








智东西(公众号:zhidxcom)
编译 | 香草
编辑 | 李水青
智东西10月19日报道,今天,斯坦福大学基础模型研究中心(CRFM)联合斯坦福以人为本AI研究所(HAI)、麻省理工学院媒体实验室、普林斯顿大学信息技术中心共同发布了2023基础模型透明度指数(Foundation Model Transparency Index,FMTI),并对10个主流基础模型进行了透明度评级。
评级结果表明,即使是得分最高的Meta Llama2也仅在满分100分中获得54分,OpenAI的GPT-4获得48分,排名第三。10个基础模型的平均得分仅为37分。
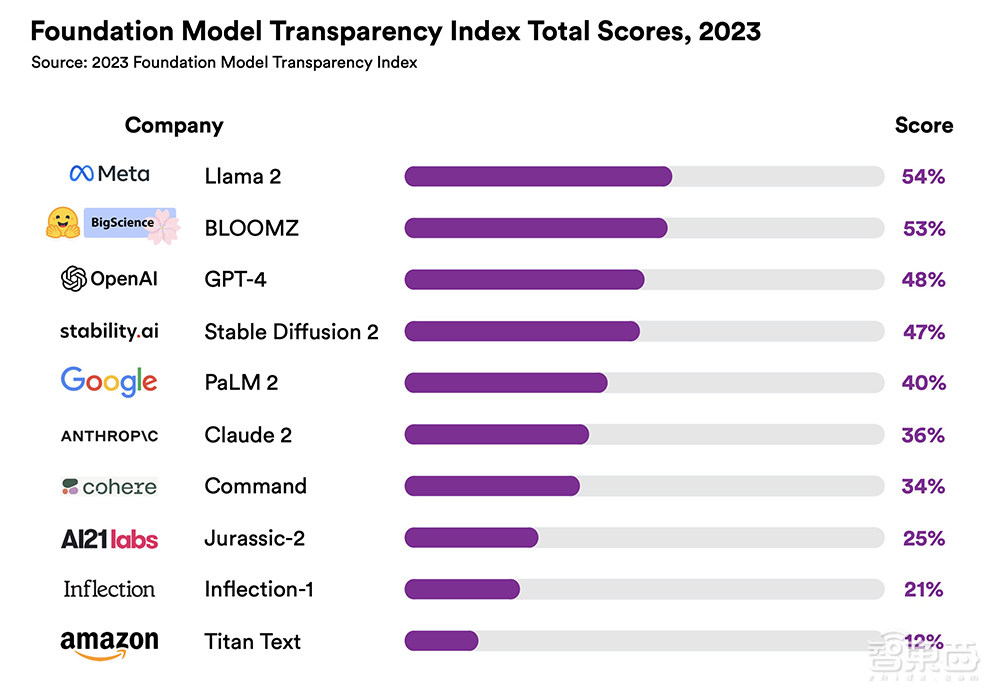
▲2023年基础模型透明度指数总分(图源:CRFM)
为了构建FMTI,团队定义了三个领域的100个指标,并将它们划分为13个子域进行了进一步分析。
虽然整体平均分仅为37分,但该团队称,100个指标中有82项获得了至少一个模型的满足,这意味着开发商可以通过采用竞争对手的最佳实践,来显著提高模型的透明度。
此外,开源基础模型在这项评级中取得领先地位。
在三家开源基础模型开发商Meta、Hugging Face和Stability AI中,有两家得分最高,这两家公司都允许下载其模型权重。Stability AI则紧随OpenAI之后,排名第四。
团队声明,在完成打分后,他们联系了这10家开发商进行反馈。所有10家开发商都对评分做了回应,其中8家提出了异议,上图是在解决了开发商的反驳之后的最终得分。
论文地址:https://crfm.stanford.edu/fmti/fmti.pdf
博客地址:https://crfm.stanford.edu/fmti
一、定义三大领域100个指标,通过13个子域进一步分析
在10家开发商的选取上,团队称主要基于其影响力、异质性(Heterogeneity)以及影响地位进行选择,并系统地收集了这10家公司截至2023年9月15日公开发布的信息。
