










芯东西(公众号:aichip001)
作者 | ZeR0
编辑 | 漠影
芯东西3月24日报道,当今全世界身价最高的两位华人,一位卖铲,一位卖水。
第一名是英伟达创始人兼CEO黄仁勋,靠给AI淘金者们卖GPU,把英伟达推上全球市值第三的宝座;另一位是农夫山泉创始人、董事长兼总经理钟睒睒,凭“大自然的搬运工”笑傲饮用水江湖。
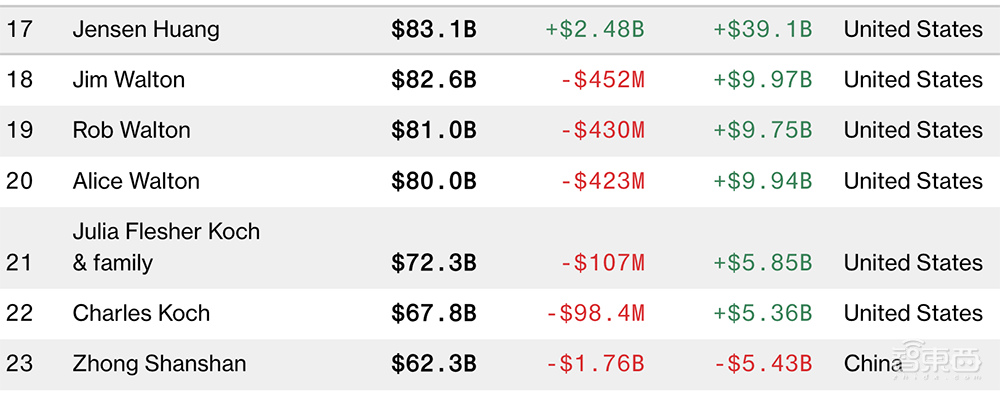 ▲在最新彭博亿万富豪榜中,黄仁勋是第17名 ,钟睒睒是第23名
▲在最新彭博亿万富豪榜中,黄仁勋是第17名 ,钟睒睒是第23名
当前,英伟达市值已经稳坐2万亿美元大关,与苹果的市值差距缩小到0.3万亿美元。

▲全球市值TOP10中,英伟达过去30天股价涨幅最大(图源:Companies Market Cap)
在本周英伟达GTC大会上,黄仁勋一本正经地说:“我们可以附带着卖热水。”
这可不是句玩笑话,黄仁勋是有数据依据的:英伟达DGX新机的液冷散热,液体入口温度是25℃,接近室温;出口温度升高到45℃,接近按摩浴缸的水温,流速是2L/s。
当然了,比起卖水,GPU算力才是英伟达手里的印钞机。
人称“皮衣刀客”的黄仁勋,一贯具有极强的危机感和风险意识,永远在提前为未来铺路。再加上芯片行业是一个高风险高成本低容错的行业,一步走错,可能就会跌落神坛,满盘皆输。所以在AI算力需求空前爆发、一众强敌虎视眈眈的关键时刻,英伟达不敢在新品上有丝毫懈怠,必然会在短期内打出最大爆发,让对手们望尘莫及。
当竞争对手们还在以追赶英伟达旗舰GPU为目标时,黄仁勋已经站在next Level,捕捉到数据中心客户需求的痛点——单芯不顶事,真正顶事的是解决系统级性能和能效提升的挑战。

拿单个旗舰GPU比,英伟达的芯片确实配得上“核弹”称号,性能猛,功耗也高。但黄仁勋厉害在早就跳出芯片本身,不断向数据中心客户灌输“买得越多 省得越多”的理念,简而言之买英伟达的AI系统方案比其他方案更快更省钱。
从Blackwell架构设计到AI基础设施的技术布局,都能反映黄仁勋对未来市场需求和行业趋势的前瞻性判断:
1、摩尔定律带动性能提升越来越捉襟见肘,单die面积和晶体管快到极限,后续芯片迭代必须包括高带宽内存、Chiplet先进封装、片内互联等技术的创新组合。再加上片外互连等高性能通信的优化,共同构成了英伟达打造出专为万亿参数级生成式AI设计的系统的基础。
