








智东西(公众号:zhidxcom)
作者 | 程茜
编辑 | 心缘
智东西9月6日报道,今天下午,百川智能发布开源大模型Baichuan2 70亿和130亿参数规模的两个版本。
相比于上一代Baichuan模型,Baichuan2在文科理科能力方面得到了全面提升,其中数学能力提升49%,代码能力提升46%、安全能力提升37%、逻辑推理能力提升25%、语义理解能力提升15%。

百川智能创始人、CEO王小川透露,在中英文通用榜单、垂直领域、跨语言能力上,Baichuan2相比于ChatGLM2-6B、LlaMA2-7B、LlaMA2-7B等开源模型都取得了较好表现。
同时,Baichuan在开源社区总下载量已经接近500万次,月下载量达到300多万次。
王小川透露,此前百川智能计划今年三季度发布超500亿参数规模的模型,四季度发布对标GPT-3.5的模型,明年一季度发布超级应用,百川智能这一计划的实际执行节奏目前十分顺利。

王小川提到,Baichuan2的发布意味着Llama作为开源模型的时代已经过去了。此前Llama-2开源大模型使用有两个限制条件,其一是用户数超过7亿不提供开源支持,第二,仅适用以英文为主的模型环境。
因此,Llama-2在中文领域的使用场景十分受限。他补充说,Baichuan2的发布能帮助开发者获得一个更加友好、能力更强的模型。
发布会最后,百川智能联合阿里云、高通、瀚博半导体、火山引擎、寒武纪等共同启动了“创新、协作、共赢”开源生态合作。
一、中英文全面超越国外开源模型,开源全部参数模型
王小川透露,目前已经有200多家企业申请部署了百川大模型,涵盖云厂商、科技行业、制造、消费等行业的企业。此次发布的Baichuan2是百川智能的又一个里程碑。
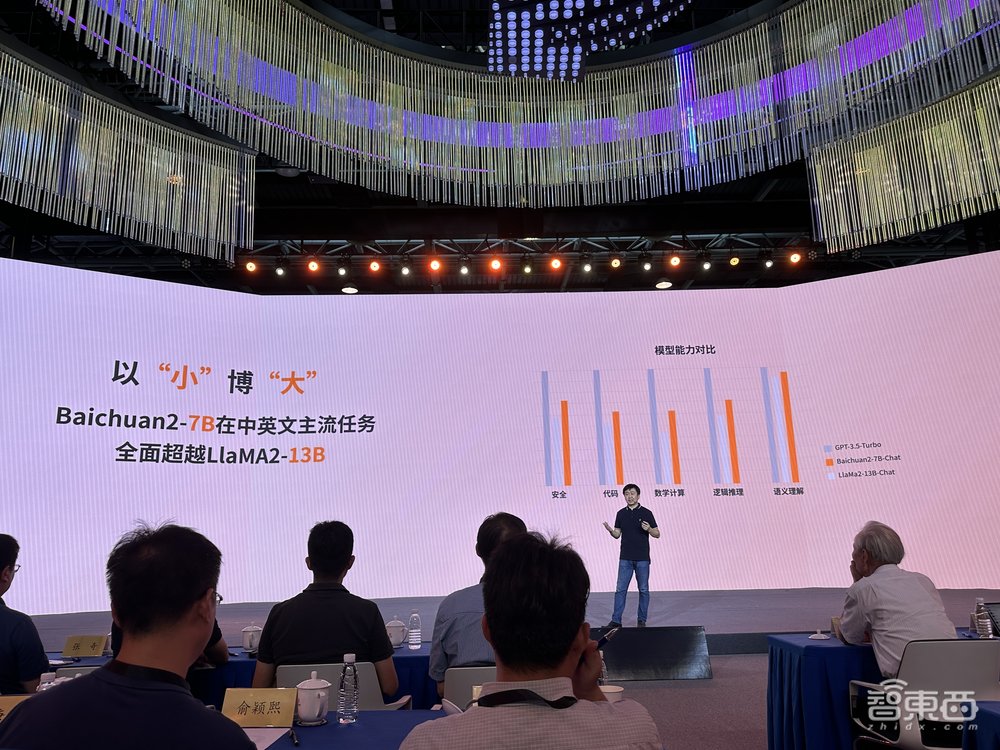
70亿参数规模的Baichuan2在中英文主流任务中已经全面超越LlaMA2-13B,王小川解释道,全面超越指的是,更小参数规模的Baichuan2在性能表现上超过LlaMA2-13B,同等尺寸上,可以吊打一众开源模型。
分拆来看,数据方面,Baichuan2的特点是规模大、覆盖全、质量优。
Baichuan2的数据基于万亿互联网数据精选,同时筛选了健康、法律等垂直行业的数据,并且构建自世界知识体系之上。在数据处理阶段,该模型通过小时级完成千亿数据清晰和滤重,打造了超大规模内容聚类系统,并且对篇章、段落、句子质量进行打分做评价,实现多粒度内容质量打分。对于训练语料,Baichuan2采用了2.6TB的超大规模语料,并支持中、英、西、法等数十种语言。
在训练方面,Baichuan2采取的是高效、稳定、可预测方式。该模型采用分布式训练框架和科学可预测的scaling law,使得小模型可以准确预测大模型的效果。
安全价值观对齐方面,Baichuan2实现了系统性价值观对齐、多类型价值观对其、有用性无害性平衡。
具体的评测效果上,王小川称,中英文通用榜单上,70亿和130亿参数规模的Baichuan2均取得同尺寸开源模型最优异效果。
70亿参数规模的Baichuan2在中英文通用榜单上的中文、英文、代码方面领先于ChatGLM2-6B、LlaMA2-7B、LlaMA2-7B等开源模型,数学能力上仅次于ChatGLM2-6B。

