








智东西(公众号:zhidxcom)
作者 | 香草
编辑 | 李水青
智东西11月14日报道,昨日下午,凤凰卫视于北京主办了主题为“数聚未来”的凤凰大模型数据研讨沙龙。会上,凤凰卫视融媒体研发副总经理冯伟发布了凤凰首批高质量数据集,包括中文访谈对话、正向价值对齐两个数据集,标志着凤凰卫视正式进军人工智能(AI)领域。
冯伟称,凤凰卫视之后将发布包括财经评论、视频问答、谈话活动、语音合成等方面的更多数据集,旗下AI训练平台也即将开放内测。
冯伟还公布了凤凰卫视2024年的行动计划时间表,其第2至4批数据集将分别于3月、7月、11月发布,AI训练平台将于5月上线,还将于4月和6月分别举办科技峰会和AI数据挑战赛。

▲凤凰卫视2024年AI行动计划
研讨会上,来自智谱AI、微博、中科闻歌等企业的行业代表分享了关于大模型数据、应用落地等方面的实践。
智东西等少数媒体对中科闻歌创始合伙人兼CTO曹家进行了采访。曹家向智东西分享了雅意大模型的最新进展,目前中科闻歌正在将词嵌入压缩技术、领域知识增强技术、安全可控内容生成技术等应用到最新的模型架构中,新架构的模型预计将在今年12月份发布。
凤凰AI数据官网地址:
https://www.feng-data.com
一、推出全新凤凰数据业务,发布两大中文特色数据集
冯伟谈道,凤凰卫视作为海外最大的华语传媒集团,一直坚持传播中华文化,覆盖全球电视观众超过5亿,海外新媒体受众接近1亿。
在AI革命下,以ChatGPT为代表的AI技术对传统的媒体和传播方式带来了新的挑战,也带来了新的机遇和可能性。
凤凰卫视经过几个月的调研,认为高质量的数据语料库是AI时代承载中华文化的一个新载体。
因此,凤凰卫视正式推出全新的业务——凤凰数据。
该业务主要包含两个方面,一是建设基于凤凰特色数据的高质量数据集市,二是以数据为中心的AI训练平台。

▲冯伟解读凤凰数据业务全景
凤凰的数据有什么特色?冯伟谈道,访谈和评论类的节目是其非常大的一个特色,这些节目中蕴含着大量的话题、知识和内容,尤其是针对同一话题的持续多轮问答,将为AI大模型的训练提供优质的语料库。此外,凤凰每天都生产着大量的多模态内容,为多模态大模型提供了优质的数据基础。
在版权方面,凤凰数据集基于凤凰自身内容进行加工生产,无论是从版权的合规,还是从内容的可持续性,都是凤凰数据的天然属性。而客观、中立,始终是凤凰作为一家媒体的核心报道原则,这也从数据源头保证了数据集的质量。
现场,冯伟发布了首批凤凰大模型——中文访谈对话数据集、正向价值对齐数据集。
中文访谈对话数据集基于凤凰卫视的访谈内容加工生成,规模达百万轮次,平均对话轮次超过30轮,包含传统文化、财经科技等话题,并具备完整的上下文信息。
除了上下文以外,数据集中还额外补充了知识政策、第三方信息或者一些专业的概念,凤凰也基于自有的知识体系,完善了数据集的安全合规,并持续更新。

▲冯伟发布中文访谈对话数据集
正向价值对齐数据集则是以凤凰本身以及权威团队的科研成果作为指导,由专业的内容团队人工撰写而成,规模达到10万问答对,每个问答对中包含正向和负向的相关回答,用于提升模型训练的鲁棒性。
冯伟称,该数据集也会定期持续更新,并丰富数据种类。面向多模态场景,凤凰后续也会发布不同模态的正向价值对齐数据集。

