








作者 | ZeR0
编辑 | 漠影
国产大模型芯片,又有了好消息。
作为“中国科技第一展”,深圳高交会正在如火如荼的举办,4295家企业展出了琳琅满目的高精尖科技成果,历来在高交会发布重磅产品的AI企业云天励飞,一如既往上了盘“硬菜”——
国产Chiplet大模型推理芯片DeepEdge10。
 ▲云天励飞董事长兼CEO陈宁博士发布Edge10芯片
▲云天励飞董事长兼CEO陈宁博士发布Edge10芯片
这是云天励飞迄今算力最强的旗舰AI芯片SoC,内置自研新一代神经网络处理器NNP400T,通过D2D高速互联Chiplet技术、C2CMesh互联架构实现算力扩展,能够支持千亿级参数大模型,落地于边缘设备和边缘服务器。
而“国产”,当属这颗芯片最吸睛的标签。
制程工艺是国产,基板是国产,D2D Chiplet先进封装架构是国产,RISC-V CPU IP、GPU IP是国产,云天励飞自研的NNP更是国产。
波谲云诡的国际环境中,中国企业采用海外先进芯片技术的可能性不断受限。今天,在国产供应链的襄助下,云天励飞证明了通过多重创新技术的组合拳,自主可控的AI芯片能够满足高算力、大内存的大模型推理需求。
 ▲三款不同规格的Edge10系列芯片(智东西拍摄)
▲三款不同规格的Edge10系列芯片(智东西拍摄)
云天励飞是怎么做到的?为何在自研芯片路上坚持至今?未来又有怎样的战略规划?在深圳高交会期间,智东西与云天励飞副总裁、芯片产品线总经理李爱军进行了深入交流。
一、大模型创新爆发时代,需要什么样的边缘推理芯片?
大模型正在颠覆生产力,海量数据和参数的运算需求、日趋丰富的应用场景带来了全新的计算泛式和计算要求,给AI芯片提出新的挑战。
一方面,多模态大模型成为大势所趋,带动推理算力需求激增;另一方面,OpenAI、微软等接连开放自定义GPT能力,掀起新一股生成式AI应用模型创新热潮,更加分散泛化的多元场景,需要大量边缘推理算力的支撑。
据云天励飞副总裁、芯片产品线总经理李爱军回忆,在推进芯片落地的过程中,云天励飞深刻体会到边缘计算场景存在算力碎片化、算法长尾化、产品非标化、规模碎片化的痛点。
