








智东西(公众号:zhidxcom)
编译 | ZeR0
编辑 | 漠影
智东西2月16日报道,谷歌昨夜发布其大模型矩阵的最新力作——Gemini 1.5,并将上下文窗口长度扩展到100万个tokens。
Gemini 1.5 Pro达到了与1.0 Ultra相当的质量,同时使用了更少的计算。该模型在长语境理解方面取得突破,能够显著增加模型可处理的信息量——持续运行多达100万个tokens,实现迄今任何大型基础模型中最长的上下文窗口。
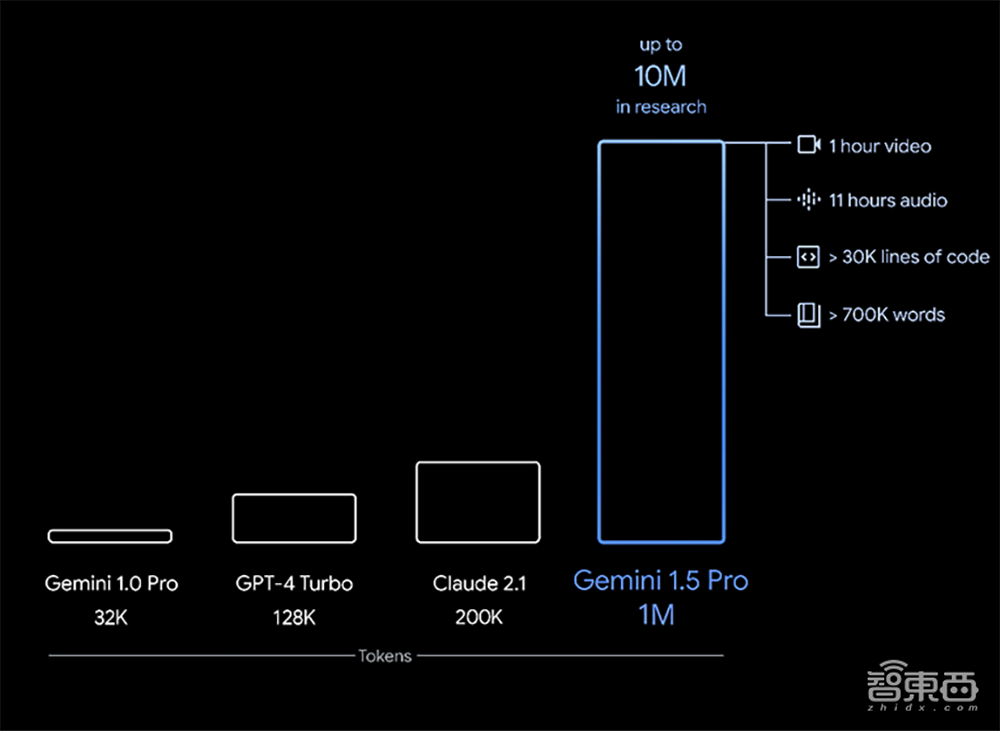
这意味着Gemini 1.5 Pro可一次处理大量的信息——包括1小时的视频、11小时的音频、超过3万行代码或超过70万字的代码库。
从今天开始,谷歌将通过AI Studio和Vertex AI向开发者和企业客户提供Gemini 1.5 Pro的有限预览版。
此外,谷歌透露其在研究中还成功测试了多达1000万个tokens。

58页技术报告地址:https://goo.gle/GeminiV1-5
一、基于Transformer和MoE架构,100万个tokens上下文窗口
谷歌DeepMind首席执行官戴米斯·哈萨比斯代表Gemini团队发言,称Gemini 1.5提供了显著增强的性能,它代表了其方法的一个步骤变化,建立在谷歌基础模型开发和基础设施的几乎每个部分的研究和工程创新之上,包括通过新的专家组合(MoE)架构使模型更有效地训练和服务。
