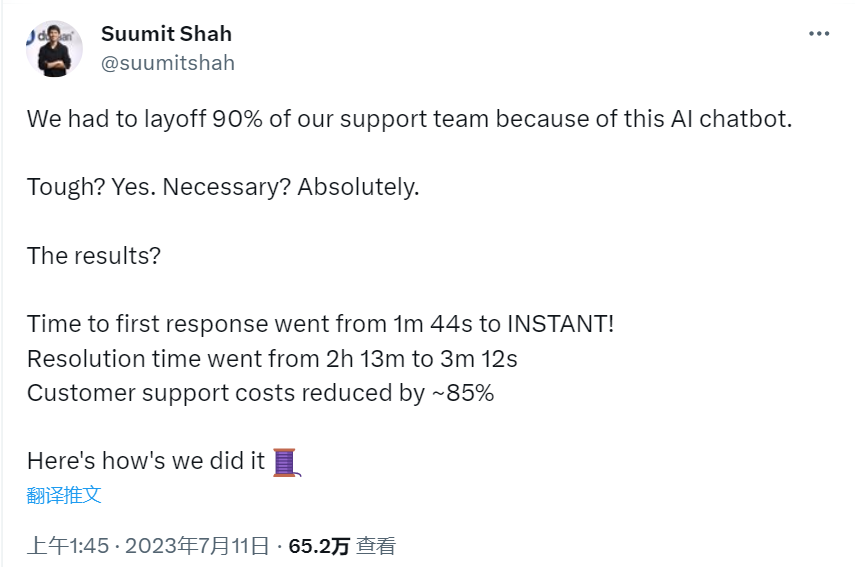
9、电商平台引入AI后解雇90%员工
印度电商平台Dukaan创始人兼首席执行官本周一发推特称,在引入AI聊天机器人来回答客户问题后,公司90%的员工已被解雇。他解释说,在引入AI助手后,解决问题时间从之前的2小时13分钟缩短到了3分12秒。他说:“鉴于经济状况,初创公司优先应该考虑的是‘盈利能力’。”
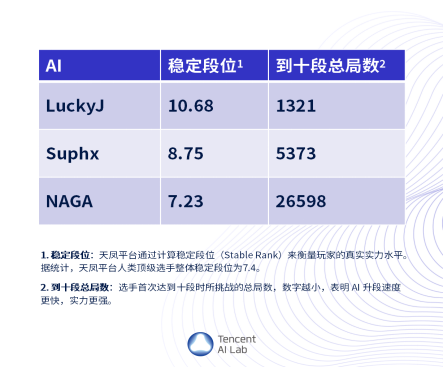
10、腾讯绝艺AI登顶日本麻将平台
腾讯今日宣布其自研棋牌类AI“绝艺LuckyJ”在国际知名麻将平台“天凤”上达到十段水平,刷新了AI在麻将领域的最好成绩。日本在线麻将竞技平台“天凤”创建于2006年,拥有体系化的竞技规则和专业段位规则,受到职业麻将界的广泛认可。截至目前,天凤平台活跃人数23.8万,而能达到十段的仅27人(含AI),不到万分之一。
根据腾讯提供的数据,相比其他麻将AI和人类玩家,“绝艺LuckyJ”不仅稳定段位更高,从零开始达到十段所需的对战局数也明显更少,仅需要1321局。这些数据的排名皆位于之前最强的两个日本麻将AI之上。
11、达闼机器人推出机器人大模型RobotGPT
据中国新闻网报道,在2023 WAIC期间,云端机器人企业达闼机器人宣布推出业界首个机器人多模态大模型RobotGPT,包含RobotGPT 1.0服务平台和RobotGPT 1.0一体机产品。
据悉,RobotGPT以多模态Transformer为基础,具备多模态(文本、语音、图片、视觉、运动、点云等)融合感知、认知、决策和行为生成能力,并基于人工反馈的强化学习完成并快速智能进化;RobotGPT与机器人的具身智能相结合,实现机器人理解人类语言,自动分解、规划和执行任务,进行实时交互,完成复杂的场景应用,推动具身智能的自主进化,让云端机器人成为通用人工智能的最佳载体。此外,RobotGPT还可以赋能数字人应用,实现虚实融合。
12、美国立法者正在考虑围绕AI立法
据外媒报道,美国参议院将在本周二首次召开关于AI的机密简报会,政府将在会议中向参议员介绍AI的机密情况。据悉,参议院民主党领袖Chuck Schumer在一封信中告诉参议员:“简报将展示美国政府如何利用和投资人工智能来保护我们的国家安全,并了解我们的对手在人工智能方面所做的事情……我们作为立法者的工作是倾听专家的意见,我们尽可能多地学习,以便将这些想法转化为立法行动。”
13、AI优化器助大模型训练成本减半
据量子位报道,近日,新加坡国立大学团队打造的CAME优化器在ACL会议上获得了杰出论文奖。优化器在大语言模型的训练中占据了大量内存资源,而该团队提出的优化器能够在性能保持不变的情况下将内存消耗降低了一半,进而把大模型训练成本降低近一半,据称目前已经投入了实际应用。
论文地址:
https://arxiv.org/abs/2307.02047
GitHub项目页:
https://github.com/huawei-noah/Pretrained-Language-Model/tree/master/CAME