追求单一场景极致PPA(性能、功耗、面积)的传统芯片方式,已经难以适应边缘计算场景下AI落地的需求。大模型的出现,为行业提供了算法层面的解决之道,因而日渐成为大势所趋。
那么让大模型在边缘计算场景实际落地,需要怎样的AI推理芯片?
一些方向已经是业界共识:既要有更高算力,又要增加更多的内存容量、更大的内存带宽,这样才能存得下、搬得快足够多的数据。同时,边缘计算对低功耗、低成本的要求更为苛刻。
除了支持大模型等AI计算任务,AI边缘推理芯片还承担了“落地应用最后一公里”的职责,需要具备较强的通用算力。
针对这些需求,云天励飞自主研发并推出了面向边缘计算全场景、基于国产工艺的大模型推理芯片平台——DeepEdge10。
二、全面兼容大模型新型计算范式,主控级SoC支持通用算法
李爱军告诉智东西,DeepEdge10芯片的研发始于2020年。得益于其算法部门在前沿AI算法方面的敏锐认知,云天励飞芯片团队预见到未来视觉算法会基于Transformer和注意力机制,因此对大模型计算方式进行了深度解构,着重考虑到如何通过灵活的架构设计来实现高效支持。

Edge10有4大技术加持:1)主控级SoC;2)新一代神经网络处理器,高效支持Transformer;3)D2D Chiplet架构,实现算力灵活扩展;4)C2CMesh互联扩展,支持千亿级参数大模型。
其主控级SoC集成了CPU、GPU、NPU、多媒体、显示、外设、安全等功能,支持传统的CNN、DNN、SLAM等算法,可满足绝大部分场景的控制需要。CPU、GPU均为国产IP。RISC-V CPU采用2+8核,主频最高达1.8Ghz;多媒体能力最大支持8K30视频编解码、2亿像素JPEG编解码;具备国际主流的硬件级安全性。

与支持大模型运行最为相关的,当属其自研的新一代神经网络处理器NNP400T。
NNP400T采用三维并行的矩阵计算架构,矩阵计算与矢量计算联合优化,大幅提升Softmax、Layernorm等算子的执行性能。
