










智东西(公众号:zhidxcom)
作者 | 程茜
编辑 | 心缘
智东西11月14日消息,昨日晚间,英伟达在国际超算大会SC23上宣布推出新一代AI计算平台NVIDIA HGX H200。
H200 GPU重点升级如下:
→ 跑70B Llama 2,推理速度比H100快90%;
→ 跑175B GPT-3,推理速度比H100快60%;
→ 首撘141GB HBM3e,是H100显存容量的近1.8倍;带宽4.8TB/s,是H100带宽的1.4倍;
→ 2024年第二季度发货。
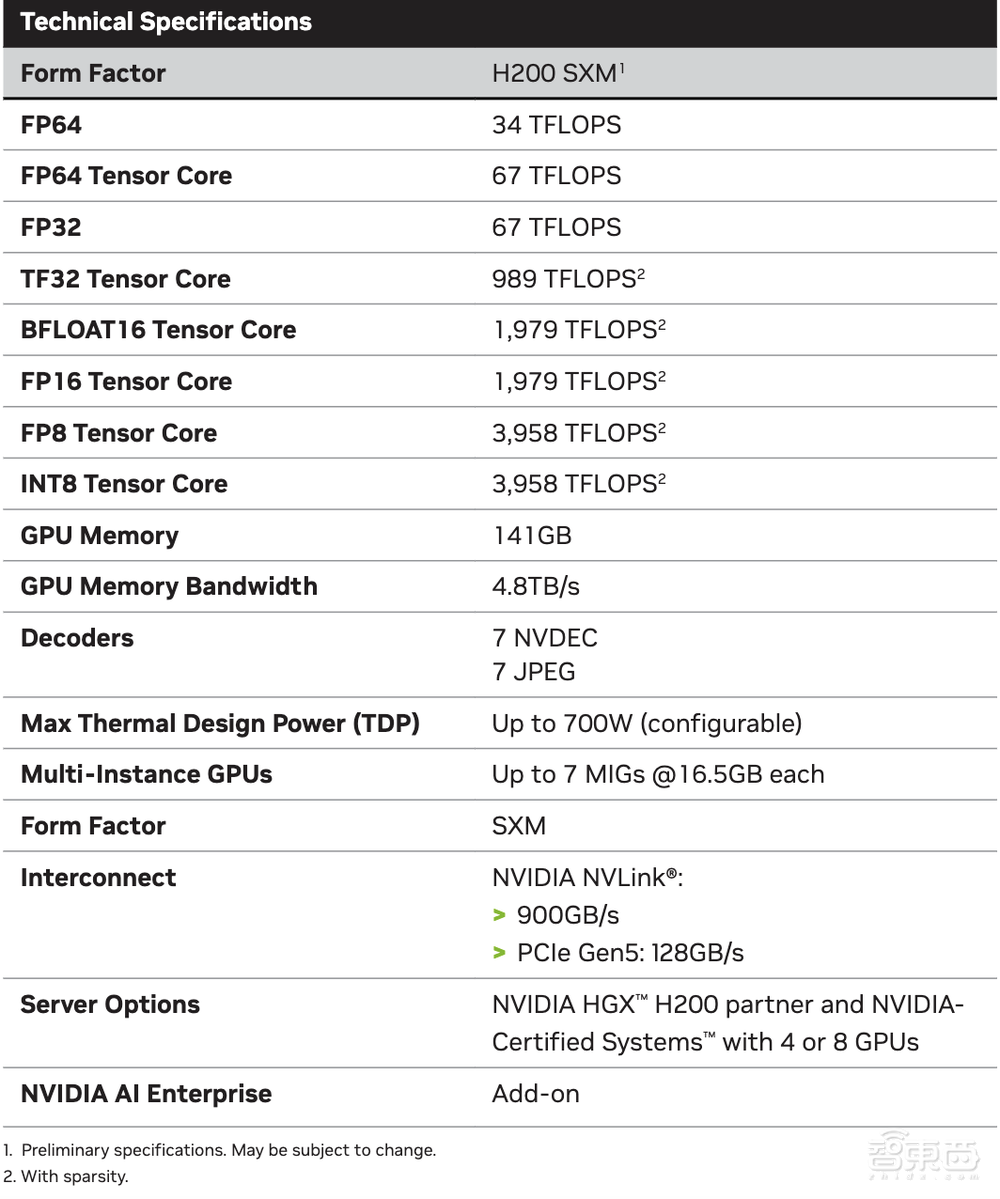
▲H200完整参数表
需注意的是,虽然都是“200”,但与此前英伟达发布的GH200 Grace Hopper超级芯片不同,GH200是英伟达Grace CPU与H100 GPU的组合版,而H200是新一代GPU芯片,为大模型与生成式AI而设计,因此相比H100主要优化的是显存和带宽,算力则与H100基本持平。
一、内置全球最快内存,大模型推理成本大降
HGX H200支持NVIDIA NVLink和NVSwitch高速互连,可支持超过1750亿参数规模模型的训练和推理,相比于H100,H200的性能提升了60%到90%。英伟达高性能计算和超大规模数据中心业务副总裁Ian Buck将其描述为“世界领先的AI计算平台”。

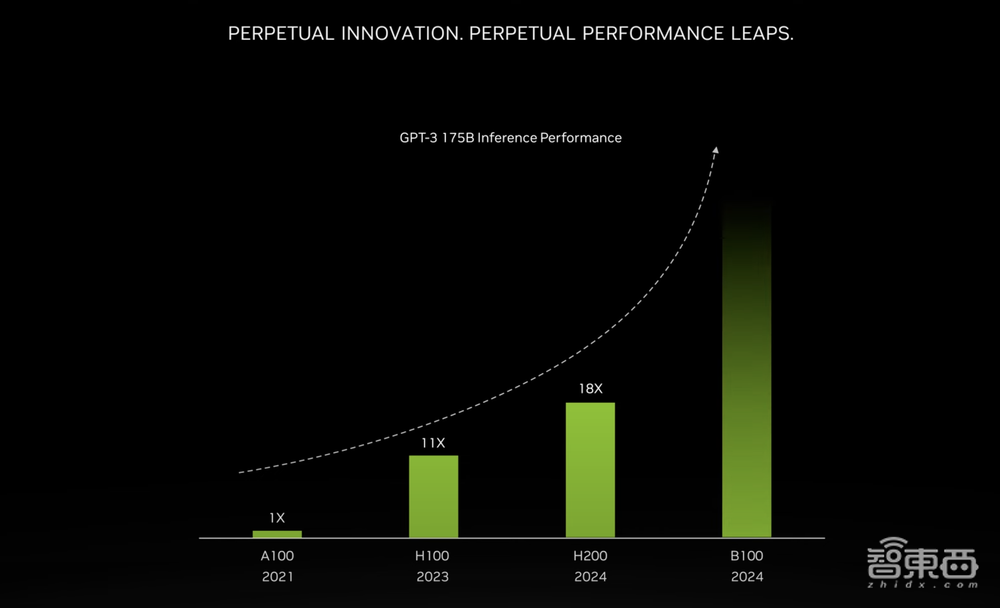
