








智东西(公众号:zhidxcom)
作者 | 李水青
编辑 | 心缘
智东西1月25日报道,昨日,岩山科技旗下创企岩芯数智(Rock AI)推出国内首个非Attention机制的大模型Yan,也是业内少有的非Transformer架构大模型。
岩芯数智CEO刘凡平介绍,Yan是一个通用大语言模型,拥有相较于同等参数Transformer的7倍训练效率、5倍推理吞吐、3倍记忆能力,同时支持CPU无损运行、低幻觉表达、100%支持私有化应用。

标准的Transformer架构模型在消费级显卡微调,难以达到大规模商业化的目标;训练至少花费数百万以上,对企业来说并不经济划算。刘凡平透露,基于Yan架构,仅需投入50万元的训练成本,就可以拥有百万参数级的大模型。Yan支持100%支持私有化部署,支持CPU服务器运行,能在端侧设备上流畅运行。
智东西与少数媒体对岩芯数智CEO刘凡平进行了采访。岩芯数智对标业内的什么大模型?Yan有什么优势和劣势?
刘凡平告诉智东西,Yan还没有真正对标谁,今天大家看到对比Transformer的一些数据是用Llama 2的数据进行的比较,能看到性能差异。团队对标的是底层技术架构,而不是某一产品。