结合国产工艺的特点,NNP400T通过稀疏化、参数/数据压缩、低比特量化等措施,有效实现大模型带宽的极致优化。它还支持混合数据精度计算,包括INT8、INT16、FP16。
通过这些设计,芯片在支撑大模型推理时的能效比,可以被控制在合理的水平。
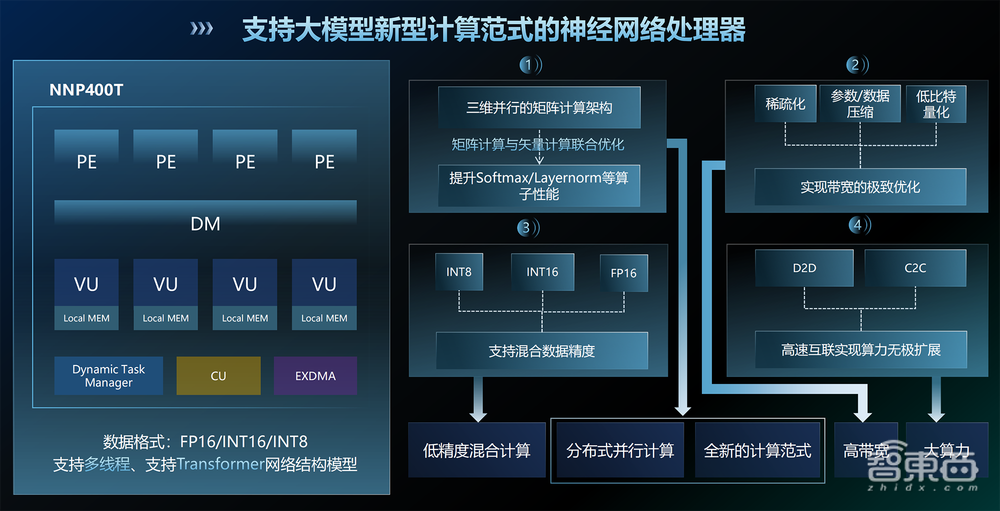
而在D2D、C2C Mesh高速互联架构的加持下,NPU算力能够无极扩展,同时统一内存最高可达512GB、统一内存带宽最高可达1920GB/s,能够满足大到千亿级参数大模型在边缘端部署的需求。
三、国产14nm Chiplet大模型推理芯片:国内首创,四大创新亮点
总体来看,面向边缘场景的大模型部署需求,DeepEdge10芯片平台具有4大创新亮点:

1、支持大模型新型计算范式
新一代神经网络处理器兼容Transformer,支持低精度混合计算、分布式并行计算。云天励飞现已向国内头部的AIoT芯片设计厂商、智慧汽车芯片设计厂商、服务机器人厂商、国家重点实验室等提供神经网络处理器的IP授权。
2、D2D Chiplet+C2C Mesh互联架构
据李爱军分享,在启动Edge10研发时,云天励飞芯片团队就在思考,如何在国产制程工艺与国际先进水平存在代差的情况下,通过其他技术手段追齐性能?像搭积木一样将不同制程、不同IP模块组合到一起的Chiplet先进封装思路,成为一条有希望的路径。
在无法采用国际先进制程的客观限制下,云天励飞与合作伙伴一起从三年前展开联合技术攻关,在D2D Chiplet技术上定制了一系列的IP,虽然成本、功耗会高一些,但实现了基于国产14nm工艺在单台设备跑大模型的能力。
 ▲云天励飞副总裁、芯片产品线总经理李爱军讲解D2D Chiplet架构
▲云天励飞副总裁、芯片产品线总经理李爱军讲解D2D Chiplet架构
D2D Chiplet通过在多Die间架起“高速公路”,在不牺牲时延的情况下能做到算力灵活扩展,可实现一次设计流片、多次封装,生产不同计算规格的芯片。C2C Mesh互联技术可实现各个计算节点之间的最短传输延迟,保证大模型推理达到最短时延,支持不同规格的大模型灵活部署。