2、未来,数据中心将被视为AI工厂,在整个生命周期里,AI工厂的目标是产生收益。不同于消费级市场单卖显卡,数据中心市场是个系统级生意,单芯片峰值性能参考价值不大,把很多GPU组合成一个“巨型GPU”,使其在完成同等计算任务时耗费更少的卡、时间和电力,对客户才能带来更大的吸引力。
3、AI模型的规模和数据量将持续增长:未来会用多模态数据来训练更大的模型;世界模型将大行其道,学习掌握现实世界的物理规律和常识;借助合成数据生成技术,AI甚至能模仿人类的学习方式,联想、思考、彼此相互训练。英伟达的目标是不断降低与计算相关的成本和能耗。
4、高性能推理或生成将至关重要。云端运行的英伟达GPU可能有一半时间都被用于token生成,运行大量的生成式AI任务。这既需要提高吞吐量,以降低服务成本,又要提高交互速度以提高用户体验,一个GPU难以胜任,因此必须找到一种能在许多GPU上并行处理模型工作的方法。
一、最强AI芯片规格详解:最大功耗2700W,CUDA配置成谜
本周二,英伟达发布新一代Blackwell GPU架构,不仅刻意弱化了单芯片的存在感,而且没有明确GPU的代号,而是隐晦地称作“Blackwell GPU”。这使得被公认遥遥领先的Blackwell架构多少笼上了一抹神秘色彩。
根据现有信息,全新Blackwell GPU没有采用最先进的3nm制程工艺,而是继续沿用4nm的定制增强版工艺台积电4NP,已知的芯片款式有3类——B100、B200、GB200超级芯片。
B100不是新发布的主角,仅在HGX B100板卡中被提及。B200是重头戏,GB200又进一步把B200和1颗72核Grace CPU拼在一起。
B200有2080亿颗晶体管,超过H100(800亿颗晶体管)数量的两倍。英伟达没透露单个Blackwell GPU die的具体大小,只说是在reticle大小尺寸限制内。上一代单die面积为814mm²。由于不知道具体数字,不好计算B200在单位面积性能上的改进幅度。

英伟达通过NV-HBI高带宽接口,以10TB/s双向带宽将两个GPU die互联封装,让B200能像单芯片一样运行,不会因为通信损耗而损失性能,没有内存局部性问题,也没有缓存问题,能支持更高的L2缓存带宽。但英伟达并没有透露它具体采用了怎样的芯片封装策略。