▲冯伟发布正向价值对齐数据集
此外,冯伟称公司近期正在紧锣密鼓地准备更多数据集,包括面向财经领域的财经评论数据集,面向视频理解领域的视频问答数据集、面向数字人领域的谈话动作和语音合成数据集等,旗下AI训练平台也即将开放内测。
根据公开的2024年行动计划时间表,第2批数据集将于明年3月发布,7月、11月将依次发布第3批、第4批数据集,AI训练平台将于5月上线,还将举行“Link+科技峰会”和“AI数据挑战赛”等系列活动。
面向高校及科研院所,凤凰卫视发布了“凤凰智媒AI筑巢计划”,提供部分数据集的免费授权,以助力学术研究和创新。凤凰AI数据官网于发布会当天正式上线,为行业客户提供数据集试用下载服务。
二、对话中科闻歌CTO曹家:大模型落地垂直领域需要行业认知,新模型架构下月发布
现场,中科闻歌创始合伙人兼CTO曹家作为嘉宾接受了智东西等少数媒体的采访。

▲曹家接受智东西等少数媒体的采访
当智东西问道,中科闻歌目前已经接洽了哪些领域的客户?中科闻歌的大模型方案能为他们带来哪些行业价值?相比于同类创企,公司的“护城河”是什么?
曹家称,中科闻歌的雅意大模型目前在安全、媒体、金融、舆情等领域落地较多。
对于媒体行业,雅意大模型可以提供选题推荐、辅助稿件写作以及辅助视频播报内容的制作。
对于金融行业,可以辅助金融快报的制作,以秒为单位将上市企业十几篇的公告转换为几十或百字以内的快报,如果由人来做的话,花费的时间成本将是小时级。
针对舆情场景,落地的场景包括对舆情、热点的感知、资讯的总结以及事件脉络的洞察,对这些内容的分析以及舆情研报的辅助撰写。
总的来说,雅意大模型一直聚焦到垂直品类、垂直场景的应用。
而谈到公司的“护城河”,曹家认为,针对这些领域应用场景的认知,是非常关键的一点。
通用大模型之所以很难向领域落地,很大的原因是在于“行话”的存在,领域内的专业知识需要长时间的积累。
中科闻歌现在能在安全、媒体、舆情、金融等领域直接落地,除了大量的领域知识外,还有对行业的深度认知。
此外,中科闻歌拥有大量面向行业应用的平台级产品与客户的业务进行深度绑定运作,在这种情况下,雅意大模型的能力在其中发挥的作用不再是“1+1”的效果,而是指数级增强。
当智东西问道,距离雅意大模型发布已5个月了,注意到官网文档里写道“公司正在重新设计大模型架构”,中科闻歌目前有什么可以分享的技术方面的进展或者时间表?
曹家称,雅意大模型从6月份发布以来,中间也进行了很多迭代,目前有很多新的技术在应用到新的模型架构当中,包括词嵌入压缩技术、领域知识增强技术、安全可控内容生成技术等,新架构的模型预计将在今年12月份发布。
在大模型推理加速上,中科闻歌雅意大模型采用新型基于形态学增强的词嵌入压缩技术,将模型Tokenizer压缩率提升高达20%,该技术可在同等规模算力下为大模型推理带来显著的性能提升。
关于与凤凰数据合作的潜在可能性,曹家谈道,一方面凤凰数据集的特色鲜明、质量很高、实用性强,特别是中文访谈对话、正向价值对齐等数据对大模型能力提升有极高价值;另一方面,雅意大模型在媒体领域应用中的优异表现,可助力凤凰数据高效构建更多高质量数据集。
三、生成式AI进入第二阶段,变革媒体等千行百业的内容生产方式
微博COO、新浪移动CEO、新浪AI媒体研究院院长王巍解读了生成式人工智能(AIGC)对媒体行业的影响,媒体应用AIGC技术面临的挑战以及数据赋能AIGC在微博多场景的应用。

▲微博COO、新浪移动CEO、新浪AI媒体研究院院长王巍
王巍称,AIGC将对媒体行业带来内容生产方式上的变革,内容生产从最初的专业生成内容(PGC),发展到用户生成内容(UGC),再到现在的AIGC,逐步向高质量、高效率、高产量的方向发展。
在这个过程中,AI成为重塑产业生态的关键环节。内容生产逐渐从AI赋能,过渡为AI原生。
但媒体应用AIGC技术也面临挑战,其中最为突出的便是“幻觉”和版权两大问题。
王巍认为,应当辩证地看待“幻觉”问题。一方面,创作就是在不断的试错中完善和创新的,要允许大模型出错;另一方面,在不同的应用场景中,如艺术创作,对错误的容忍度会更高一些。而版权问题,则需要立法机构出台相关的监管措施。