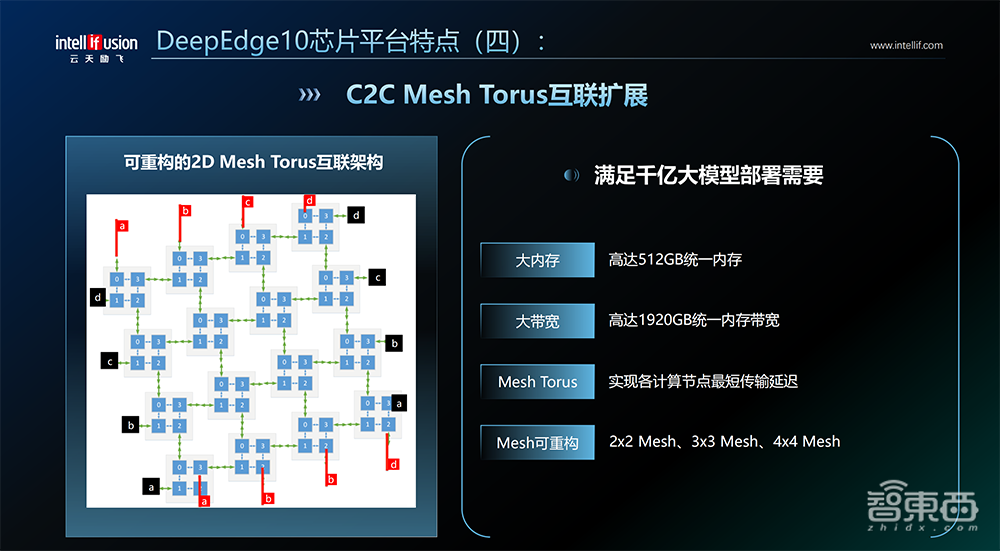
“在片内高速互联速度上,我们已经做到了14nm上的最好水平了。”李爱军说,“我们将立足国产工艺打造自主可控的AI芯片,这条路很艰难,我们会坚持不懈的走下去。”
3、支持大模型部署的异构多核软件栈
为了适应D2D/C2C架构,云天励飞构建了一套支持大模型部署的异构多核软件栈,包括设计了一套高效异构多核Syslink通信库,实现高效的D2D/C2C数据搬运管理、Mesh互联下的统一内存调度管理和模型分布式并行管理,因此能实现集群的大模型部署。
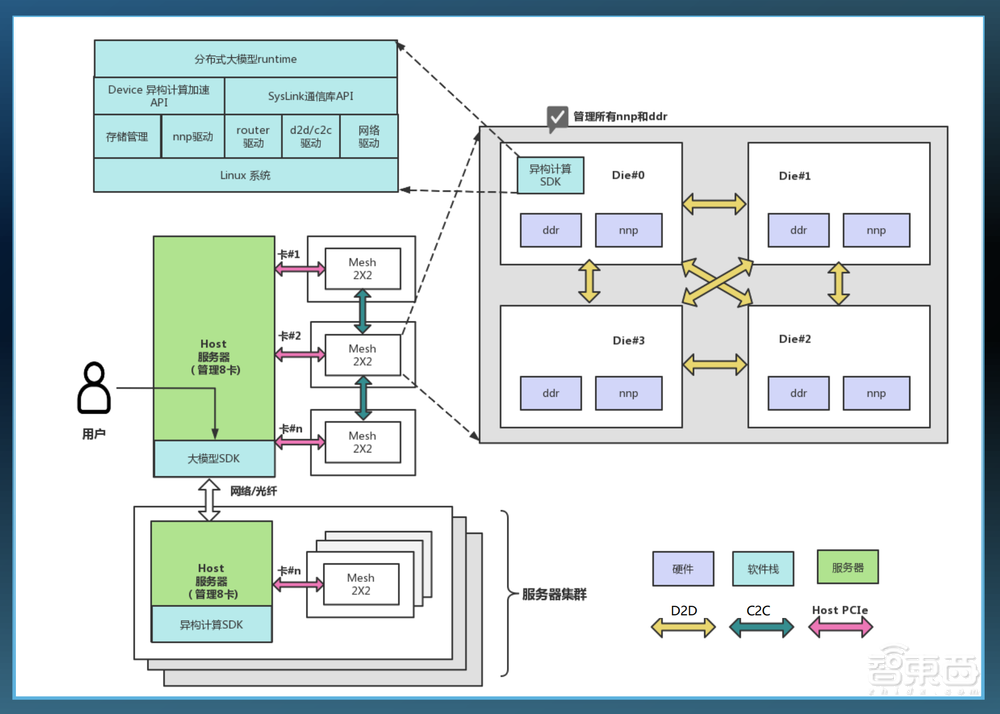
4、符合大模型演进趋势的统一工具链
云天励飞打造了一套符合大模型演进趋势的一站式统一工具链,通过分布式并行策略、基于硬件的流水线排布、先进的量化策略、多机并行的编译机制,来支持千亿级大模型快速部署。
DeepEdge10已支持超过100个主流开源模型,数量还在持续更新,同时支持云天励飞客户模型的定制部署。
四、单芯片算力最高48TOPS,加速卡能跑70亿参数大模型
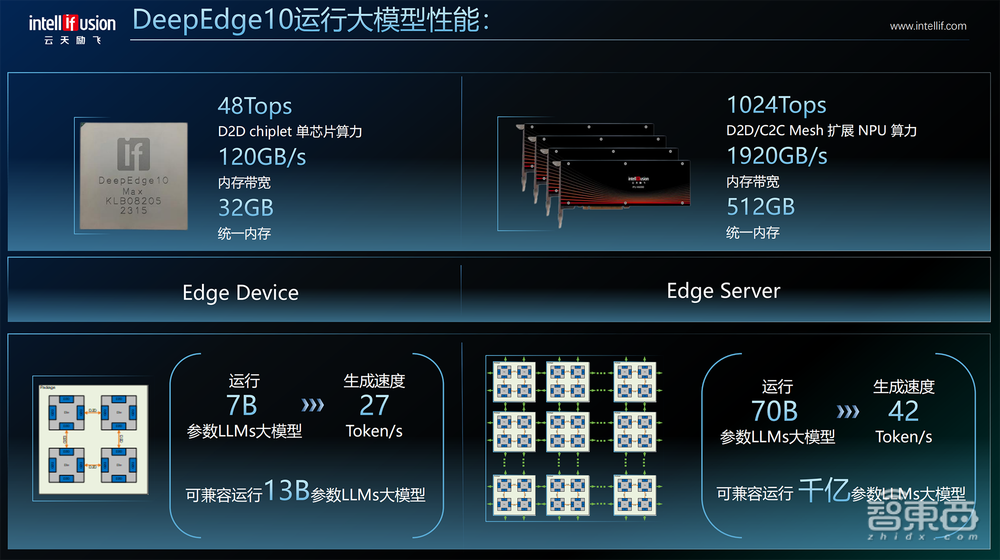
通过上述架构创新,云天励飞Edge10系列芯片有三种规格:Edge10C(8核CPU)、Edge10标准版(10核CPU)、Edge10Max(40核CPU),峰值算力分别为8TOPS、12TOPS、48TOPS,总体性能比上一代芯片高出20倍;统一内存最高32GB,内存带宽最高120GB/s。

其中,Edge10C和Edge10标准版适用于边缘计算领域;Edge10Max适用于边缘CV大模型,单芯片能跑SAM视觉大模型。
相应的出货形态包括芯片、板卡、盒子、加速卡、推理服务器等,可广泛应用于AIoT边缘视频、移动机器人等场景。