优势和劣势方面,今天介绍的效果是通过大量实验验证测试出来的,它确实在训练效率、推理效率、记忆能力、幻觉表现了很强的优势,包括CPU上运行。团队自己从理论上(非应用层面)推导的劣势,可能在上百k超长文本上会有语义上的缺陷。
当下,业内同时出现了Mamba、RWKV等非Transformer架构的大模型。刘凡平说,参考Mamba与Llama 2对比的数据图表,Yan的数据比Mamba要好。
一、比Mamba数据好,效率7倍于Transformer
Attention机制,简单来说,是通过一种非线性的矩阵方式表达更多东西。在标准Attention机制下,计算复杂度较高,已经成为大模型领域的一大难题。
岩芯数智技术负责人杨华解读,Yan不采用Attention机制,也不采用RNN序列,而是建立一种线性的向量方式,将计算复杂度大幅降低,做到线性时间复杂度,还能做到常量的空间复杂度,从而提高大模型的性能和效果。

1、训练效果:预测准确率提高17%
以机器翻译为例,对Yan与Transformer架构的表现对比,在训练集和验证集上,Yan的损失值都要低于Transformer。Yan的训练效率是Transformer的7倍,消耗的资源更低。
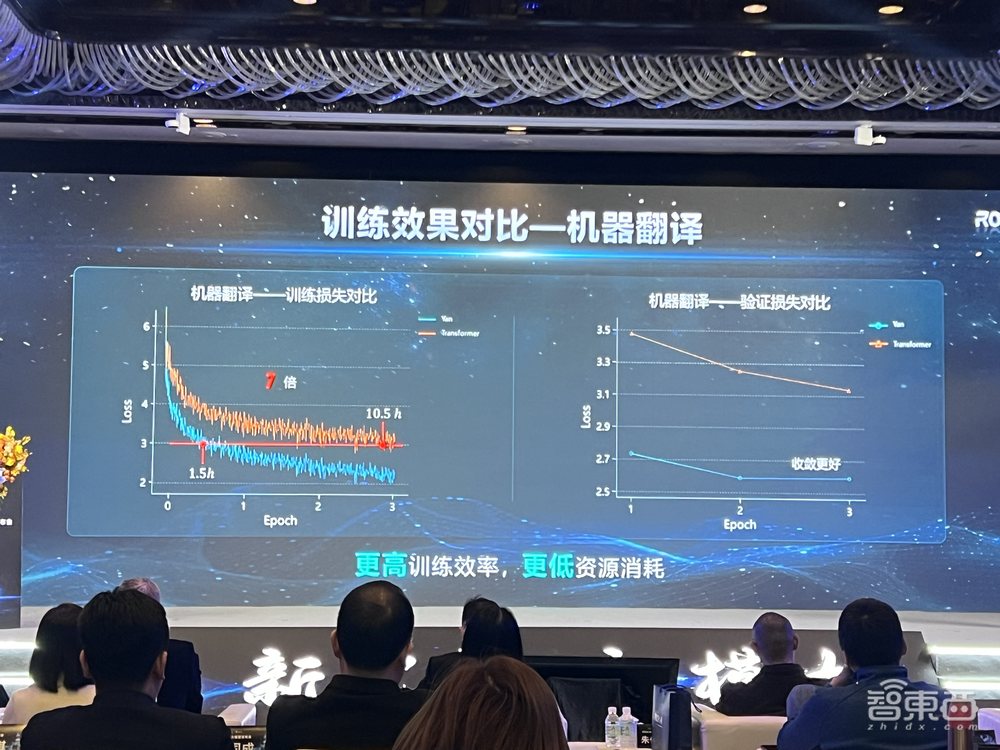
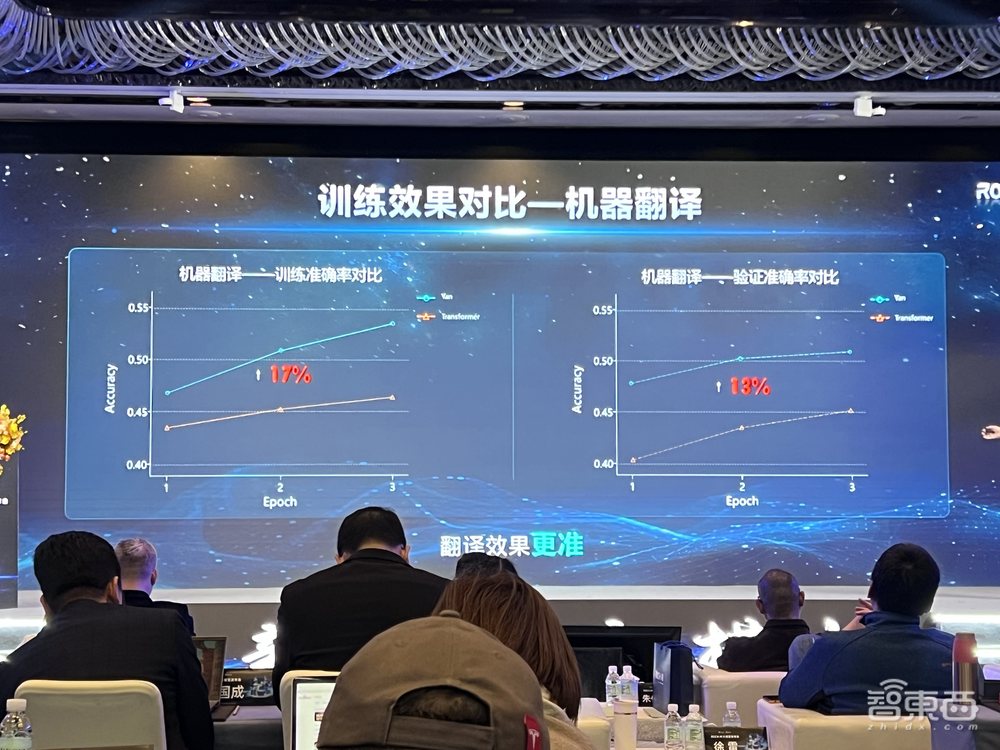
训练集上,Yan的预测准确率比Transformer高出17%,验证集上Yan要高出13%。
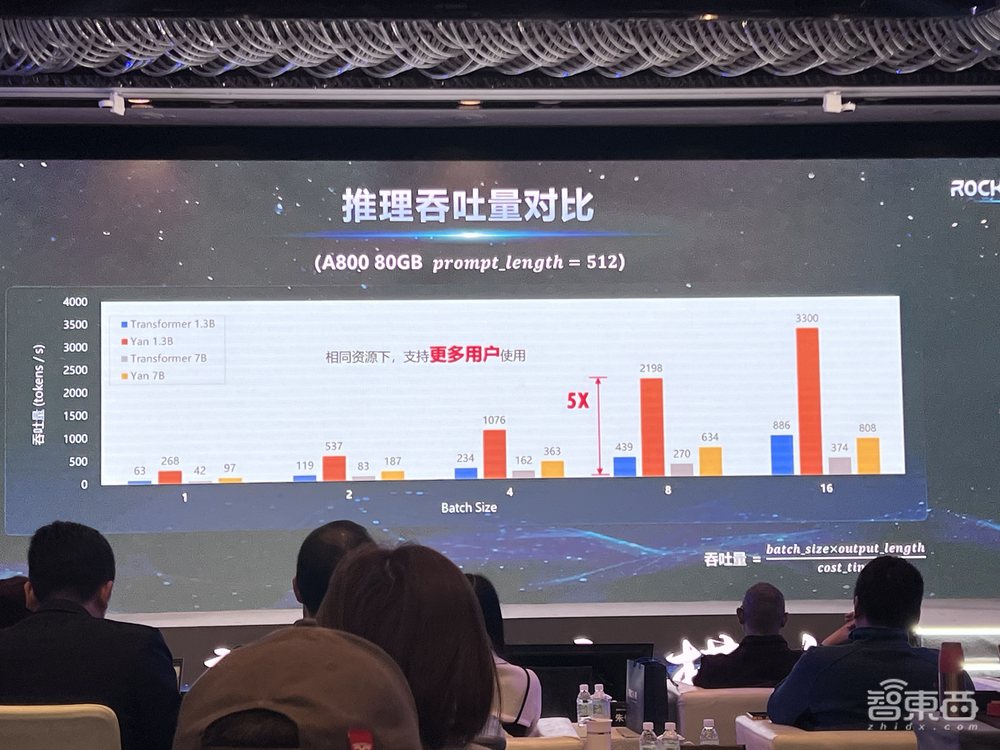
2、推理吞吐量:同资源下高于Transformer
在推理吞吐量对比方面,相同资源下,Yan的吞吐量都要高于相同情况下的Transformer,达到其5倍,能支持更多用户的并发使用。
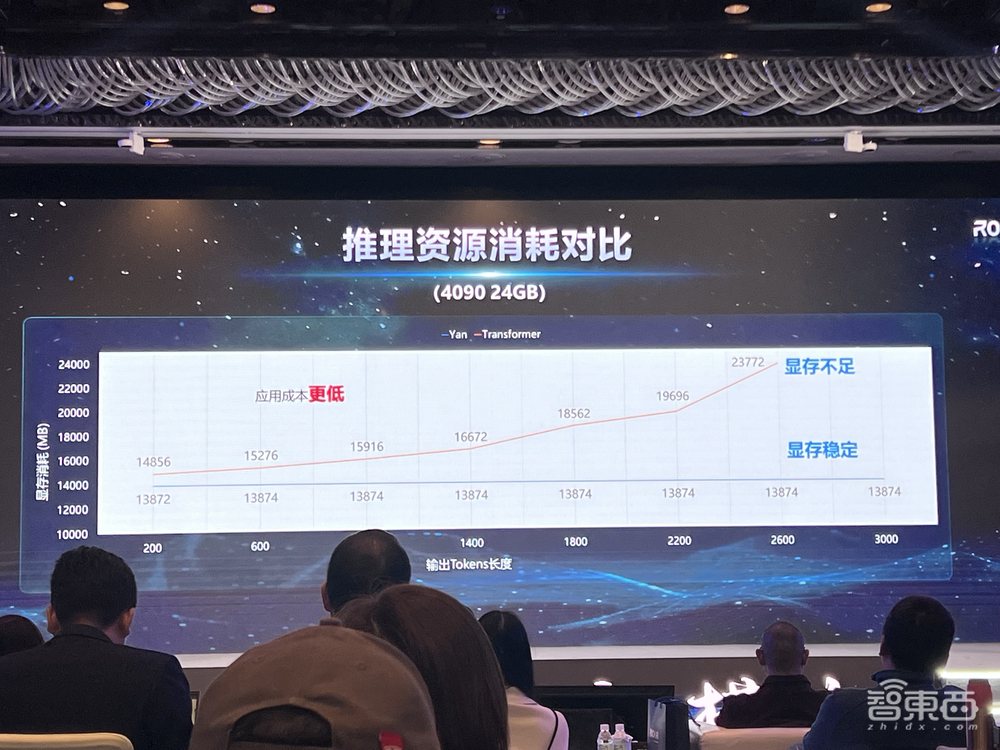
3、推理资源消耗:支持更长序列,降低应用成本
当模型输出的Token从200增加到3000时,Transformer会出现显存不足,但Yan模型始终显存稳定。理论上可以实现无限长度的推理,应用成本更低。
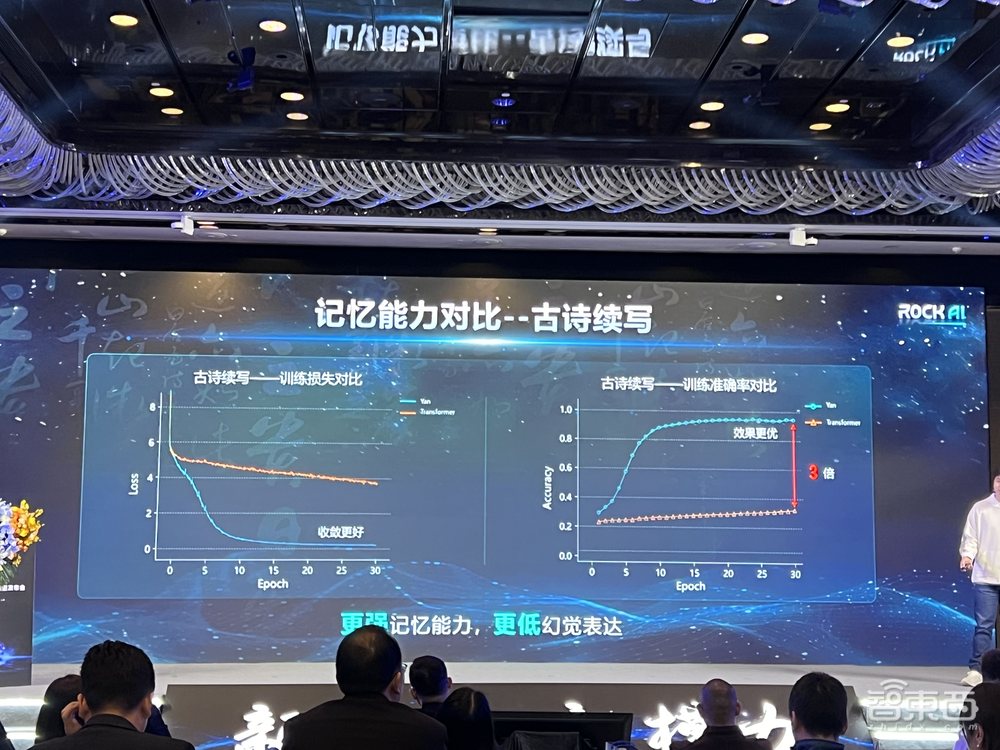