谷歌发布的第一个用于早期测试的Gemini 1.5模型是Gemini 1.5 Pro。这是一个中型的多模态模型,针对广泛的任务进行了优化,其性能与谷歌迄今为止最大的模型1.0 Ultra相当。它还引入了一个突破性的实验特征在长上下文理解。
AI模型的“上下文窗口”由tokens组成,这些tokens是用于处理信息的构建块。上下文窗口越大,它在给定的提示中可接收和处理的信息就越多,从而使其输出更加一致、相关和有用。
通过一系列机器学习创新,谷歌将上下文窗口容量大大增加,从Gemini 1.0最初的32,000个tokens,增加到1.5 Pro的100万个tokens。
Gemini 1.5 Pro带有标准的128,000个tokens的上下文窗口。从今天开始,有限的开发人员和企业客户可通过AI Studio和Vertex AI在私有预览中试用多达100万个tokens的上下文窗口。当推出完整的100万个tokens上下文窗口,谷歌正在积极地进行优化,以改善延迟,减少计算需求并增强用户体验。
Gemini 1.5构建于谷歌对Transformer和MoE架构的研究基础之上。传统的Transformer是一个大型神经网络,而MoE模型被分成更小的“专家”神经网络。
根据给定的输入类型,MoE模型学会选择性地激活其神经网络中最相关的专家路径。这种专业化极大地提高了模型的效率。谷歌一直是深度学习的MoE技术的早期采用者和研发先驱。
谷歌在模型架构上的最新创新使Gemini 1.5能够更快地学习复杂的任务并保持质量,同时更有效地进行训练和服务。这正帮助其团队以更快的速度迭代、训练和交付更先进的Gemini版本。
二、能对大量信息进行复杂推理,稀有语言转译逼近人类水平