Edge10适用于边缘设备和边缘服务器,在Edge Device上运行70亿参数大语言模型,生成速度可达27Tokens/s;能够兼容运行130亿参数大语言模型。
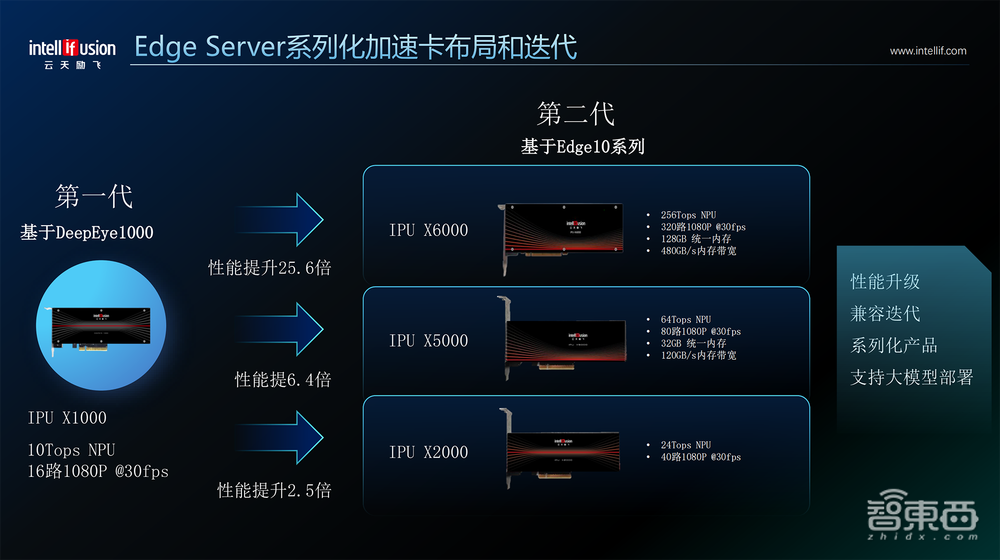
第一代Edge Server基于DeepEye1000小算力芯片。基于Edge10系列芯片的IPU X2000、IPU X5000、IPU X6000加速卡,算力从24TOPS到256TOPS。
经C2C Mesh扩展,AI算力能达到1024TOPS,在Edge Server上运行700亿参数大语言模型,可实现42Token/s的生成速度;能够兼容运行千亿级参数大语言模型、百亿级参数视觉大模型,未来将兼容多模态大模型。
五、落地边缘计算三大应用场景,助攻AI电脑跑AIGC应用
DeepEdge10芯片布局边缘计算的三大芯片平台解决方案:感知计算、视频高密、大模型推理。
感知计算场景下,基于Edge10和Edge10Max芯片,云天励飞打造了能支持多传感器接入的主板方案,可以满足机器人自主导航和运动、无人机自主避障与导航、汽车智能安全驾驶控制、家居系统智能控制等应用场景的感知要求。
视频高密场景下,芯片、加速卡结合云天励飞过去几年在公共安全领域及行业领域积累的专业算法和长尾算法,共同形成了面向嵌入式边缘计算端设备的单芯片主控方案和加速卡方案,这些方案可以满足智能化园区管理、消防应急管理、智慧物业、智慧城市治理等场景的视频高密需要。
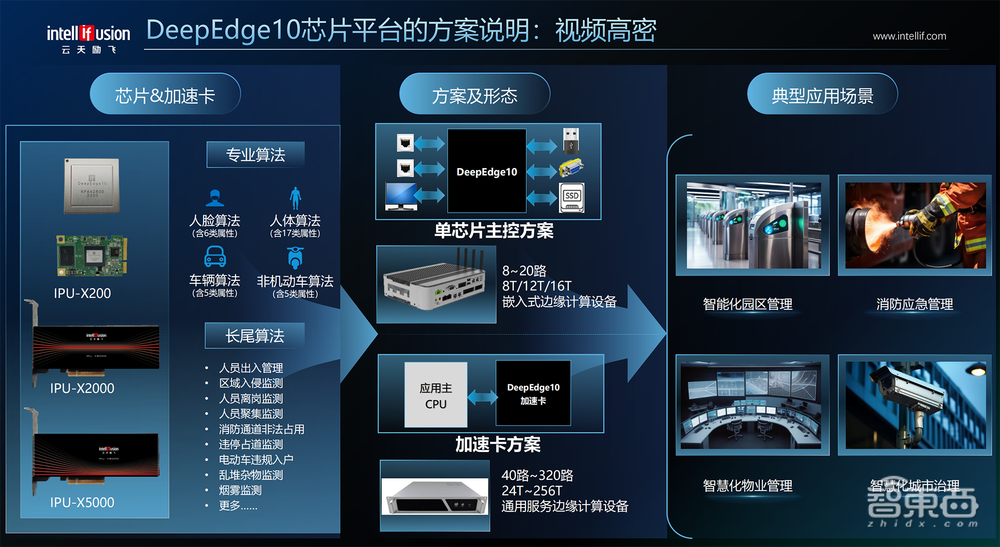
像IPU X6000单卡可支持320路视频处理,算力有256TOPS。一台服务器可以插8张卡,相当于实现超过2500路的视频高密方案。
大模型推理方面,在Edge Device上,Edge10可作为当前信创PC的算力协处理器方案,把大模型的能力应用到传统信创PC上,让信创PC能跑AIGC办公应用,包括文案生成、代码生成、智能决策、增强设计等。

在Edge Server上,基于IPU X6000的算力加速卡方案,可实现1~8卡灵活扩展的服务器部署,满足行业大模型和场景大模型集中化的推进。