这也是首款内置全球最快内存HBM3e的GPU,英伟达的新闻稿写道,GPT-3的推理表现中,H100的性能比A100提高了11倍,H200 Tensor Core GPU的性能比A100提高到了18倍。
Buck称,英伟达将在未来几个月内继续增强H100和H200的性能,2024年发布的新一代旗舰AI芯片B100将继续突破性能与效率的极限。
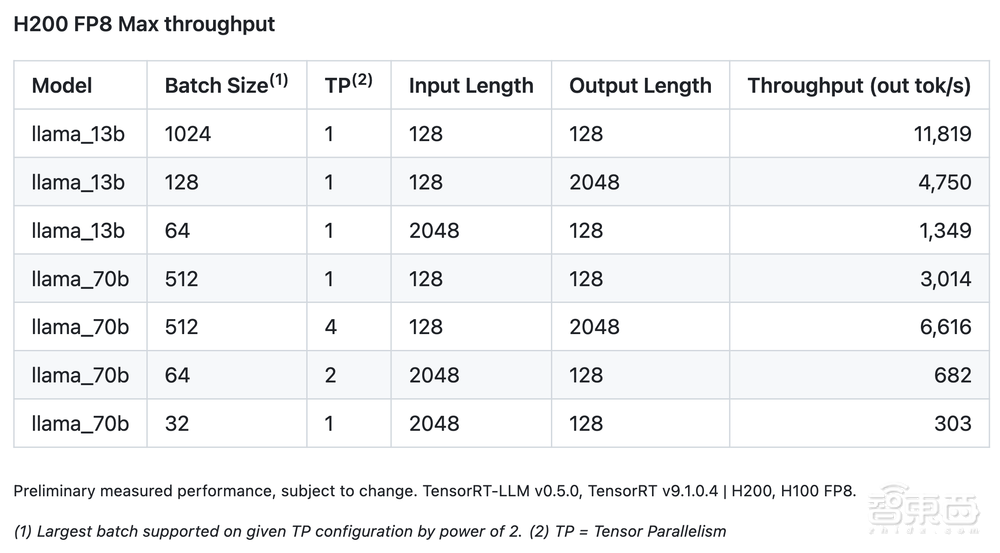
在生成式AI基准测试中,H200 Tensor Core GPU每秒在Llama2-13B大型语言模型上每秒快速通过1.2万个tokens。
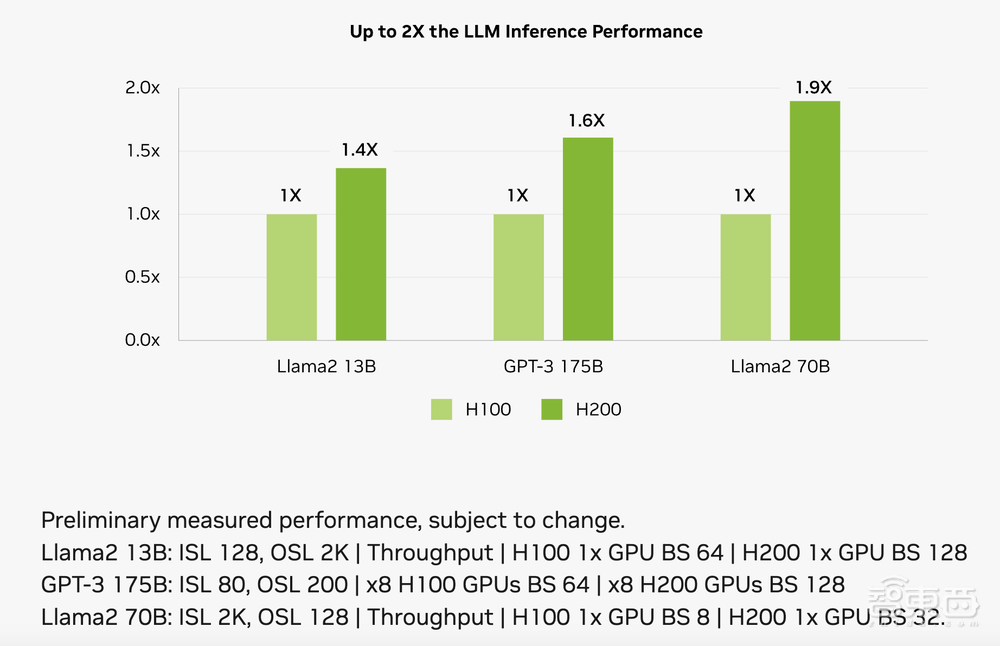
 单张H200跑700亿参数的Llama 2大语言模型,推理速度比H100快90%;8张H200跑1750亿参数的GPT-3大语言模型,推理速度比8张100快60%。
单张H200跑700亿参数的Llama 2大语言模型,推理速度比H100快90%;8张H200跑1750亿参数的GPT-3大语言模型,推理速度比8张100快60%。
在HBM3e的助攻下,NVIDIA H200能以每秒4.8TB的速度提供141GB内存,与NVIDIA A100相比,容量几乎翻倍,且带宽增加了2.4倍。
二、兼容H100,明年第二季度开始供货
