








芯东西(公众号:aichip001)
作者 | ZeR0
编辑 | 漠影
芯东西4月3日报道,在激烈的“百模大战”后,全球生成式AI竞赛的焦点转向落地应用,AI推理正迎来属于它的时代。
这是一个巨大的金矿,CPU代表英特尔和GPU代表英伟达都在活跃地刷新AI推理性能的战绩。当前战况是,CPU牢牢占据“省钱为王”的攻心大法,GPU则极力加深抬高性能天花板的印象。
在CPU加速AI推理方面,英特尔一向是“头号代言人”。上周,最新MLPerf 4.0推理基准测试发布,英特尔是唯一一家参与测试的CPU厂商,选送了去年年底发布的第五代至强可扩展处理器。
这颗芯片寄予了英特尔进入大模型时代继续捍卫CPU在AI推理领域主导权的雄心。比高端GPU或专用AI芯片更便宜、易得的CPU,一直是传统AI和机器学习推理领域的主角,而至强可扩展处理器是英特尔手中的数据中心“王牌”,其战斗力已经通过历史的检验,接下来的关键战役就是在愈发火热的大模型竞赛中,赢得足够的客户好感。
从英特尔分享的客户案例来看,第五代至强在国内云计算领域已经积累了一些口碑。
比如百度智能云基于第五代至强的四节点服务器跑Llama 2 70B模型,推理结果可达87.5ms;京东基于第五代至强的应用,和前一代处理器相比,在Llama 2 13B模型上有50%的性能提升。
英特尔市场营销集团副总裁、中国区数据中心销售总经理兼中国区运营商销售总经理庄秉翰近日向芯东西等媒体分享,基于第五代至强的服务器在会议纪要、大纲总结、内容分析、文生图、机器人聊天客服、代码撰写等通用应用中都展现出了优势。
面向AI推理的CPU优化正快速发展,第五代至强融入了哪些创新设计?如何最大限度挖掘CPU的推理性能?英特尔资深技术专家从制程技术改进、芯片布局、性能与能效、末级缓存、内存I/O等多个维度系统全面地解构了第五代至强的架构设计,并分享了很多芯片布局的细节。
庄秉翰预告说,今年英特尔将发布新一代英特尔至强可扩展处理器,并有一个非常丰富的产品组合,同时满足性能和社会对能耗的要求。

基于第五代至强,英特尔将发布下一代性能核,即高主频、高性能的CPU核架构,为主流和复杂的数据中心应用优化性能;同时针对新兴的,尤其是基于云原生的设计,提供追求相对极致每瓦性能的能效核,注重实现能效优化。
除了芯片基本特性外,按期交付非常重要,英特尔这两年的产品发布非常密集,在强大的执行力推动下,英特尔也将按计划发布未来的产品。