据李爱军透露,云天励飞会优先选择在一些边缘计算场景的头部行业玩家进行深度合作,提供Edge10系列芯片和产品,再逐步对外开放。
六、披露八年自研芯片路线图,以三年为周期进行迭代
云天励飞自2014年成立至今,一直坚持自主研发芯片,沉淀“算法芯片化”的核心能力,其核心芯片团队设计经验平均超过14年。
“算法芯片化”并不是简单的“算法+芯片”,而是云天励飞基于对场景的理解,以及对算法关键计算任务在应用场景中的量化分析,将芯片设计者的理念、思想与算法相融合的AI芯片设计流程,能够让AI芯片在实际应用中发挥更优的效果。
在“算法芯片化”核心能力的支持下,云天励飞已完成3代指令集架构、4代神经网络处理器架构的研发,且已陆续商用。
据云天励飞董事长兼CEO陈宁博士分享,从第一代芯片起,云天励飞的自研芯片就一直定位在边缘计算,与其系统产品相辅相成,落地到智慧城市、智能交通、智能制造、智慧教育、智能配送、边缘计算模型等场景中。
其第一代芯片DeepEye1000在2020年初实现商用,过去四年多应用在人脸门禁和AI相机、工业AI相机和安全PC、商业机器人等边缘计算设备中。最新推出的DeepEdge10边缘推理芯片,采用云天励飞的第二代异构多核架构、第一代Chiplet架构,相较上一代性能整体提升。
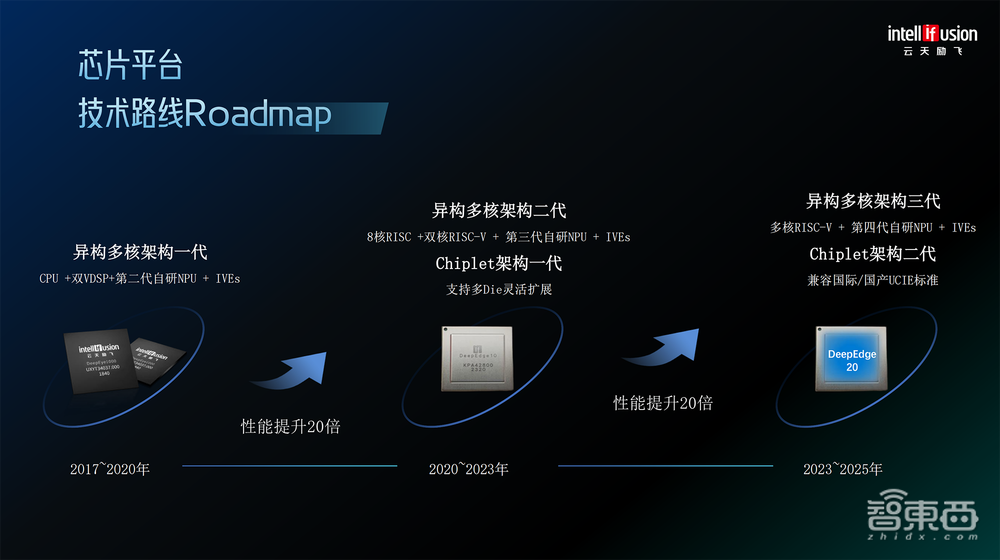
“我们基本上是以三年为一个周期,相信2025年我们将会推出DeepEdge20,推动我们的性能以20倍以上的速度进行提升。”陈宁说。
按其“剧透”,下一代DeepEdge20芯片将采用第三代异构多核架构、第二代Chiplet架构,内置多核RISC-V、第四代自研NPU。
七、拥有近30家算法芯片化合作伙伴,已开放超过100种算法
一路走来,云天励飞神经网络处理器的核心技术和芯片的能力逐步获得行业内合作伙伴的认可。
其自研芯片曾先后获得工信部、发改委、科技部三大部委人工智能专项,并获得吴文俊人工智能专项奖芯片项目一等奖,已被国内顶尖芯片设计公司采用,芯片进入了大规模应用中。