Gemini 1.5 Pro可以在给定的提示符内无缝地分析、分类和总结大量内容。例如,当给它一份402页的阿波罗11号登月任务的记录时,它可以对文件中的对话、事件和细节进行推理。
该模型可以理解、推理并识别出阿波罗11号登月任务402页记录中的奇怪细节。
Gemini 1.5 Pro能对不同的模式执行高度复杂的理解和推理任务,包括视频。例如,当给定巴斯特·基顿44分钟的无声电影时,该模型可以准确地分析各种情节点和事件,甚至可以推理出电影中容易被遗漏的小细节。
当给出简单的线条图作为现实生活中物体的参考材料时,Gemini 1.5 Pro可以识别出巴斯特·基顿(Buster Keaton)44分钟默片中的场景。
1.5 Pro可以跨更长的代码块执行更相关的问题解决任务。当给出一个包含超过100,000行代码的提示时,它可以更好地对示例进行推理,提出有用的修改建议,并解释代码的不同部分是如何工作的。
Gemini 1.5 Pro可以对100,000行代码进行推理,给出有用的解决方案、修改和解释。
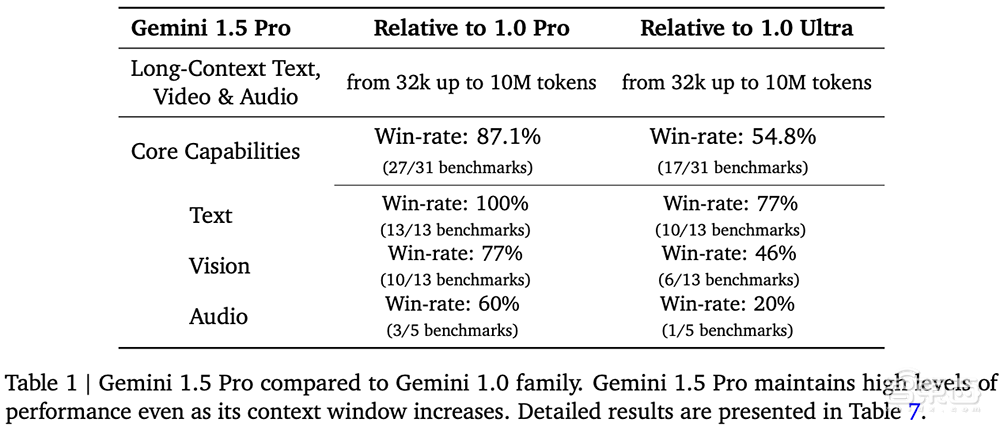
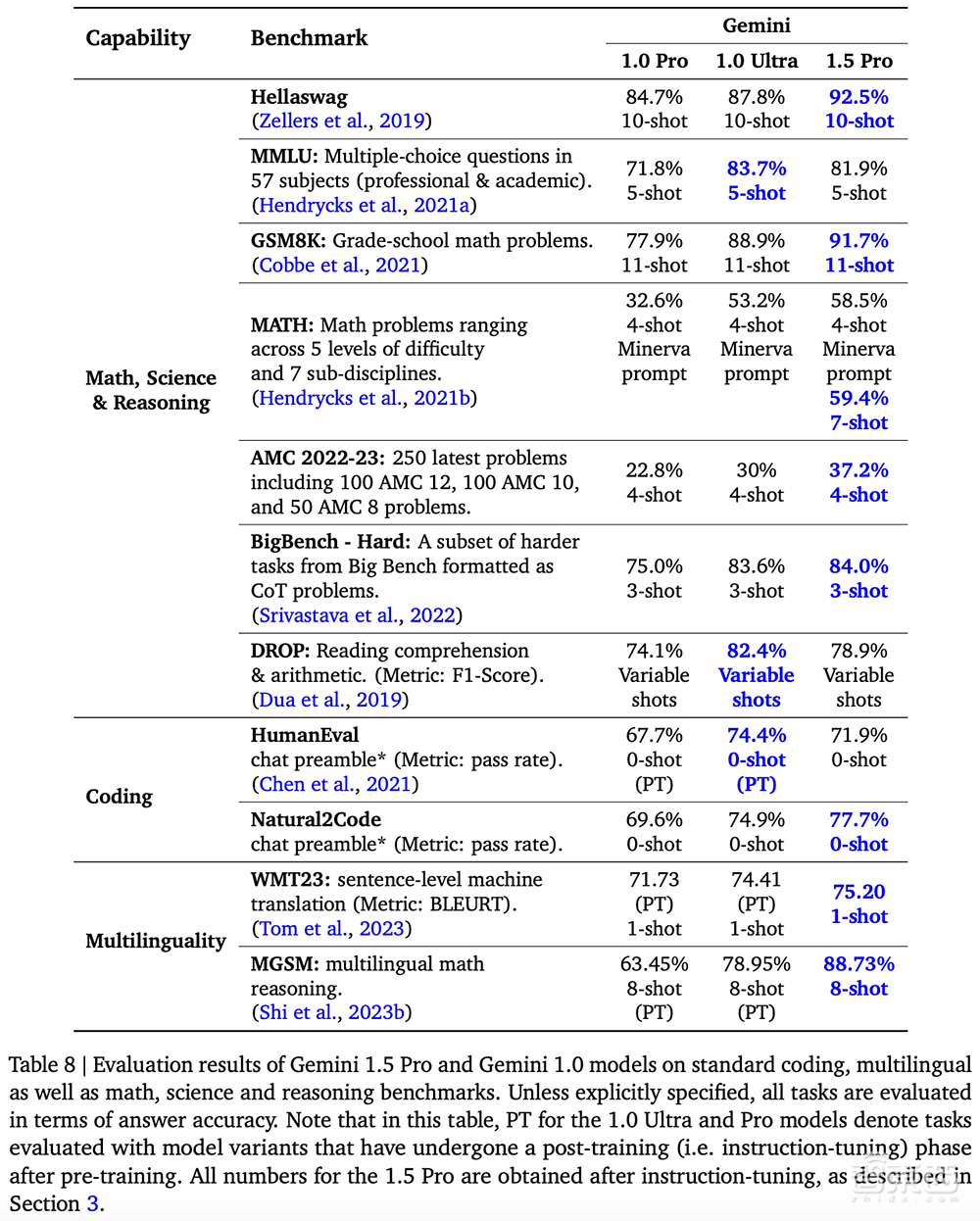
在对文本、代码、图像、音频和视频的综合评估面板上进行测试时,在用于开发大语言模型的87%的基准测试中,Gemini 1.5 Pro优于1.0 Pro。在相同的基准测试中,与1.0 Ultra相比,它的性能水平大致相似。
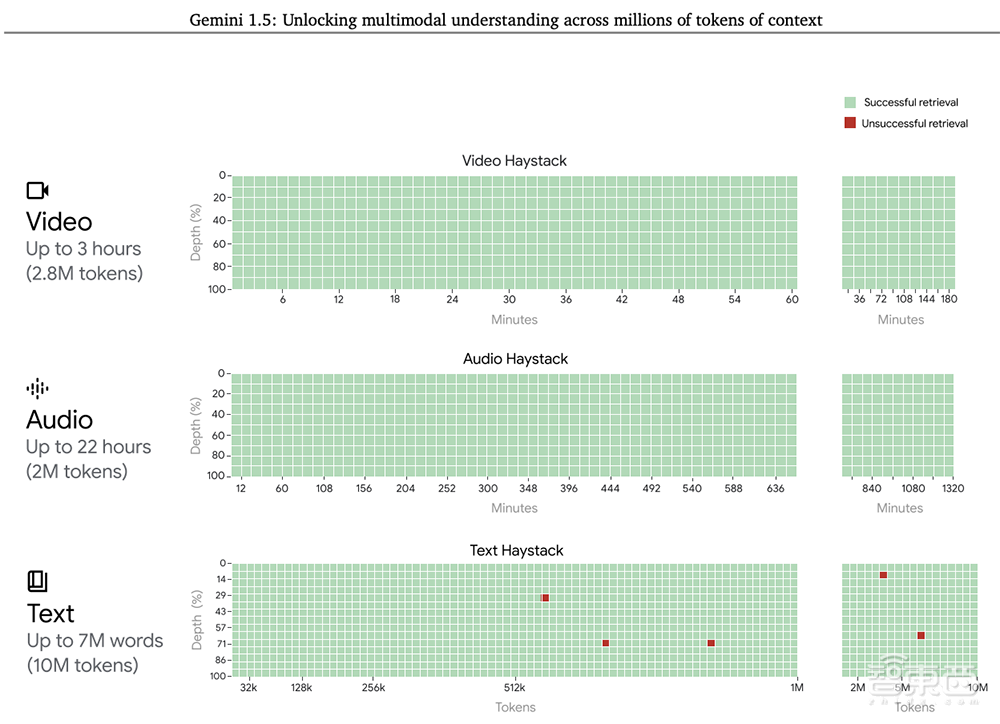