一、AI推理性能平均提升42%,大模型延迟优于市场要求
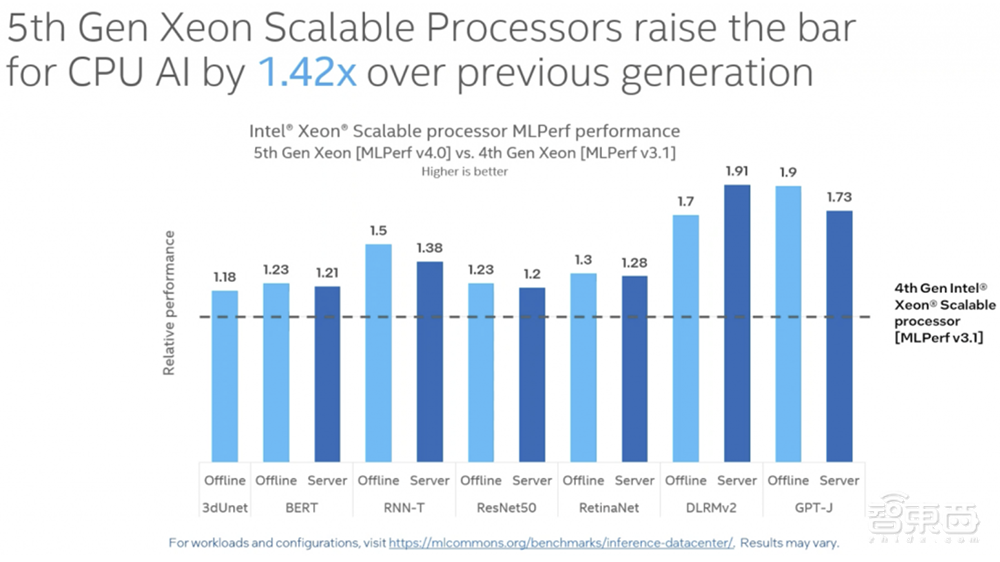
英特尔市场营销集团副总裁、中国区数据中心销售总经理兼中国区运营商销售总经理庄秉翰谈道,基于软硬件的优化,相比第四代至强,第五代至强在AI训练、实时推理、批量推理上,基于不同的算法,性能可提升40%左右。
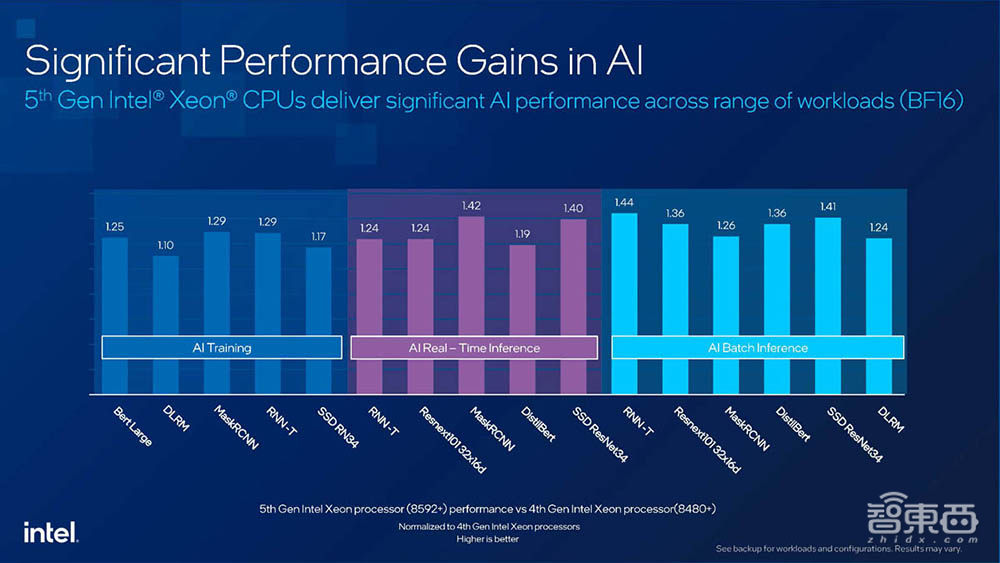
与第四代至强相比,第五代至强的AI推理性能增加42%,通用计算性能(常规整数计算)提升21%,还有适用于各种负载的优秀每瓦性能。

庄秉翰称,在模型调优、推理、应用上,使用通用服务器有非常大的性价比提升。尤其当企业不需要24小时跑大模型,大模型对业务作辅助时,这些只是帮助企业业务提高生产力,尤其是在私有云上,没必要再重新部署一个新的GPU平台,因为一个新的平台意味着需考虑开发、运维等因素,成本可能增加,可能给企业带来负担。
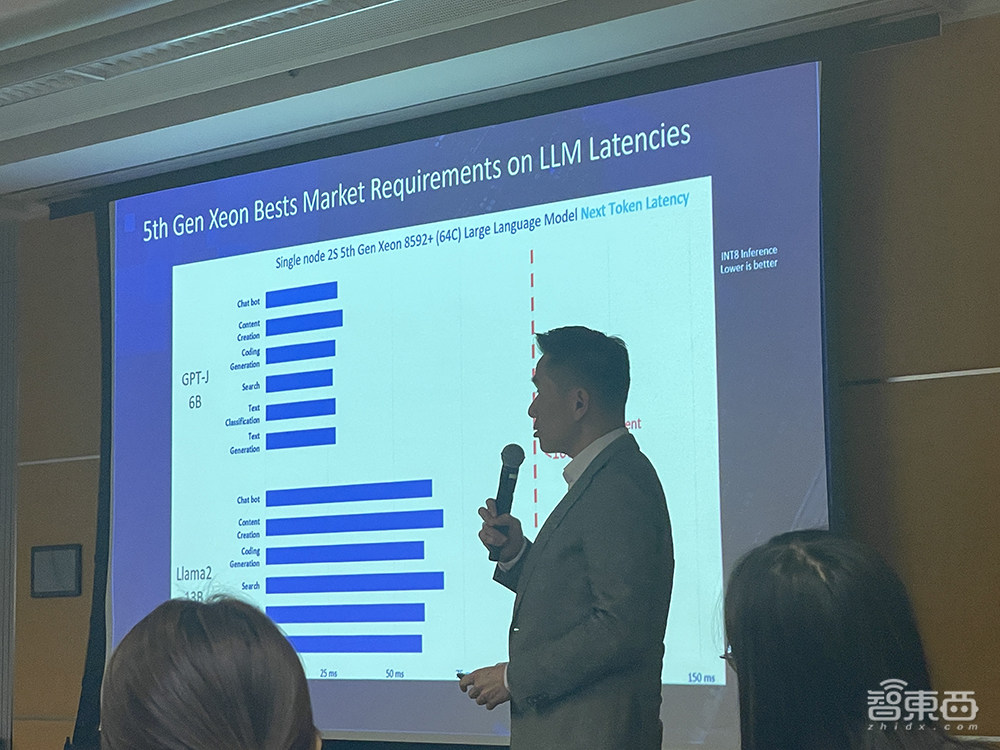 ▲庄秉翰分享在第五代至强上跑大模型生成第二个token的延迟
▲庄秉翰分享在第五代至强上跑大模型生成第二个token的延迟
上图展示了通用服务器基于GPT-J 6B和Llama 2 13B在一些通用场景中的推理性能差异。第五代至强在100ms内能够生成第二个token,甚至有时只需20ms或60-70ms。
从横向延迟的角度来看CPU跑大模型的能力,基本上100ms是客户业务的阈值,大于100ms时业务体验就会差一些。
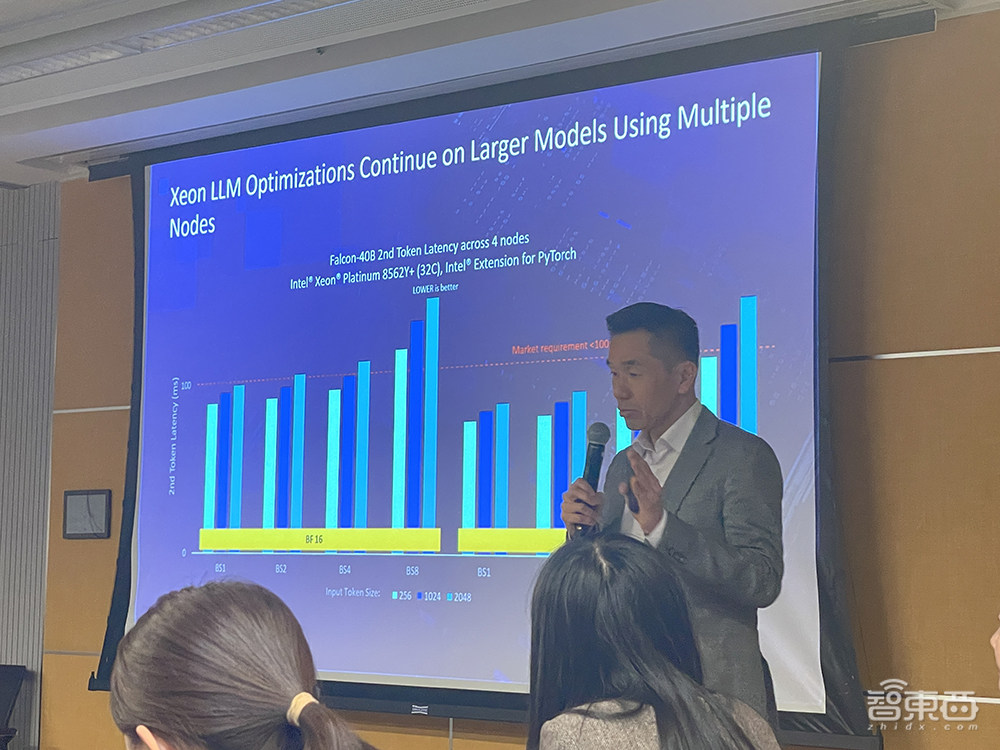
看AI应用性价比的一个评估方法是看能够同时支持多少客户的访问。英特尔看到基于BF16或者是INT8,分别在1个用户、2个用户、4个用户、8个用户时,都能满足100ms的硬需求。
这基于不同token,即输入时有多大的信息量。如果在INT8精度下,基于四节点第五代至强服务器甚至能满足同时有8个用户来访问的需求。
其合作伙伴认为,在全盘考虑部署和运维成本等因素后,一般企业导入基于至强的生成式AI服务,如聊天机器人、知识库问答等应用,比基于服务器的云服务的初期导入成本低一半左右。
此外,英特尔多家OEM伙伴推出了基于第五代至强的一体机,在7B、13B、34B的大模型推理上,通过具备AMX、AVX加速的通用处理器,可以支持参数规模大的大模型。