为了建立FMTI,团队提出了100个不同的透明度指标,用于评估开发商在开发和部署基金会模型方面的透明度。这100个指标又被划分为三大领域:
1、上游(Upstream)
上游指标体现了构建基础模型所涉及的成分和过程,例如用于构建基础模型的计算资源、数据和劳动力等。
2、模型(Model)
模型指标体现基础模型的属性和功能,如模型的架构、能力和风险。
3、下游(Downstream)
下游指标体现基础模型的分发和使用方式,如模型对用户的影响、模型的任何更新以及管理其使用的政策。
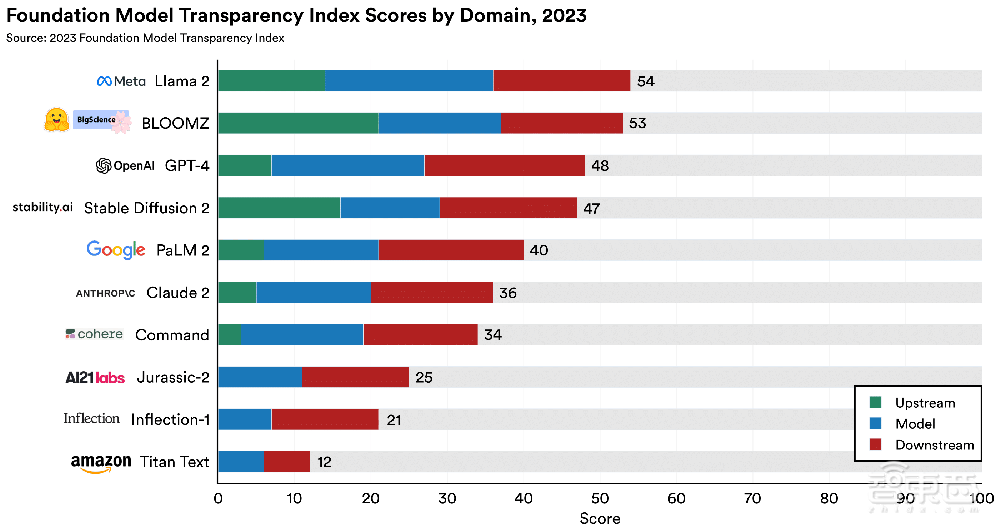
▲按三大领域划分,10个基础模型提供商获得的分数(图源:CRFM)
除了以上三个顶级域之外,团队还将指标分组为13个子域(Subdomain)。
这13个子域分别是数据(Data)、人力(Labor)、计算(Compute)、方法(Methods)、模型基础(Model Basics)、模型访问(Model Access)、性能(Capabilities)、风险(Risks)、缓解措施(Mitigations)、分布(Distribution)、使用政策(Usage Policy)、反馈(Feedback)、影响(Impact)。
子域为模型的评级提供了更精细、更直观的分析,如下图所示。图中每个子域都包含三个或三个以上的指标。
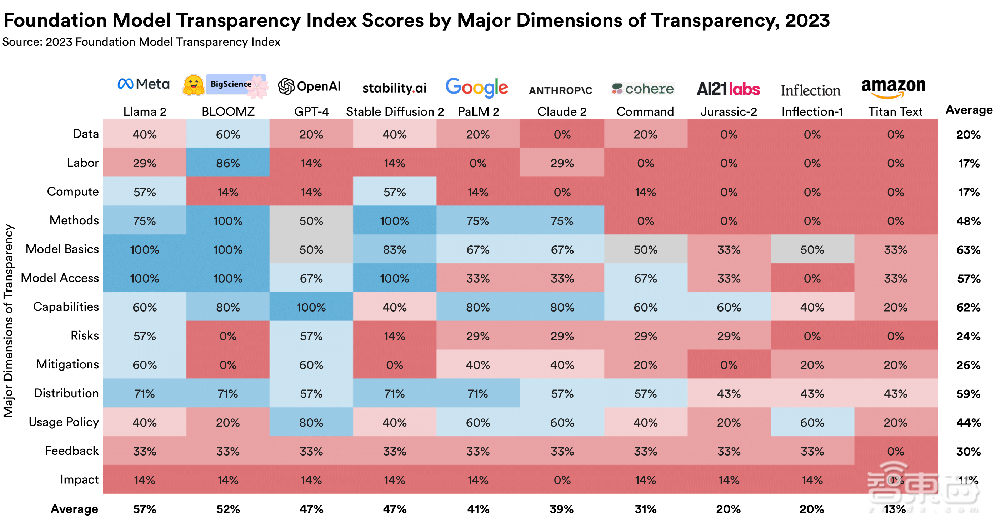
▲按13个子域划分,10个基础模型提供商获得的分数(图源:CRFM)
由图中数据可以看出,数据、人力和计算是开发人员的盲点。
在构建基础模型所需的资源方面,开发人员的透明度最低。所有开发人员在数据、人力和计算方面的得分总和仅占总分的20%、17%和17%。
其次,开发商在用户数据保护和模型基本功能方面更加透明。