英伟达还展示了一个服务器平台,可以通过NVIDIA NVLink互连连接四个NVIDIA GH200 Grace Hopper超级芯片,其具有四路和八路配置。
其中,四路配置在单个计算节点中配备了多达288个Arm Neoverse内核和16PetaFLOPS的AI性能,以及高达2.3TB的高速内存。

八路配置的HGX H200提供超过32PetaFLOPS的FP8深度学习计算和1.1TB聚合高带宽内存,可在生成式AI和HPC应用中实现最高性能。
当与具有超快NVLink-C2C互连的NVIDIA Grace CPU配合使用时,H200还创建了带有HBM3e的GH200 Grace Hopper超级芯片,这是可以服务于大规模HPC和AI应用的集成模块。
这些服务器主板与HGX H100系统的硬件和软件兼容。它还可用于英伟达8月份发布的采用HBM3e的新一代NVIDIA GH200 Grace Hopper超级芯片中。
基于此,H200可以部署在各种类型的数据中心中,包括本地、云、混合云和边缘。包括华硕、戴尔科技、惠普等在内的英伟达全球生态系统合作伙伴服务器制造商也可以使用H200更新其现有系统。
H200将于2024年第二季度开始向全球系统制造商和云服务提供商供货。
除了AI算力和云服务公司CoreWeave、亚马逊无服务器计算服务Lambda和云平台Vultr之外,AWS、谷歌云、微软Azure和甲骨文云将从明年开始成为首批部署基于H200实例的云服务提供商。
三、全球TOP 500超算榜,基于英伟达技术的系统达379个