前代GH200超级芯片是把1个H100和1个Grace CPU组合。而GB200超级芯片将2个Blackwell GPU和CPU组合,每个GPU的满配TDP达到1200W,使得整个超级芯片的TDP达到2700W(1200W x 2+300W)。
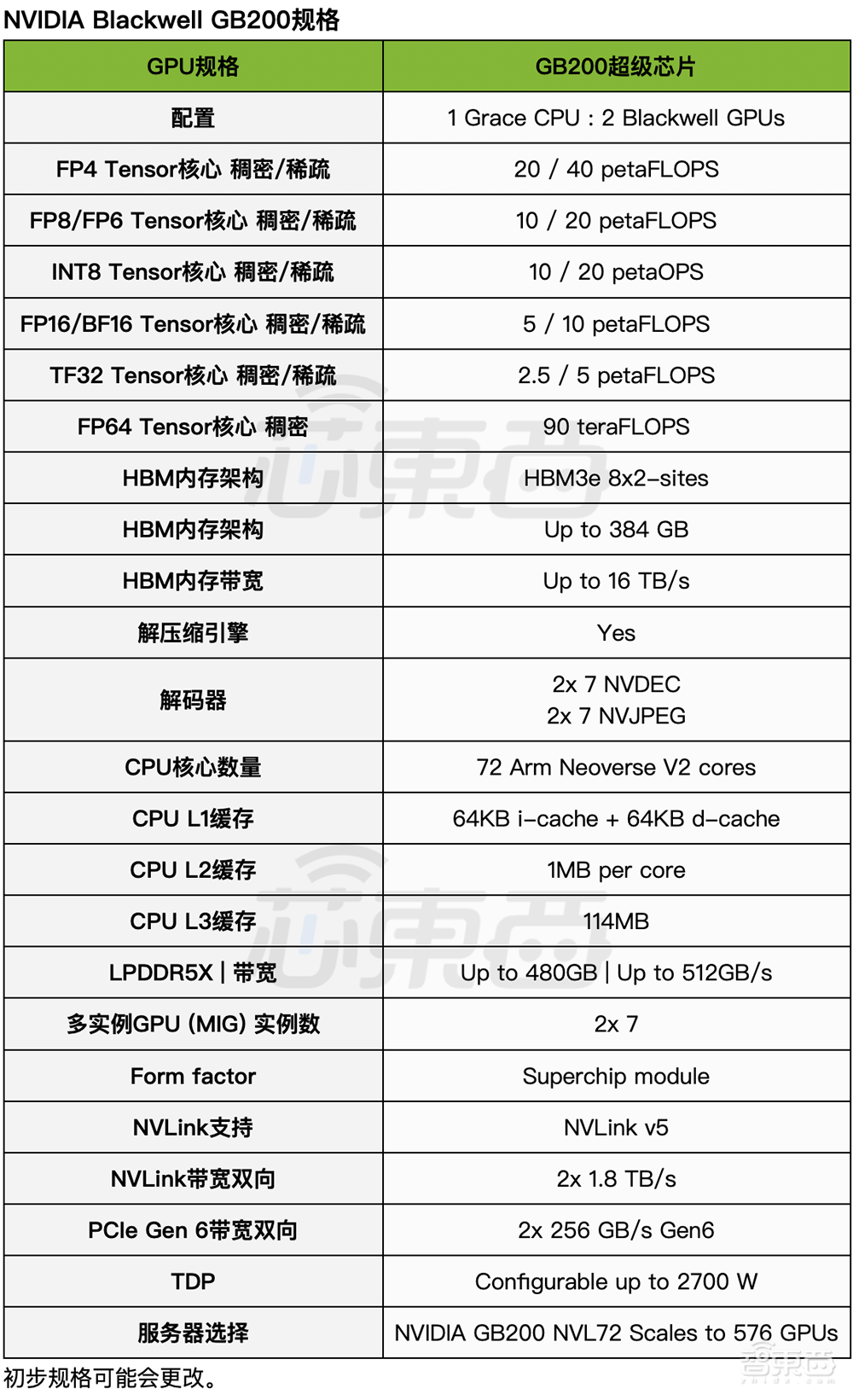 ▲Blackwell GB200规格(图源:芯东西根据技术简报表格译成中文)
▲Blackwell GB200规格(图源:芯东西根据技术简报表格译成中文)
值得关注的是,Blackwell架构技术简报仅披露了Tensor核心数据,对CUDA核心数、Tensor核心数、向量算力等信息只字未提。除了FP64是稠密,其他数据格式都显示了稀疏算力。
相比之下,标准FP64 Tensor核心计算性能提升幅度不大,H100和H200是67TFLOPS,GB200超级芯片是90TFLOPS,比上一代提高34%。
一种可能的推测是Blackwell架构的设计全面偏向AI计算,对高性能计算的提升不明显。如果晶体管都用于堆Tensor核心,它的通用能力会变弱,更像个偏科的AI NPU。
由于采用相同的基础设施设计,从Hopper换用Blackwell主板就像推拉抽屉一样方便。
技术简报披露了Blackwell x86平台HGX B100、HGX B200的系统配置。HGX B200搭载8个B200,每个GPU的TDP为1000W;HGX B100搭载8个B100,每个GPU的TDP为700W。
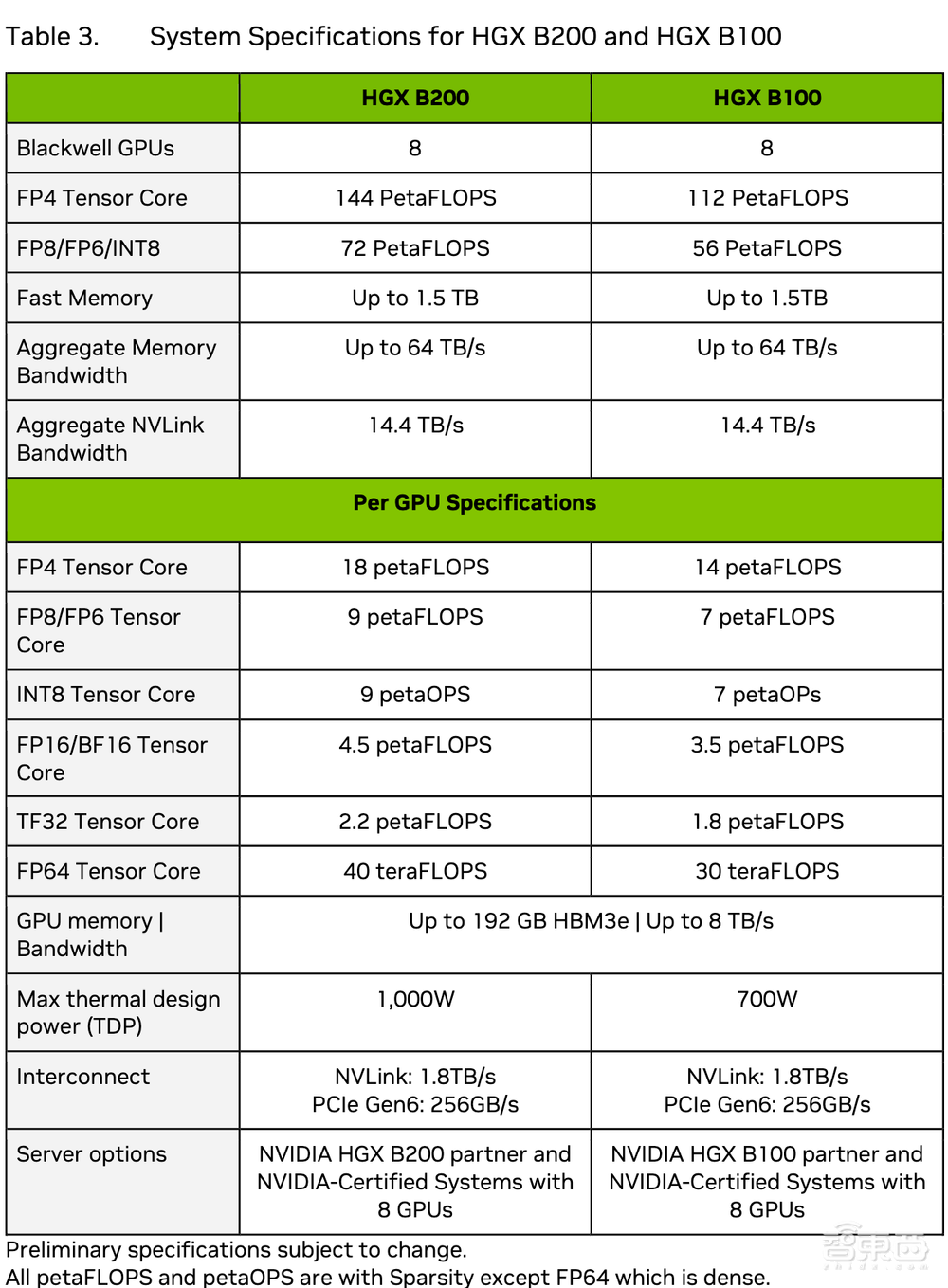 ▲HGX B200和HGX B100系统规格(图源:Blackwell架构技术简报)
▲HGX B200和HGX B100系统规格(图源:Blackwell架构技术简报)
在数据中心Blackwell GPU发布后,业界关注焦点移向同样基于Blackwell架构的游戏显卡RTX 50系列。目前距离RTX 50系列GPU的发布日期还很遥远,最快也得到今年年底,慢点可能要到明年甚至是后年。
不过现在已经有很多关于配置的传言,比如采用台积电3nm和28Gbps GDDR 7显存、最大总线宽度有384bit和512bit两种说法,芯片包括从入门级GB207到高端级GB202,会继续优化路径追踪、光线追踪。
二、8年AI训练算力提升1000倍,英伟达是怎么做到的?