▲王巍解读媒体应用AIGC面临的幻觉挑战
王巍解读了微博在AIGC方面的应用实践,包括针对大V博主推出的AI创作助手、针对明星和粉丝群体推出的AI明星伴聊、针对剧综中的虚拟角色推出的虚拟角色账号以及基于AIGC技术构建的星座领域大模型等。

▲微博推出的AI创作助手
智谱AI副总裁刘佳分享了智谱AI的ChatGLM认知大模型在数据上的最佳实践。
刘佳谈道,随着2020年ChatGPT的问世,AIGC步入“第一阶段”。而现在,市场已进入“第二阶段”,AIGC开始在千行百业落地,“之前我们找到了锤子,现在我们要发现更多的钉子,让大模型的能力应用落地。”

▲智谱AI副总裁刘佳
刘佳称,2020年,智谱AI开启了大模型研发,2021年便发布了第一个自研百亿大模型。在智谱AI大模型的迭代过程中,刘佳认为,其2022年8月发布的开源双语千亿大模型GLM-130B是较为重要的节点,该模型也成为后续所有模型的基座模型。
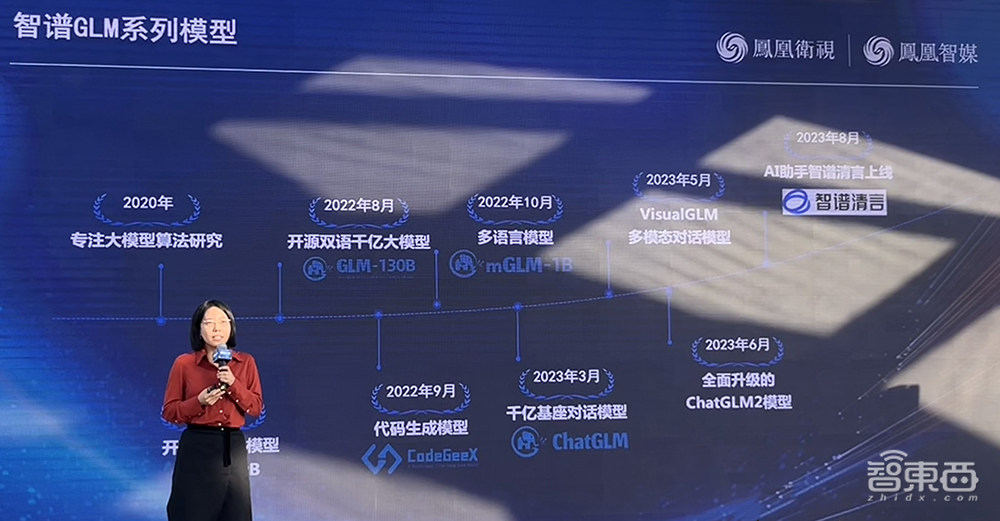
▲刘佳谈智谱GLM系列模型发展历程
上个月,智谱AI推出第三代基座大模型ChatGLM3及相关系列产品,瞄向GPT-4V进行了多模态理解能力、代码能力、网络搜索能力以及语义能力与逻辑能力的大幅增强。ChatGLM3还带来了全新的Agent智能体能力,并推出可手机部署的端侧模型ChatGLM3-1.5B和ChatGLM3-3B。
结语:大模型落地垂类领域,优质数据集不可或缺
数据作为大模型三要素之一,发挥着至关重要的作用。不同于网络上抓取的数据集,可能包含广告、冗余信息、有害信息等,凤凰数据此次发布的数据集从数据源头上对此类信息进行了隔绝,保障了数据质量。
随着OpenAI上周推出自定义GPT等,AI助手的构建门槛逐渐降低。不同于C端用户,B端用户对大模型解决方案的需求更加注重数据安全、合规等,对领域的认知、专业知识的长期积累可能成为AI企业有力的“护城河”。
未来,我们期待看到更多优秀的国内企业在AI领域崭露头角。