此外,基于10月英伟达发布的TensorRT-LLM开源库,英伟达GH200超级芯片的速度是双插槽x86 CPU系统的110倍,能效是x86 CPU + H100 GPU服务器的近2倍。
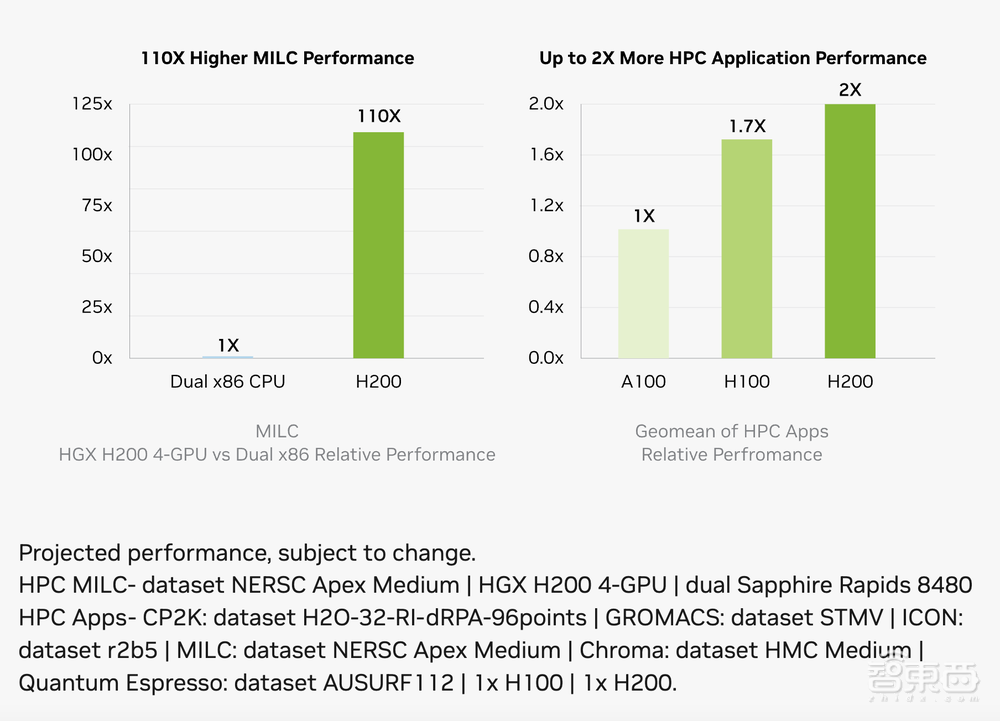
在全球TOP 500超算榜中,得益于由NVIDIA H100 Tensor Core GPU提供支持的新系统,英伟达在这些系统中提供了超过2.5ExaFLOPS的HPC性能,高于5月份排名中的1.6ExaFLOPS。
同时,新的全球TOP 500超算榜名单中包含了有史以来使用英伟达技术数量最多的系统为379个,而5月份的榜单中为372个,其中还包括了38台超级计算机。
英伟达加速计算平台还提供了强大的软件工具支持,能使开发人员和企业构建和加速从AI到HPC的生产就绪型应用程序,其中包括用于语音、推荐系统和超大规模推理等工作负载的NVIDIA AI Enterprise软件套件。
结语:围绕大模型核心痛点,剑指加速计算需求
生成式AI催生的大量加速计算需求仍然在不断增长,大模型开发和部署带来的算力需求也成为企业的核心痛点,性能更强的AI芯片仍然是当下大模型企业竞争的重点之一。
如今,英伟达再次围绕着生成式AI的开发和部署甩出了一系列硬件基础设施和软件工具,帮助企业突破大模型开发和部署的核心痛点,并且通过在数值、稀疏性、互联、内存带宽等方面的革新,不断巩固其在AI时代的霸主地位。