4、记忆能力:准确率为Transformer的3倍
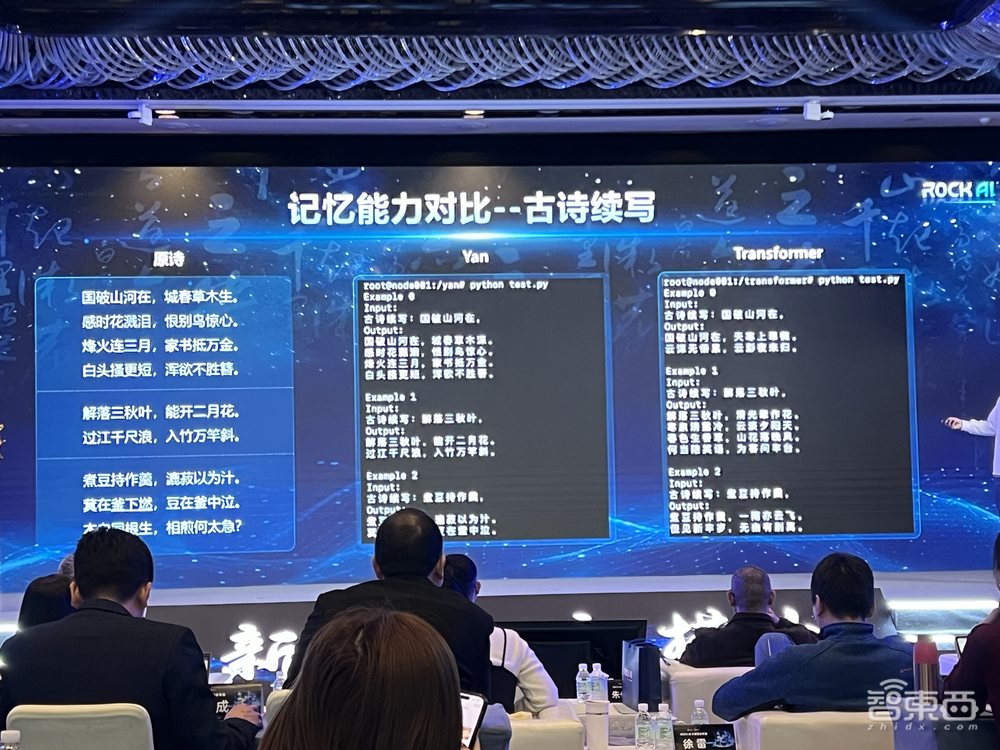
以古诗续写为例,对Yan与Transformer的记忆能力进行对比。训练集上Yan的准确率达到Transformer的3倍,记忆能力更强。
从以下三个例子看到,Transformer没有完成对训练数据的记忆,只记住了句式和字数;Yan则克服幻觉,依靠记忆进行了续写。
刘凡平说,Yan不是基于Llama、GPT、PaLM的套壳,不是基于其他Transformer架构大模型的二次预训练,不是基于开源模型的微调,而是其完全自主知识产权研发的新一代架构大模型。
二、现场演示四大能力,记忆力与逻辑兼顾
目前,Yan1.0推出1.3B、7B和48B三个版本参数规模的模型,并支持大于100B模型的训练。
岩芯数智在现场对Yan1.0大模型进行了演示,通过一台笔记本电脑,本地内存使用维持在13G之内,实现模型运行。演示的内容涉及机器翻译、古诗续写、自由对话和医学问答四个方面。
1、机器翻译,比Transformer更地道