从2016年Pascal GPU的19TFLOPS,到今年Blackwell GPU的20PFLOPS,黄仁勋宣布英伟达用8年将单卡AI训练性能提升了1000倍。
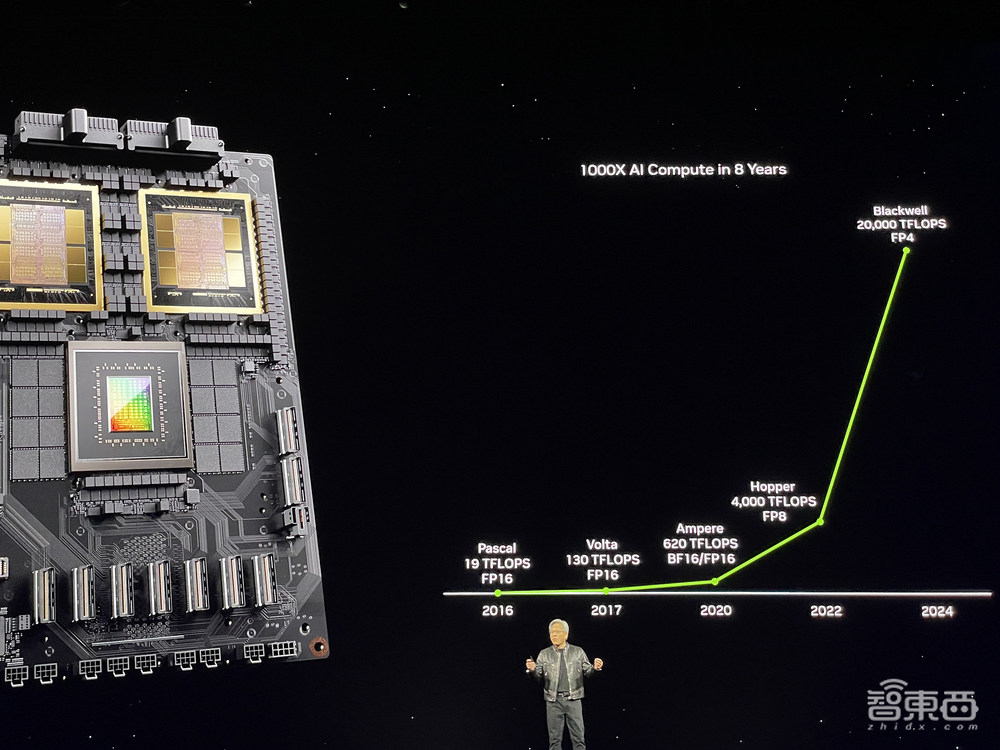
这个听起来令人心潮澎湃的倍数,除了得益于制程工艺迭代、更大的HBM容量和带宽、双die设计外,数据精度的降低起到关键作用。

多数训练是在FP16精度下进行,但实际上不需要用这么高的精度去处理所有参数。英伟达一直在探索怎么通过混合精度操作来在降低内存占用的同时确保吞吐量不受影响。
Blackwell GPU内置的第二代Transformer引擎,利用先进的动态范围管理算法和细粒度缩放技术(微型tensor缩放)来优化性能和精度,并首度支持FP4新格式,使得FP4 Tensor核性能、HBM模型规模和带宽都实现翻倍。

同时TensorRT-LLM的创新包括量化到4bit精度、具有专家并行映射的定制化内核,能让MoE模型实时推理使用耗费硬件、能量、成本。NeMo框架、Megatron-Core新型专家并行技术等都也为模型训练性能的提升提供了支持。
降精度的难点是兼顾用户对准确率的需求。FP4并不在什么时候都有效,英伟达专门强调的是对混合专家模型和大语言模型带来的好处。把精度降到FP4可能会有困惑度增加的问题,英伟达还贴心地加了个过渡的FP6,这个新格式虽然没什么性能优势,但处理数据量比FP8减少25%,能缓解内存压力。
三、90天2000块GPU训练1.8万亿参数模型,打破通信瓶颈是关键
和消费级显卡策略不同,面向数据中心,黄仁勋并不打算通过卖一颗两颗显卡来赚取蝇头小利,而是走“堆料”路线来帮客户省钱。
无论是大幅提高性能,还是节省机架空间、降低电力成本,都对在AI大模型竞赛中争分夺秒的企业们相当有吸引力。