开发商在用户数据保护、模型开发细节、模型功能和局限性相关的指标上得分较高,均超出60%。这反映出各开发商在如何处理用户数据及其产品基本功能方面的透明度达到了一定的基准水平。
此外,即使在开发商透明度最高的子领域,也仍有改进的余地。
没有一家开发商提供有关其如何提供、使用数据的过程信息。只有少数几家开发商在展示其模型的局限性,或让第三方评估模型能力方面是透明的。
虽然每个开发商都描述了其模型的输入和输出模式,但只有三家开发商披露了模型的组成部分,只有两家开发商披露了模型的大小。
二、开源vs闭源?13个子域中,开源基础模型9项领先
AI领域当下最具争议的辩论之一,就是AI模型应该开放还是封闭。
团队称,虽然AI的发布策略并非二元对立,但在指标分析中,他们将权重可广泛下载的模型视作开源模型。
该评级选取的10家开发商中,有3家是开源的积极践行者,他们的模型权重可供下载。其他7家开发商则采取闭源方式,其模型权重不能公开下载,必须通过API(应用程序接口)访问。
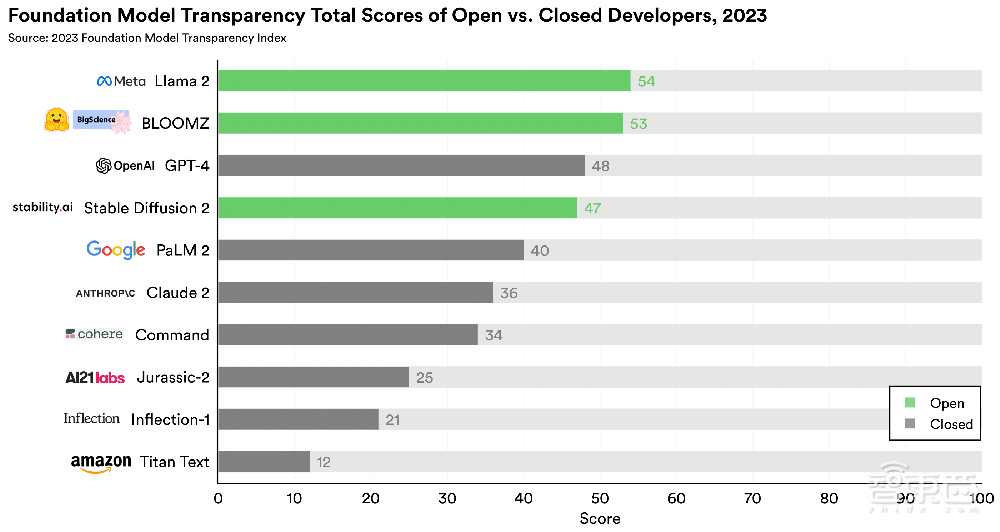
▲开源模型在评级中处于领先地位(图源:CRFM)
团队称,尽管闭源基础模型更容易满足该评级的许多指标,但开源基础模型在许多透明度方面获得了更高的评分。
例如,一些指标评估了下游使用的政策。由于闭源模型通常只通过API提供访问,因此他们可以更容易地分享与下游使用相关的信息,而开源模型的开发商则需要与下游部署者合作才能获得此类信息。
从理论上讲,这意味着闭源模型在这些指标上的得分要高得多,但团队称并没有发现实质性的差别。不过,一些闭源模型开发商在这些指标上的表现确实更好,其中以OpenAI为首。
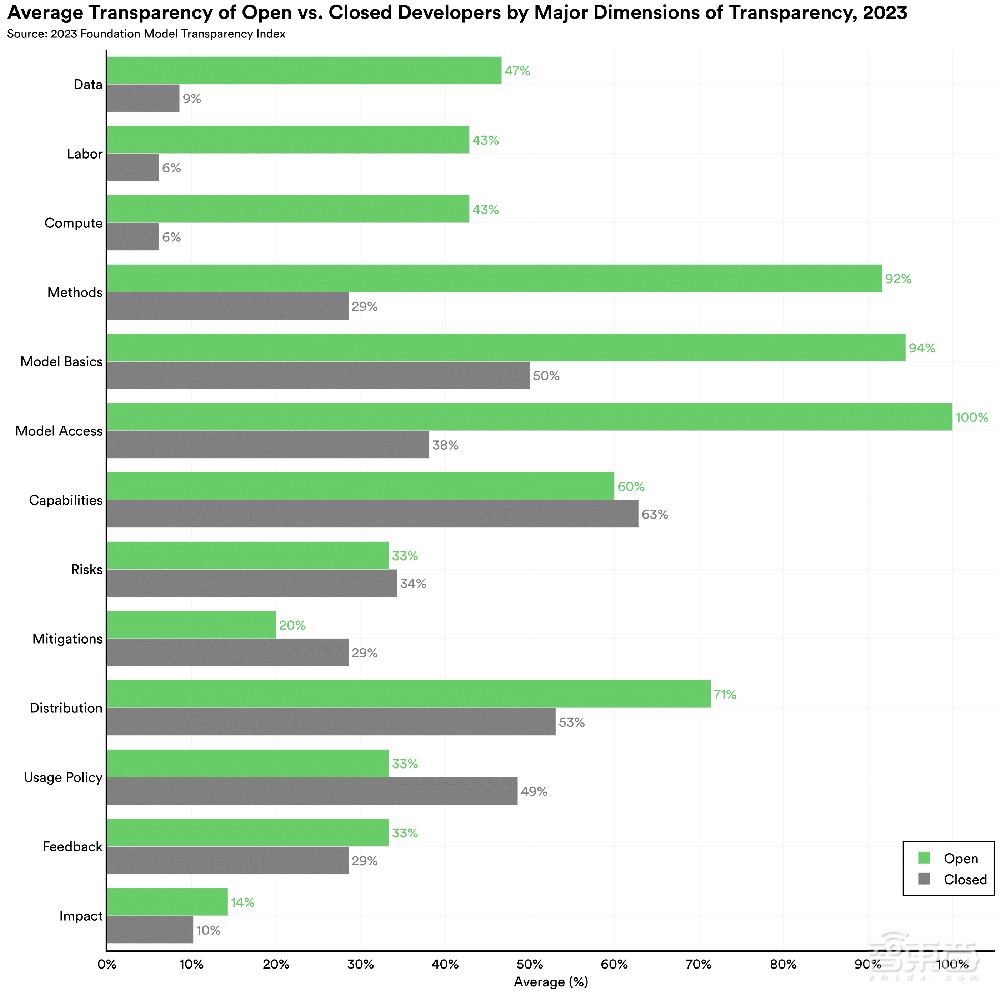
▲开源和闭源模型在13个子域评级中的平均透明度评分(图源:CRFM)
总分方面,开源基础模型开发商遥遥领先。
团队认为,开源模型与闭源模型之间的差距是由上游指标造成的,例如开发模型所使用的数据、人力和计算细节。近年来,许多闭源模型开发商对其模型训练方法越来越保密。