即便上下文窗口增加,Gemini 1.5 Pro也能保持高水平的性能。在NIAH评估中,将一小段包含特定事实或陈述的文本故意放置在长文本块中,Gemini 1.5 Pro在长达100万个tokens的数据块中发现嵌入文本的概率为99%。
Gemini 1.5 Pro还展示了令人印象深刻的“情境学习”技能,可以从长时间提示的信息中学习新技能,而无需额外的微调。
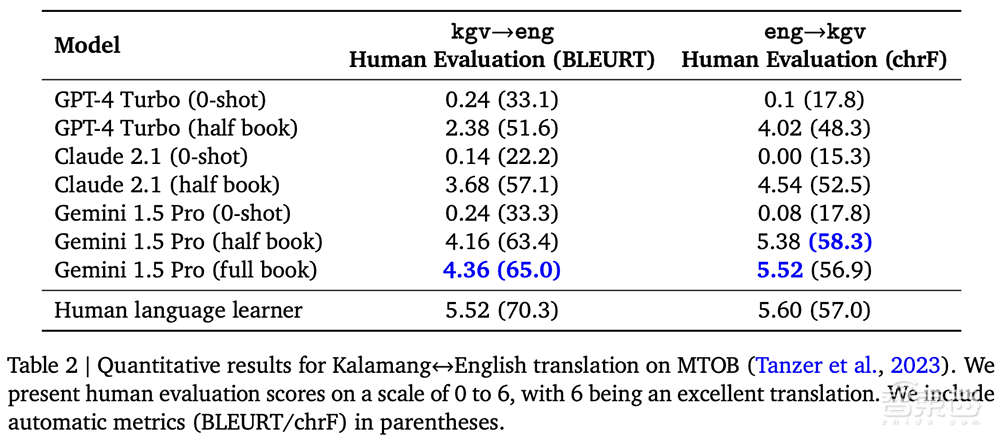
谷歌在MTOB(Machine Translation from One Book)基准上测试了这项技能,它显示了模型从以前从未见过的信息中学习的效果。
特别是针对稀有语言,如英语与卡拉曼语的互译,Gemini 1.5 Pro实现了远超GPT-4 Turbo、Claude 2.1等大模型的测试成绩,水平与人从相同内容中学习英语的水平相似。
结语:正进一步测试,以解释超长上下文功能
根据谷歌AI原则和安全政策,谷歌确保其模型经过广泛的道德和安全测试,并将研究成果整合到其治理流程和模型开发和评估中。
谷歌正在开发进一步的测试,以解释Gemini 1.5 Pro新颖的长上下文功能。
当模型准备好进行更广泛的发布时,谷歌将引入带有标准128,000个tokens上下文窗口的Gemini 1.5 Pro,并很快计划引入定价层,从标准的12.8万个上下文窗口开始,扩展到100万个tokens。
早期的测试人员可以在测试期间免费尝试100万个tokens上下文窗口。有兴趣测试1.5 Pro的开发人员可在AI Studio注册,企业客户可以联系Vertex AI客户团队。
来源:Google DeepMind