黄仁勋举的例子是训练1.8万亿参数的GPT-MoE混合专家模型:
用25000个Ampere GPU,需要3~5个月左右;要是用Hopper,需要约8000个GPU、90天来训练,耗电15MW;而用Blackwell,同样花90天,只需2000个GPU,耗电仅4MW。
省钱与省电成正比,提高能效的关键是减少通信损耗。据Ian Buck和Jonah Alben分享,在GPU集群上运行庞大的GPT-MoE模型,有60%的时间都花在通信上。

Ian Buck解释说,这不光是计算问题,还是I/O问题,混合专家模型带来更多并行层和通信层。它将模型分解成一群擅长不同任务的专家,谁擅长什么,就将相应训练和推理任务分配给谁。
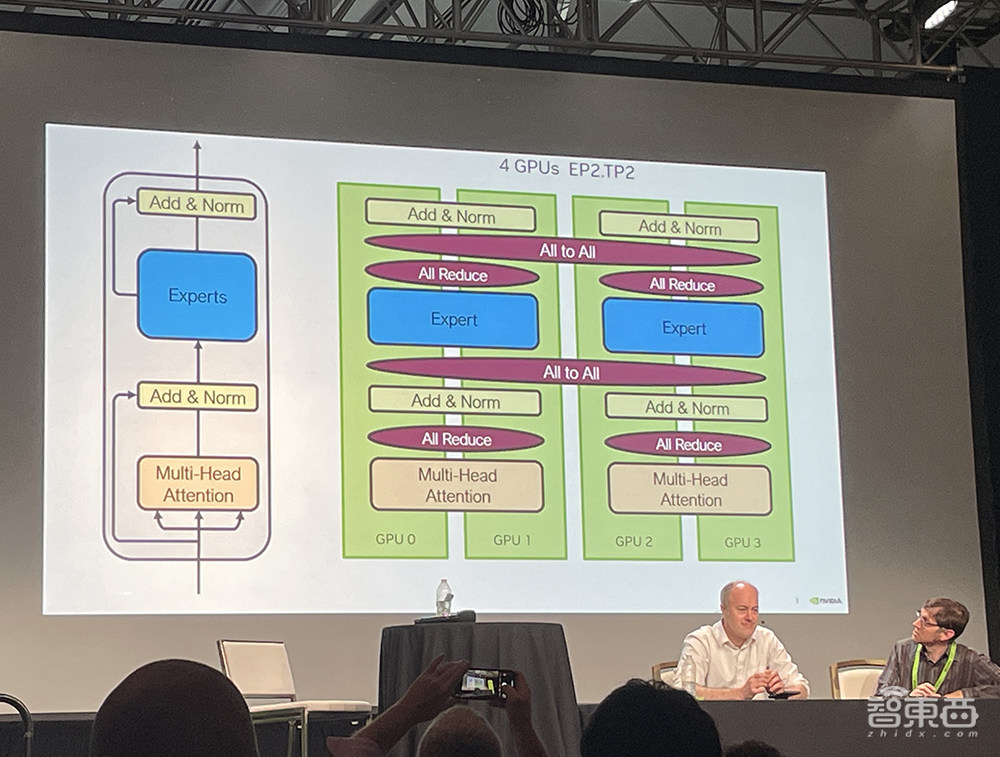
所以实现更快的NVLink Switch互连技术非常重要。所有GPU必须共享计算过程中的结果,在DGX GB200 NVL72机架中,多节点All-to-All通信、all-Reduce的通信速度都较过去暴涨。

全新NVLink Switch芯片总带宽达到7.2TB/s,支持GPU纵向扩展,能驱动4个1.8TB/s的NVLink端口。而PCIe 9.0 x16插槽预计要到2032年才能提供2TB/s的带宽。
从单卡来看,相比H100,Blackwell GPU的训练性能仅提高到2.5倍,即便按新添的FP4精度算,推理性能也只提高到5倍。
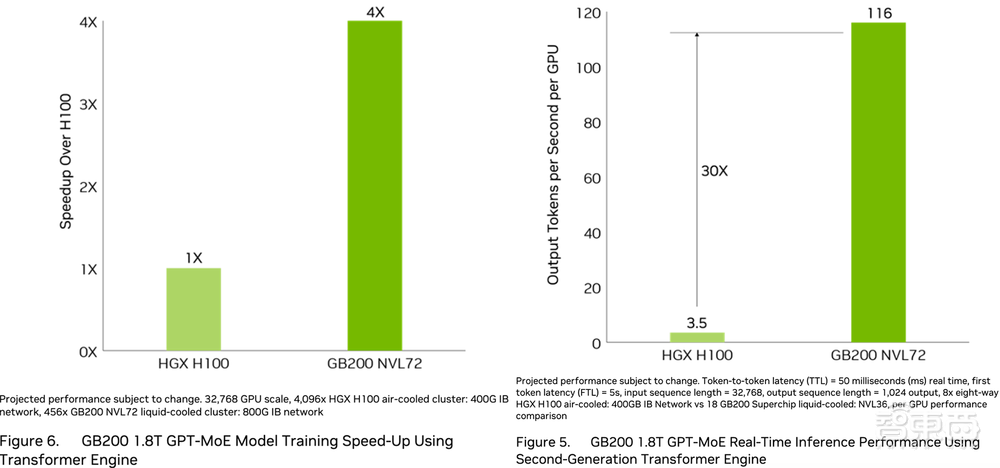
但如果从系统性能来看,相比上一代Hopper集群,Blackwell可将1.8万亿参数的GPT-MoE推理性能提高到30倍。
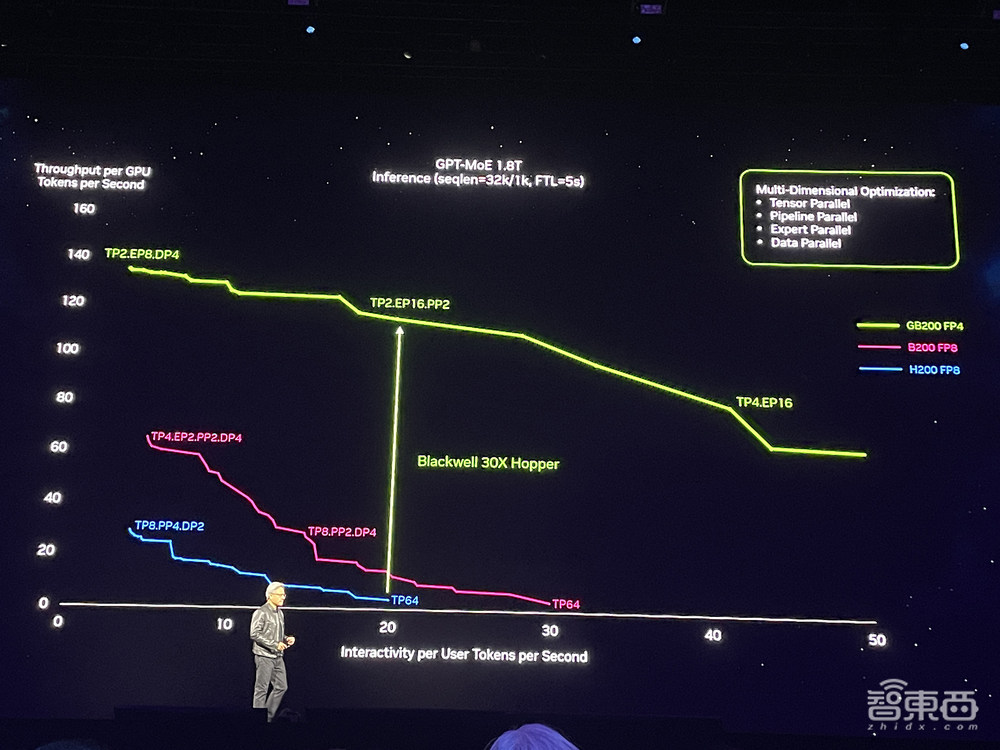 ▲基于第二代Transformer引擎的GB200 1.8T GPT-MoE实时推理性能