如下图所示,当输入“东方明珠是上海的经典建筑”,Yan1.0给出了准确翻译。由于机器翻译是Transformer的根,因此岩芯数智从这一根技术出发验证Yan1.0大模型的能力。
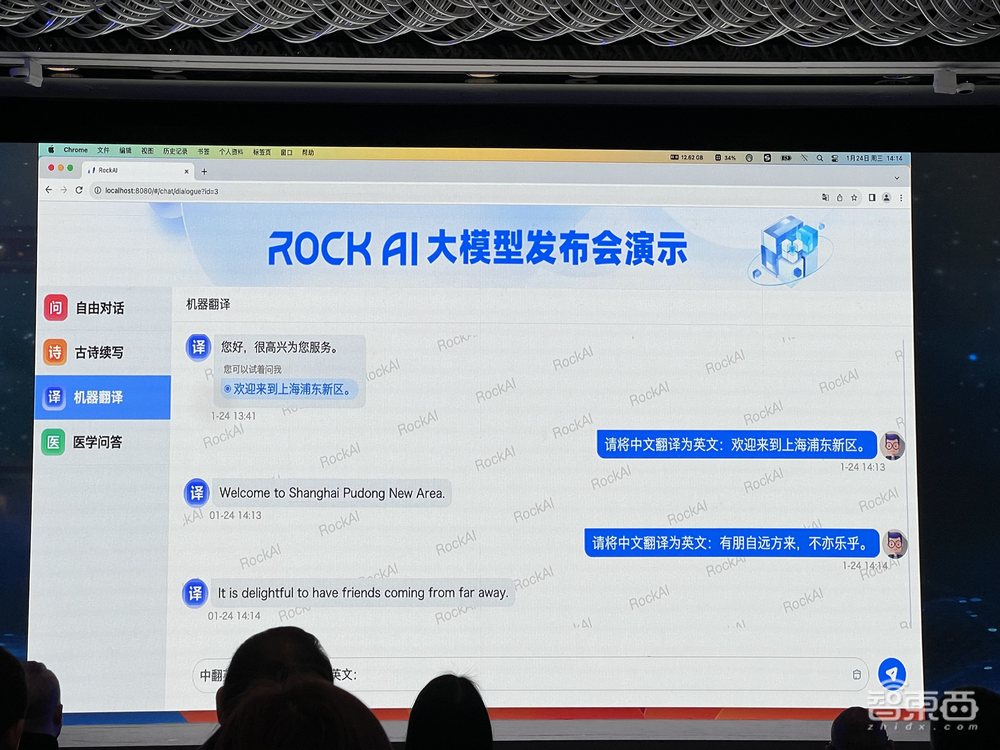
通过一个翻译示例看到,Yan将上海浦东翻译成一个地方,但Transformer没有识别出浦东这一地名,以为是一个Pond(池塘)。

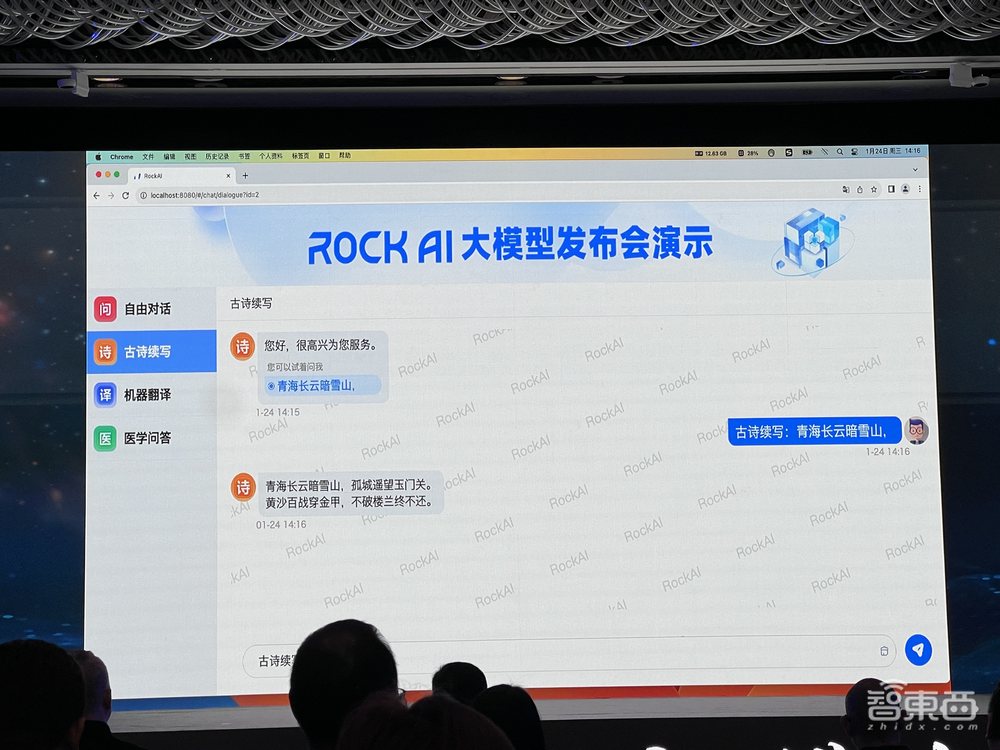
2、古诗续写,提升记忆、降低幻觉
在故事续写能力方面,Yan1.0现场续写了“青海长云暗雪山”这句诗,展现了其记忆能力。Yan1.0的古诗续写不依赖网络搜索引擎和专家系统,而是靠自己的架构能力。对于实际应用来说,记忆能力可以帮大模型降低幻觉,从而更具有实用性。
3、自由对话,能作诗能写文章
在自由对话方面,Yan1.0在现场演示创作了一首诗,描述春天百花齐放的场景。
而后,Yan1.0又被要求描述AI如何影响社会发展,它流畅地输出了200~300字的短文。
4、医学问答,提供健康助理建议
当被问到“流行性感冒如何缓解?”、“腰间盘突出如何缓解?”、“脂肪肝需要如何治疗?”等问题,Yan1.0都给出了建议。

