








今年9月起,智东西公开课品牌全新升级为智猩猩。智猩猩定位硬科技讲解与服务平台,提供公开课、在线研讨会、讲座、峰会等线上线下产品。
「AI新青年讲座」由智猩猩出品,致力于邀请青年学者,主讲他们在生成式AI、LLM、计算机视觉、机器学习等人工智能领域的最新重要研究成果。
AI新青年是加速人工智能前沿研究的新生力量。AI新青年的视频讲解和直播答疑,将可以帮助大家增进对人工智能前沿研究的理解,相应领域的专业知识也能够得以积累加深。同时,通过与AI新青年的直接交流,大家在AI学习和应用AI的过程中遇到的问题,也能够尽快解决。
「AI新青年讲座」现已完结231讲;有兴趣分享学术成果的朋友,可以与智猩猩教研产品团队进行邮件(class@zhidx.com)联系。
LLaVA 是第一个在图像理解和推理方面具有类似 GPT-4V 级别的能力的开源大模型。在去年7月份,LLaVA 一作、美国威斯康星大学麦迪逊分校在读博士柳昊天,曾围绕主题《基于视觉指令调整的多模态聊天机器人 LLaVA》对 LLaVA 进行深度讲解。在今年的NeurIPS 2023 上,LLaVA 也获得了 Oral。

结合最近的 AI Agent,柳昊天博士联合清华大学的刘世隆博士等人最新又提出了 LLaVA-Plus,使用插件(视觉工具)提升多模态大语言模型的视觉能力,扩展了多模态大语言模型 LLaVA,使其支持了包括检测、分割、检索、生成、编辑在内的多种视觉能力。
LLaVA-Plus 维护着一个技能库,其中包含各种视觉和视觉语言预训练模型(工具),并且能够根据用户的多模式输入激活相关工具,以即时组合执行结果来完成许多现实任务。通过实验也验证了 LLaVA-Plus 的有效性,在多个基准测试中取得了持续改进的结果,特别是在 VisIT-Bench 上达到了的新 SoTA。
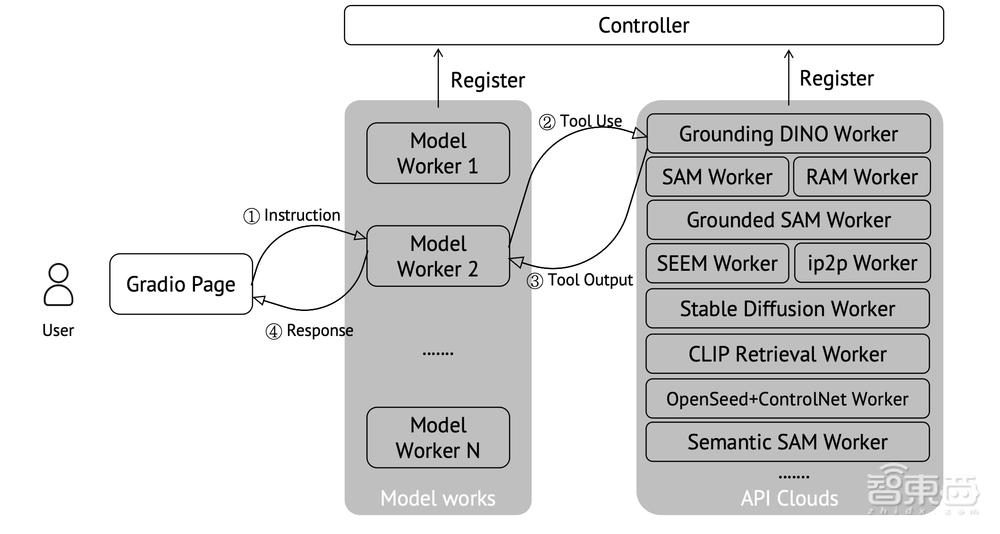
12月26日晚7点,LLaVA-Plus 一作、清华大学在读博士刘世隆将参与到「AI新青年讲座」第232讲,主讲《LLaVA-Plus:学习使用视觉工具插件的多模态智能体》。
讲者
刘世隆,清华大学在读博士;导师朱军教授;长期在粤港澳大湾区数字经济研究院(IDEA Research)实习,接受张磊教授指导;曾在 Microsof t实习;主要研究方向包括目标检测和多模态学习,曾获得 CCF-CV 学术新锐,代表工作包括 DAB-DETR、DINO 和 Grounding DINO 等。
第232讲
主 题
《LLaVA-Plus:学习使用视觉工具插件的多模态智能体》
提 纲
1、AI Agent 的研究概述
2、基于大语言模型的多模态智能体构建方法
3、LLaVA-Plus 多模态能力的插件实现
4、LLaVA-Plus 的 SoTA 性能验证
直 播 信 息
直播时间:12月26日19:00
直播地点:智东西公开课知识店铺
成果
论文标题:《LLaVA-Plus: Large Language and Vision Assistants that Plug and Learn to Use Skills》
论文地址:https://arxiv.org/pdf/2311.05437.pdf
开源代码:https://github.com/LLaVA-VL/LLaVA-Plus-Codebase