▲基于第二代Transformer引擎的GB200 1.8T GPT-MoE实时推理性能
蓝色曲线代表H200,紫红色曲线代表B200,从蓝到紫只涉及从Hopper单芯设计到Blackwell双芯设计的芯片升级。加上全新FP4、Tensor核心、Transformer引擎、NVLink Switch等技术,性能涨到如绿色曲线代表的GB200所示。
下图中Y轴是每GPU每秒token数,代表数据中心吞吐量;X轴是每用户每秒token数,代表用户的交互体验,越靠近右上方的数据代表两种能力都很强。绿色曲线是峰值性能线。
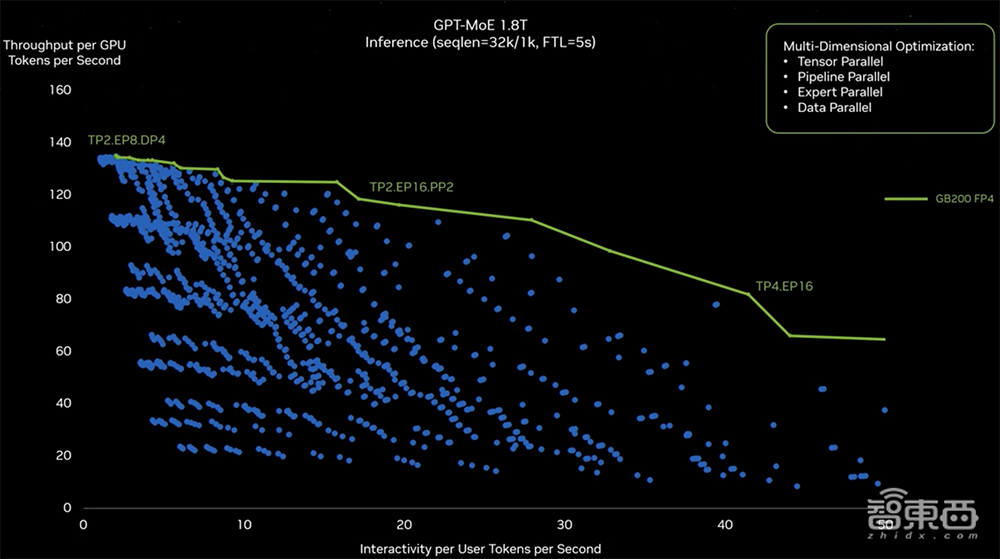
为了找出GPT-MoE训练的正确并行配置,英伟达做了大量实验(得到图中的蓝点),以探索创建硬件和切割模型的正确方法,使其尽可能实现高效运行。其探索包括一些软件重分块、优化策略判断,并将大模型分布在不同的GPU中来满足性能需求。
左侧TP2代表2个GPU的Tensor并行,EP8代表跨8个GPU的专家并行,DP4代表跨4个GPU的数据并行。右侧有TP4,跨4个GPU的Tensor并行、跨16个GPU的专家并行。软件层面不同的配置和分布式策略会导致运行时产生不同结果。
黄仁勋还从通信耗材的角度来说明Blackwell DGX系统能够更省电省钱。

他解释说在DGX背面NVLink主干数据以130TB/s双向带宽通过机箱背面,比互联网总带宽还高,基本上1秒钟内能将所有内容发送给每个人,里面有5000根NVLink铜缆、总长度2英里。
如果用光传输,就必须使用光模块和retimer,这俩器件要耗电20kW,仅是光模块就要耗电2kW。只是为了驱动NVLink主干,英伟达通过NVLink Switch不耗电就能做到,还能节省20kW用于计算(整个机架功耗为120kW)。