70亿参数规模的Baichuan2在中英文、数学、代码方面都超过了其它开源模型。

在医疗、法律垂直领域榜单上,Baichuan2两个参数规模的模型均超过其它开源模型。
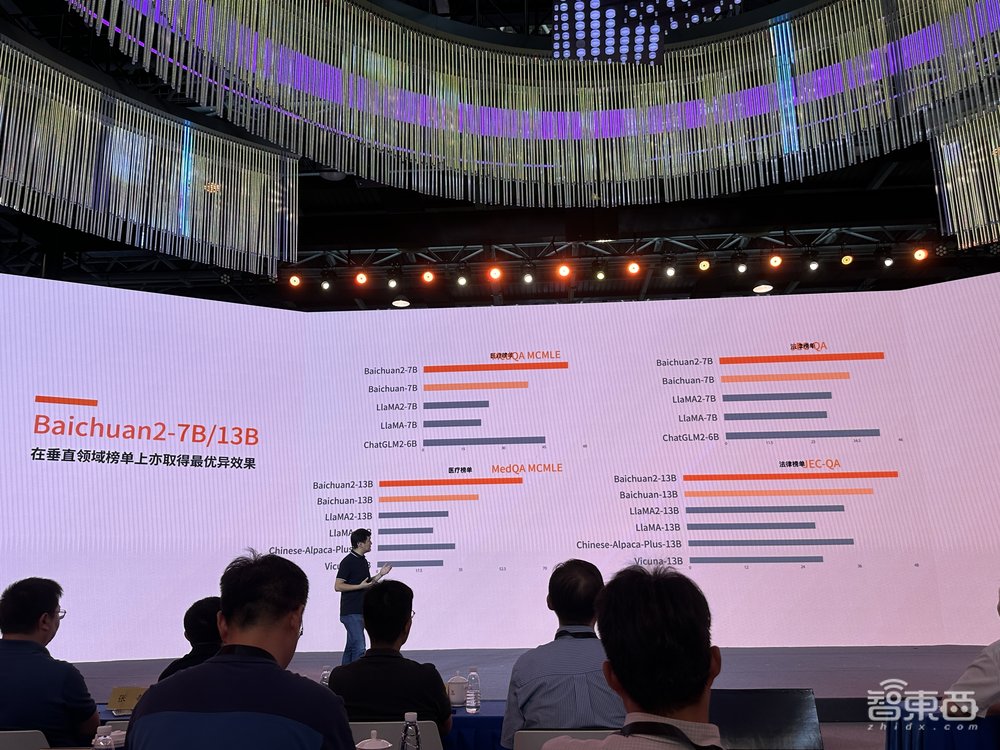
跨语言能力中,Baichuan2在英语、法语、西班牙语、阿拉伯语、俄语中的能力都超过其它开源模型。