在降低待机功耗方面,第五代至强有单相全集成供电模块(FIVR)模式,单相模式是指在低功耗情况下不需要打开全部相,能有更高的片上电源转换效率;还有增强主动空闲模式,当CPU在功耗没有那么忙的时候,可以节省供电。
虽然在跑性能指标和压力测试时,CPU会跑到100%,但大多数真实应用场景没那么忙。一方面用户请求不那么繁忙,另一方面在很多业务要考虑到性能指标,当在满负荷的情况下,延迟性能指标通常是没有办法满足用户的要求的。
所以在真实情况下,50%-60%的利用率已是各客户中比较高的利用率。在这种情况下增加系统能效,可大幅度帮助客户达到节电目标。
二、制程技术改进与微架构升级:核心数增至64核,“四芯”爆改“双芯”
英特尔在2023年年初发布第四代至强,年底发布第五代至强,两款产品问世相隔不到一年,具体区别到底有多大?
从制程节点来看,第四代和第五代至强都采用Intel 7制程、Dual-poly-pitch SuperFin晶体管技术,具有17个金属层,包括2个厚顶层。
第五代至强优化了晶体管速度,重点关注漏电流控制和动态电容,同等功耗下频率提升3%,其中漏电流控制贡献了2.5%,动态电容下降贡献了0.5%。

其性能提升主要来自微架构升级,包括核心数量、内存带宽、三级缓存等。
第五代至强引入Raptor Cove核心,核心数从最多60核增至64核;LLC大小从1.875MB增加到5MB,而过去英特尔LLC只有1M-2M;DDR速度从4800MT/s提升到了5600MT/s;UPI速度从16GT/s提升到20GT/s;待机功耗降低;并通过和AI相关的新指令集(如AMX、AVX)来提高主频和性能,有助于加速一些生成式AI应用。

核数增加后,AI计算、科学计算和大数据都将吃到“红利”。大数据对热数据要求不敏感,其采用的是MRU(Most Recently Used)策略,处理完数据后便会清除数据。核数越多,它能够把一个大任务拆分得越细,即同时进行计算,速度会更快,核之间UPI总线也会越来越快。
具体到芯片布局,越来越高的服务器算力需求,需要CPU有更多的核心、内存带宽、I/O,这些推动芯片面积不断增加。
面积增加会带来两个挑战:一是密度变大,芯片良品率受到的挑战就变大;二是单片面积过大,可能会超过光刻机的尺寸限制。所以现在主流芯片设计是把一颗大CPU芯片切分成多个子芯片,用多芯片的方式封装在一个芯片上。