三、超1000天三大迭代,Yan2.0将升级全模态
刘凡平说,Yan并不是团队研发的第一代模型,而是经过了1000多天三代迭代的成果。
Dolphin1.0是标准的Transformer架构,当时团队认为通用人工智能应该已经有了一个比较好的模型架构Transformer了,于是就基于Transformer去做了一套模型。

但在深入研究和实践之后发现缺陷:Transformer架构训练成本太高,成本难以覆盖客户给公司的付费,这种情况下一直做下去是做一单亏一单。团队一开始的解法是基于它加深研究。
所以有了Dolphin2.0。2.0出来之后,团队发现模型的交互还是有很多问题,包括引入线性的Attention机制也有很多问题。于是团队就两头走,一方面尝试改进Attention机制,另一方面尝试引进新的模型架构。
通过两条路探索,团队最终发现还是Yan架构有优势。但这个Yan是最后走出来的,此前团队还尝试了图架构、树形架构等多种路径。从图架构最开始出来的时候,只有部分功能比较好用;到后来树形记忆网络阶段,模型能克服幻觉,记忆能力更好,但推理能力却下降了,比如回答问题没有逻辑性。所以,最后才慢慢演化出了Yan架构。
面临算力耗费高、数据需求大等问题,因此岩芯数智从技术上放弃了Transformer架构和Attention机制。
刘凡平预告,岩芯数智第四代大模型Y2.0已经在路上,这是一个全模态的大模型架构,目标是要全面打通感知、认知、决策与行动,构建通用人工智能的智能循环。岩芯数智不是要复制一个Llama,或者做一个垂直大模型,而是要做一个通用人工智能操作系统。

后续在商业化方面,岩芯数智计划上接云计算、终端厂商等厂家,下接应用开发类厂商,促进其通用人工智能操作系统的落地。
结语:Transformer计算成本高,新模型架构引关注
随着大模型的爆火,传统的Transformer架构同时展现出计算复杂度高、成本压力大等问题,国际上已有Mamba、RWKV等非Transformer架构大模型引起关注,国内也诞生了Yan这样的新架构。
为了研发Yan架构,正如刘凡平所说,其团队经历了众多架构的尝试和迭代,最终取得了记忆、推理等多项能力提升。大模型底层技术的路线之争是一个长期演进过程,哪一条路线能真正跑赢,还需要在实践和与全球对手的比拼中得到验证。