三、诉讼、竞争、安全,大模型开发商对于开源的忧虑
《纽约时报》的记者Kevin Roose谈道,当他询问AI公司的高管,为什么不公开分享更多关于他们模型的信息时,通常会得到三种答案。
其一是诉讼。
目前,包括OpenAI在内,已经有多家AI公司被作家、艺术家或媒体公司起诉,指控他们非法使用受版权保护的作品来训练AI模型。
大多数诉讼针对开源AI项目,或是披露了其模型详细信息的项目。AI公司的律师们担心,他们对模型的构建过程说得越多,就越会让自己面临昂贵、恼人的诉讼。
其二是竞争。
大多数AI公司认为,他们的模型之所以有效,是因为他们拥有某种秘诀——其他公司没有的高质量数据集、能产生更好结果的微调技术、能让他们获得优势的某种优化。
他们认为,如果强迫AI公司公开这些“秘方”,就会把他们来之不易的智慧拱手让给竞争对手,让对手轻而易举地复制这些智慧。
其三是安全问题。
一些AI专家认为,AI公司公开其模型的信息越多,AI的进步就会越快,因为每家公司都会看到竞争对手在做什么,并立即尝试通过建立更好、更大、更快的模型来超越他们。
他们认为,如果AI的能力发展得太快,所有人都会处于危险之中,因为社会没有那么多时间来监管和减缓AI的发展。
对此,斯坦福大学的研究人员并不相信这些回答。
他们认为,应该向AI公司施压,让它们尽可能多地发布有关基础模型的信息,因为用户、研究人员和监管机构需要了解这些模型是如何工作的,它们有哪些局限性、危险性。
结语:基础模型社会影响力不断攀升,透明度问题不可忽视
随着基础模型变得越来越强大,AI工具在人们日常生活扮演者愈发重要的角色,模型透明度问题不可忽视。
更多地了解这些基础模型的训练、部署方式,系统的工作原理,构建模型的数据集和数据来源等,将使监管机构、研究人员和用户更好地了解AI系统,对于保持开发商的责任感和了解基础模型的社会影响尤为重要。
AI革命不能在黑暗中进行。如果想让AI改变我们的生活,我们就必须了解它的“黑匣子”。
来源:CRFM、《纽约时报》