英特尔改变了SoC芯片拓扑结构,第四代至强把芯片分为相对对称的四个部分,第五代至强则把切分方式从“切四份”调整成“切两份”,高核心数版本(XCC)由2个互为镜像的芯片组成,利用3个嵌入式硅桥,有7个全带宽SCF(可扩展一致性带宽互连)通路,每个通路有500G带宽。

“双芯”设计有三个好处:一是控制面积,减少芯片通信所需互连接口占用的额外芯片面积;二是减少芯片间通信导致的功耗;三是降低延迟,从芯片内不同核心访问远端内存,或是不同核访问远端三级缓存时,可以减少访问延迟。

英特尔资深技术专家解释道,英特尔做了权衡,两个芯片虽是镜像对称,但在设计数据库的管理和验证方面基本上可以认为和芯片设计没有带来更多开销,并在具体布线上带来一定的灵活性,而且芯片面积相同,对成本没有太大的影响。
相比之下,如果采用一模一样的两个芯片,虽然在芯片设计上更省力,但将一个芯片旋转180度后,两个芯片的对齐会使互连网络设计变复杂。
上下两个芯片中间会有一些mdf连接,这是内部互连的Fabric。SCF网状拓扑互连利用英特尔2.5D封装技术,即EMIB(嵌入式多芯片互连桥接)来进行互连。虽然物理上分离,但得益于高带宽连接,两个芯片可实现逻辑上的无缝连接。
 ▲第五代至强XCC平面图(图源:Semi Analysis)
▲第五代至强XCC平面图(图源:Semi Analysis)
每个芯片内部是一个7×7模块化阵列,CPU核心和缓存在中间,DDR接口和内存控制器在西边和东边,MDF在南边。中间一共有33个硅片,整个芯片有64核,预留了2个冗余核。
UPI、PCIe和加速器在北边。为了优化I/O带宽,英特尔在北边使用两行专用的交错互连,可以最大化增加东西向带宽的上限,避免出现任何带宽上的瓶颈。
三、320MB三级缓存,5600MT/s内存带宽,核心模块平面图揭秘
第五代至强采用RPC(Raptor Cove Core)的核心模块平面图包含5MB三级缓存(LLC)、3.75MB LSF和1MB RSF。

LLC指的是5MB LLC-data,缓存里有data和TAG两部分。3.75MB LSF和1MB RSF是用来做缓存一致性的。LSF是针对两路CPU的一个特性,可以帮助确定这个数据在远端有没有别人在用,如果没有人在用,可自主对数据进行修改。
