








「自动驾驶新青年讲座」由智猩猩企划,致力于邀请全球知名高校、顶尖研究机构以及优秀企业的新青年,主讲在环境感知、精准定位、决策规划、控制执行等自动驾驶关键技术上的最新研究成果和开发实践。
「自动驾驶新青年讲座」目前已完结33讲;有兴趣分享的朋友,可以与智猩猩教研团队进行邮件(class@zhidx.com)联系
3D 场景感知对于自动驾驶的安全性至关重要。来自新加坡国立大学的博士生孔令东等人在 NeurIPS 2023 上提出了一个新颖的点云无监督预训练框架 Seal,该框架旨在利用视觉基础模型 (VFM) 分割不同的激光雷达点云序列。
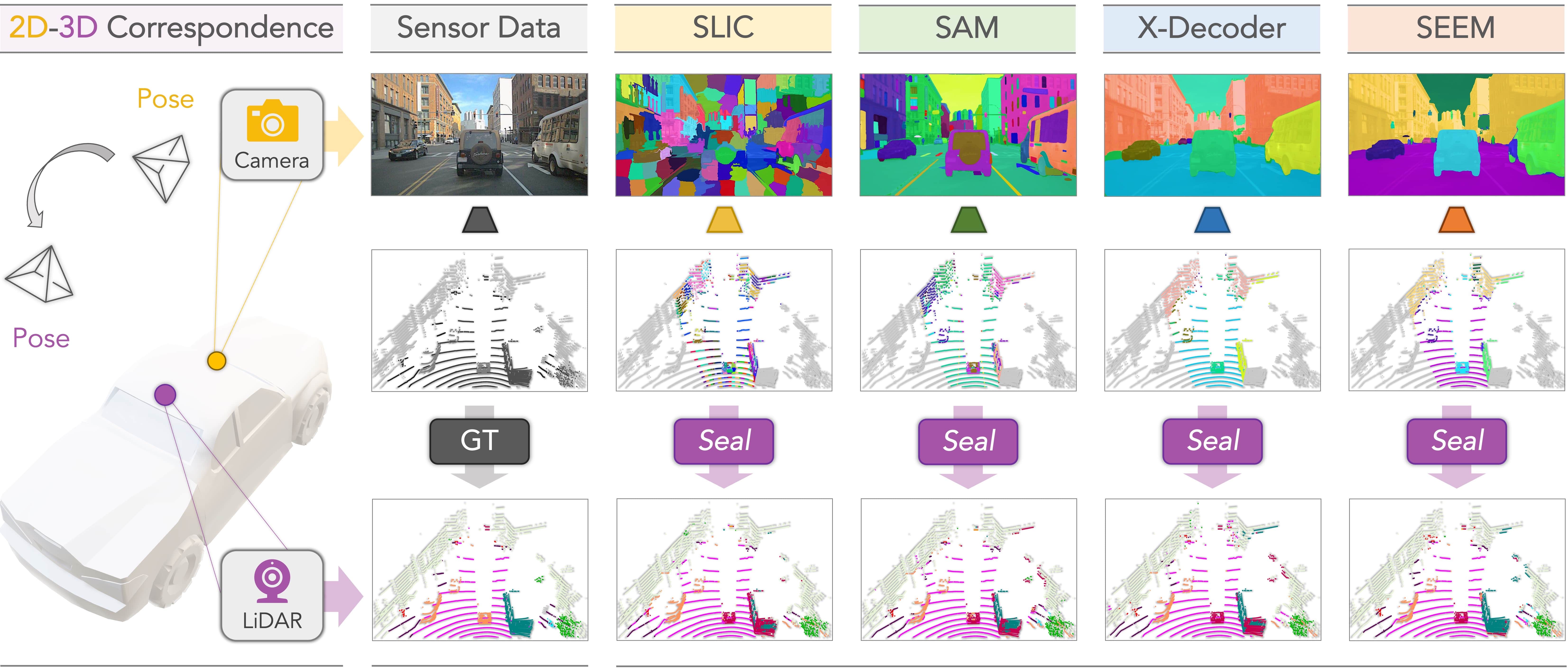
Seal 具有以下三点特性:
1) 可扩展性:其将VFM中的知识直接蒸馏到点云上,从而无需在预训练期间使用任何2D 或3D 标注。
2)一致性:其在相机到激光雷达和点到簇两个正则化阶段分别进行了空间和时间约束,以促进跨模式表示学习。
3) 通用性:Seal能够将现有模型中的知识迁移到涉及不同类型点云的下游任务中,包括了来自真实/合成、低/高分辨率、大/小规模以及干净/损坏数据集的点云等。
在共11个不同的点云数据集上进行的广泛实验,也验证了 Seal 的有效性和优越性。 该成果已被 NeurIPS 2023 收录为 Spotlight。

除了 Seal,在如何提升 3D 场景感知可靠性上,孔令东还分别提出了首个关注于使用半监督信号进行激光雷达点云语义分割的框架 LaserMix 和包含恶劣天气条件、外部干扰和内部传感器故障引起的八种损坏类型的 3D 感知模型测试基线 Robo3D 。
1月11日晚7点,「自动驾驶新青年讲座」第34讲邀请到 Seal 一作、新加坡国立大学在读博士孔令东参与,主讲《运用视觉基础模型分割「任意」激光雷达点云》,包括 Seal、LaserMix 和 Robo3D 等成果内容。
讲者
孔令东,新加坡国立大学计算机系在读博士;研究方向包括3D场景感知、域适应和无监督表征学习等;曾于Motional进行自动驾驶场景感知方向的研究实习;相关研究工作已发表于TPAMI、CVPR、ICCV、NeurIPS和ICRA等国际期刊和会议中,并入选Highlight、Spotlight和Best Workshop Paper。
第34讲
主 题
《运用视觉基础模型分割「任意」激光雷达点云》
提 纲
1、大模型在自动驾驶点云分割中的应用
2、半监督激光雷达点云语义分割 LaserMix
3、使用 VFM 的无监督预训练点云分割框架 Seal
4、Seal 的有效性和优越性验证
5、3D 场景感知的可靠性探索
直 播 信 息
直播时间:1月11日19:00
直播地点:智东西公开课知识店铺
成果
论文标题
《Segment Any Point Cloud Sequences by Distilling Vision Foundation Models》
《LaserMix for Semi-Supervised LiDAR Semantic Segmentation》
《Robo3D: Towards Robust and Reliable 3D Perception against Corruptions》
论文地址
https://arxiv.org/pdf/2306.09347.pdf
https://arxiv.org/pdf/2207.00026.pdf
https://arxiv.org/pdf/2303.17597.pdf
代码链接
https://github.com/youquanl/Segment-Any-Point-Cloud
https://github.com/ldkong1205/LaserMix
https://github.com/ldkong1205/Robo3D.