总的来看,王小川谈道,Baichuan2的文科理科能力均处于开源模型最好水平。包括多轮对话能力、代码生成的可用率、复杂问题逻辑推理能力、语义理解能力。
在开源生态建设方面,学术和生态支持计划,百川智能公开了训练过程中的全部参数模型,以及不同大小的tokens、训练切片,使得学术界在进行预训练微调、强化时更容易操作,更容易获得学术经验和成果。王小川透露,这也是国内首次开放训练过程。
百川智能还打造了CCF-百川-大模型科研基金,覆盖大模型技术和大模型垂直领域及应用方面。百川智能联合亚马逊云科技打造AI黑客马拉松,覆盖医疗健康和游戏娱乐两大赛道,为开发者提供算力支持和超20万元的冠军奖励。
二、大模型可解释、幻觉问题是关键,不会与人类完全对齐
中国科学院院士、清华大学人工智能研究院名誉院长、吴文俊人工智能最高成就奖、CCF终身成就奖、国家科技进步奖获得者张钹提到,目前,国内已经推出了几十亿到几百亿不同规模的大模型,这些大模型很少定位于助力大模型本身的学术研究上。因此他重点提及了百川智能对于大模型学术研究的助力工作。
张钹院士谈道,这项工作非常重要。原因在于全世界对大模型的工作原理、所产生的现象一头雾水,所有结论都归到智能涌现之下,“所谓‘涌现’就是给自己一条退路,解释不清楚”。因此,他认为只有把这个问题搞清楚,国内才有可能发展出来有中国特色的大模型。
其中包含几个方面,首先,研究人员必须回答的问题是大模型为什么能产生出来非常连贯、多样化的人类语言。张钹院士认为,实现这一结果的措施有三个。
第一是文本的语义表示,文本的词、句、段落经过抽象后都变成向量,这为构造连续的拓扑空间构造了条件。第二是转换器,注意力机制可以保证大模型上下文的一致性。第三是下一个词的预测。
其次,研究人员必须要回答的问题是,为什么大模型会产生幻觉。
这与ChatGPT和人类自然语言的生成原理有关,ChatGPT采取的是外部驱动,人类是意图控制、内部驱动,这导致ChatGPT生成内容的正确性、合理性无法被保证。
因此,ChatGPT没有对齐之前,会产生大量的不合理、不正确内容,只能通过Alignment(对齐)去解决这一问题。
其中,张钹院士提到,GPT-3.5到GPT-4的性能实现飞跃,主要原因就是对齐。
这之后又会涉及到治理和开发的问题,并且治理会影响生成质量的多样性,因此如何去平衡这二者的关系也很重要。
最后,张钹院士谈道,他将ChatGPT生成的语言称作GPT语言,其与人类语言不同,又延伸出一个问题:“我们将来努力的方向是什么?我们是不是想把GPT语言完全对齐到人类自然语言?”
目前而言,这个可能性不大。他解释说,如果想完全对齐,必须先让GPT有自我意识,目前科学上没有条件能实现。
人工智能不是要做一个机器和人类一样,目前最重要的是研究了解GPT语言,只有彻底了解它,才能更好的发展它、使用它,发展出健康的人工智能产业。
结语:开源大模型生态逐渐完善
作为大模型浪潮下备受瞩目的明星企业之一,百川智能自王小川搭建团队、筹备研发起,已经发布四个大模型:6月发布70亿参数规模开源模型Baichuan-7B,7月发布130亿参数规模大模型Baichuan-13B,8月发布530亿参数规模大模型Baichuan-53B,再到现在的Baichuan2开源大模型,其大模型产品落地、商业化应用之路稳步向前。
正如张钹院士提到的,可解释性、幻觉问题是大模型亟需回答的两大问题。开源大模型对于学术研究推动的意义重大。当下,国内开源开放的大模型生态社区正在逐渐完善,相比于国外开源大模型性能更好、应用更友好的大模型出现,有望加速国内大模型产业的突破。