李爱军认为,国际AI芯片巨头最坚不可摧的壁垒是生态,走兼容路线只是短期内的权宜之计,从长远来看,国内芯片企业必须实打实地持续投入软件研发和生态构筑。
云天励飞现有近30家算法芯片化合作伙伴,并将合作伙伴需求植入下一代芯片中;还打造了开放的算法应用生态,所有使用云天芯片产品的合作伙伴,均可在线下载更新其超过100种算法。
在2020年的高交会上,云天励飞首次公布自进化城市智能体战略。
而驱动自进化城市智能体发展的核心逻辑,是打造“应用生产数据、数据训练算法、算法定义芯片、芯片规模化赋能应用”的数据飞轮。
对于云天励飞自身来说,芯片是决定AI应用广度与深度的关键载体,也是自进化城市智能体建设的重要算力支撑。今天发布的大模型推理芯片,是其自进化城市智能体底层核心算力平台补齐大模型能力的重要成果展示。
陈宁谈道,未来,云天励飞将继续加大自主研发力度,立足自主可控,以自研“芯”,为自进化城市智能体发展提供强大引擎。
结语:大模型正向边缘端渗透,AI推理芯片研发需结合本土落地需求
生成式AI和大模型的应用落地正逐步从云端向边缘和终端进行渗透,最新一代的智能手机、个人电脑(PC)等边缘端侧设备已经具备在本地部署运行百亿级参数大模型的能力。
在陈宁看来,训练、生产大模型不是目的,千行百业的落地和应用才是最终目的,所谓边缘,不管是机器人、无人驾驶汽车、新型智能传感,还是未来的智慧硬件和脑机接口芯片,需要的都是大模型推理芯片。
今天,大模型推理芯片还是百家争鸣的景象,尤其在中国,我们要考虑如何基于国产工艺进行技术攻关和生态建设,打造出契合本土落地需求的AI芯片。
展望未来,陈宁预言,未来三年,可能会有80%以上的企业将运行在大模型之上;未来五年,机器人和数字人的数量将超过人类的数量;未来七年,也就是到2030年,大模型的智慧程度将超过人脑,GPT10.0的版本将会具备1万亿的参数体量,相当于是人脑末梢神经连接的数量。
“我们正在踏入第四次工业革命的开端,未来已来。”他也透露了云天励飞将会在今年年底发布大模型,说敬请期待。