四、集结高速通信能力,在单机架上打造E级算力AI超级计算机
更快的网络,带来了更强大的计算效率。
DGX GB200 NVL72采用液冷机架式设计,顾名思义,通过第五代NVLink以1.8TB/s通信速度将72个GPU互连。一个机架最多有高达130TB/s的GPU带宽、30TB内存,训练算力接近E级、推理算力超过E级。
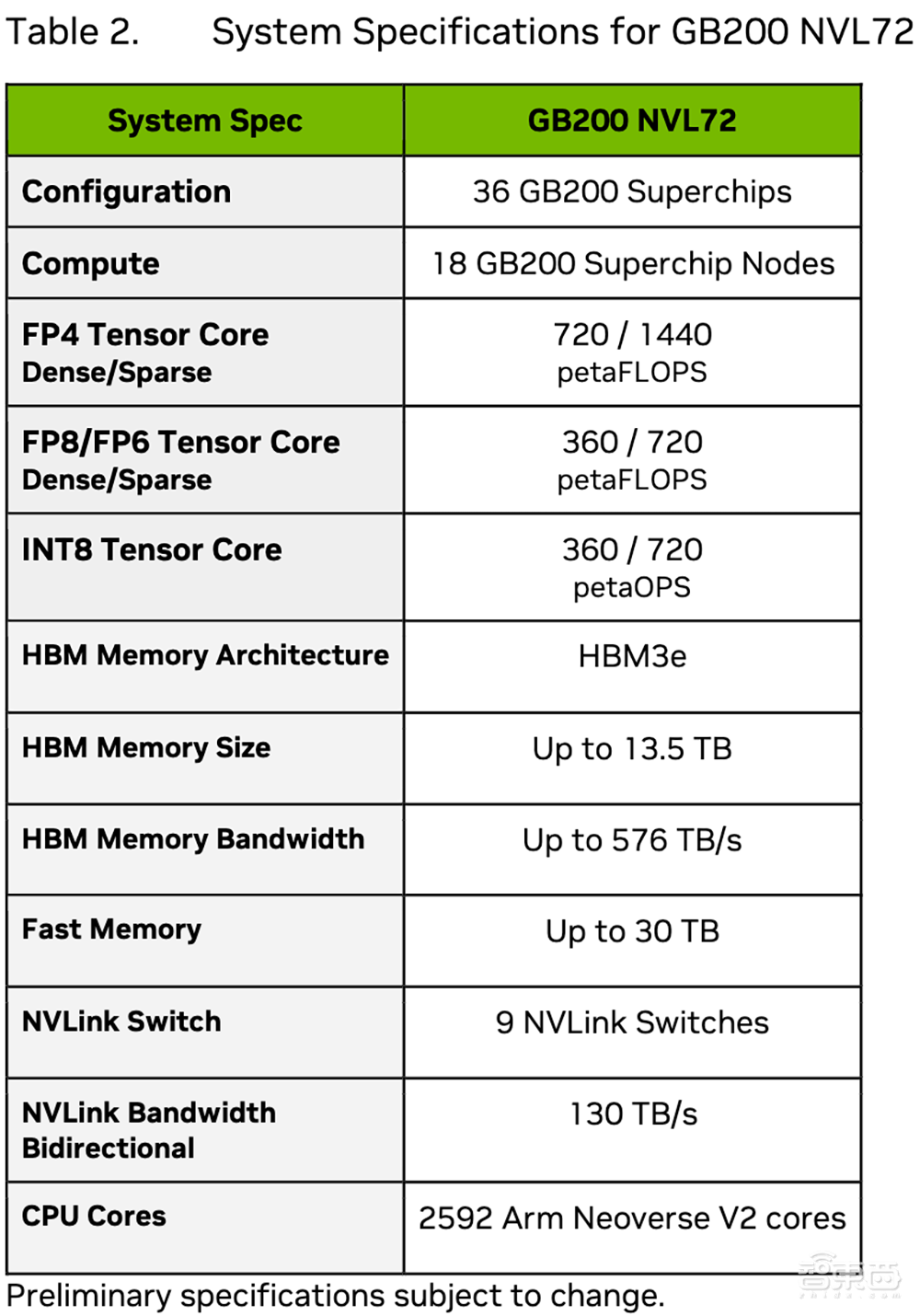
相较相同数量H100 GPU的系统,GB200 NVL72为GPT-MoE-1.8T等大语言模型提供4倍的训练性能。在GB200 NVL72中用32个Blackwell GPU运行GPT-MoE-1.8T,速度是64个Hopper GPU的30倍。
黄仁勋说,这是世界上第一台单机架EFLOPS级机器,整个地球也不过两三台E级机器。
对比之下,8年前,他交给OpenAI的第一台DGX-1,训练算力只有0.17PFLOPS。
H100搭配的第四代NVLink总带宽是900GB/s,第五代则翻倍提升到1.8TB/s,是PCle 5带宽的14倍以上。每个GPU的NVLink数量没变,都是18个链路。CPU与B200间的通信速度是300GB/s,比PCIe 6.0 x16插槽的256GB/s更快。

GB200 NVL72需要强大的网络来实现最佳性能,用到了英伟达Quantum-X800 InfiniBand、Spectrum-X800以太网、BlueField-3 DPU和Magnum IO软件。

两年前,黄仁勋看到的GPU是HGX,重70磅,有35000个零件;现在GPU有60万个零件,重3000磅,“应该没有一头大象沉”,“重量跟一辆碳纤维法拉利差不多”。