英特尔架构分为Core和Uncore。原来所有的CPU里的执行逻辑,不管是前端、后端还是L1、L2缓存,都算在Core面积里;LLC算在Uncore里。Core和Uncore都算在7×7阵列模块中。
第五代至强的所有内核共享统一LLC,每个模块的LLC容量达到了5MB,超过上一代的2.5倍,所以总缓存容量高达320MB,在设计上也可以做到同频同延迟下密度提升30%。
在内存带宽和容量方面,第五代至强DDR速度从4800MT/s提升到5600MT/s,同时将LLC容量提升了3倍。这样数据处理不需要到内存了,在芯片内部就能进行处理。
提升到5600MT/s很不容易,因为所有内存速度的增加都是在现有基板和PCB的基础上实现的,要达到更高速度,需要从芯片设计到基板设计以及链路上进行一系列提升。英特尔做了很多在芯片设计优化,包括一些MIM的内存、基板上走线的提升以及片上低噪声的供电措施等。
还有一个4-tap DFE功能,可以采集数据用来做下一个bit接收的调整,能尽可能减少码间干扰(ISI),不打开和打开DFE在5600MT/s速度下可带来非常好的信号完整性表现。

就具体应用而言,数据库类尤其能发挥LLC的优势。在数据库中,核心业务系统数据量很小,但热数据相对集中,大量的前端应用都在访问同一份热数据,如果这些热数据都存在L3之中,无需访问内存时,效率是最高的。
得益于内存I/O部分增强,第五代至强的AI推理能力实现进一步提升,包括支持20B参数以下的大语言模型,延迟可低于100ms;还有其他类型的增强,比如NLP及图像类AI的增强,主要是源于LLC、核数和内存带宽的提升。
大数据分析也会从LLC的提升中受益。不过对于有些大数据业务,数据是单次访问的,LLC体现出的优势就相对有限。
无论是内存还是缓存,面积往往会带来可靠性的问题,因为在大规模数据中心会有一个软故障,是指环境中各种因素形成一些比特的反转,当容量越大反转概率越大,错误足够多时会出现一些不可纠正的错误,导致系统宕机。
针对这个问题,英特尔在LLC当中采取了新的编码方式——DEC TED。当在一个缓存行错两位时,还可以进行纠正,出现三位错的时候还可以检测,比单位纠错和两位检错有了更强的纠错能力,极大提升了系统的容错性。增强的LLC数据修复方案也提供了更多灵活性。
还有丰富的省电功能,使得每次访问仅需唤醒低于2%的数据阵列,达到很好的节电效果。
四、AMX叠加AI加速buff,跑AlphaFold2推理性能超GPU