第五代NVLink把GPU的可扩展数量提高到576个。英伟达还推出一些AI安全功能来确保数据中心GPU的最大正常运行时间。8个GB200 NVL72机架可组成1个SuperPOD,与800Gb/s InfiniBand或以太网互连,或者可以创建一个将576个GPU互连的大型共享内存系统。

据Ian Buck透露,目前最大配置的576个GPU互连主要是用于研究,而不是生产。
结语:八年伏脉,一朝登顶
从打造垂直生态的角度来看,英伟达越来越像芯片和AI计算领域的苹果,在研发、工程和生态方面都展现出强大而全面的统治力。
就像苹果用App Store牢牢粘住开发者和消费者一样,英伟达已经打造了完备的芯片、系统、网络、安全以及各种开发者所需的软件,用最好的软硬件组合不断降低在GPU上加速AI计算的门槛,让自己始终处于企业及开发者的首选之列。
在数据中心,看单个芯片峰值性能没什么意义,很多芯片连在一起实现的实质性算力改进,才有直接参考性。所以黄仁勋要卖“系统”,是一步跨到数据中心客户算力需求的终点。
相比上一代Hopper,Blackwell GPU的主要优化没有依赖制程工艺技术的提升,而是更先进的内存、更快的片内互联速度,并通过升级片间互连、多机互连的速度以及可扩展性、管理软件,消除大量数据处理导致的通信瓶颈,从而将大量GPU连成一个更具成本效益的强大系统。
草蛇灰线,伏脉千里。将芯片、存储、网络、软件等各环节协同的系统设计之路,英伟达早在8年前就在探索。2016年4月,黄仁勋亲手将第一台内置8个P100 GPU的超级计算机DGX-1赠予OpenAI团队。之后随着GPU和互连技术的更新换代,DGX也会随之升级,系统性能与日俱增。
数据中心AI芯片是当前硅谷最热门的硬件产品。而英伟达是这个行业的规则制定者,也是离生成式AI客户需求最近的企业,其对下一代芯片架构的设计与销售策略具有行业风向标的作用。通过实现让数百万个GPU共同执行计算任务并最大限度提高能效的基础创新,黄仁勋反复强调的“买得越多 省得越多”已经越来越具有说服力。