对于通用AI工作负载,第五代至强支持AMX和AVX-512指令集,基于OpenVINO进行优化。
在推理中,指令集上可以进行切分,通过加速器定向加速某一部分。英特尔资深技术专家称“效果替代传统的基于GPU的AI模型完全没问题”。
AMX加速器专门针对矩阵运算,将许多矩阵运算从普通CPU卸载到AMX上,让专用加速器处理专用业务,性能便会大幅提升。AMX和普通核之间的通信是通过英特尔UPI,比PCIe要快。
英特尔想为中小企业和中小模型降低整个AI的起建成本,在性能测试过程中充分释放了AMX的能力,最终可达到50%成本的下降。
这表示第五代至强在提供和GPU相似的延迟,例如在小于100ms的同时可实现更低的拥有成本。
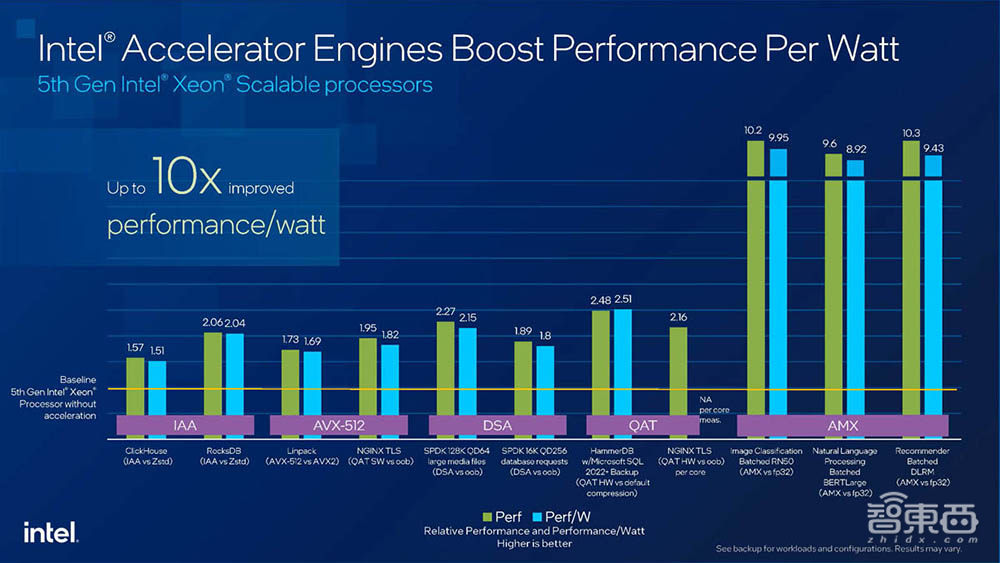
在实际应用中,很多数据中心客户更关注FP16和BF16,AMX也支持BF16。所以大部分都是以FP16或者是BF16来做的,还没有到INT8。不过AMX和底层优化的Kernel都是支持INT8的。“整体而言,我们需要做的是支持客户把int8的性能做到最高。”英特尔资深技术专家说。
在跑DeepMind AlphaFold2蛋白质结构预测模型时,基于AMX-BF16 AI加速,至强CPU能实现比GPU更高的端到端推理性能。
AlphaFold2模型的特点是参数非常高,GPU放不下,且只能放在主存里,会造成CPU和GPU频繁的交互,所以采用CPU要比GPU快很多,甚至达到几倍的提升。GPU的缓存不够,而通过重度优化CPU之后,将业务切分,并把CPU的核都利用起来,效率反而相较于GPU会更高。
英特尔AVX-512指令集在推出后便开放给了生态合作伙伴们,其ICC编译器可以直接拿去用,对底层效率有提升。
面向视频编解码应用,实时编码帧率最少需达到25FPS。在AMX-INT8加持下,第五代至强把吞吐从原来的1.5FPS增强到了33FPS,意味着可以做实时编码。“我们和原有的GPU解决方案是可以媲美的。”英特尔资深技术专家说。
五、不同层次AI软件栈优化,分布式可支持百亿参数大模型
除了硬件本身,英特尔庞大的软件团队在x86架构上进行持续优化。每一代CPU都有新特性,有赖于软件栈的使用。不管是前台支持客户还是后台做研发的工程师,大部分都在做不同层面、不同层次AI软件栈的优化。
随着第五代至强发布,英特尔将超过300个深度学习模型上传到社区,支持了超过50个基于机器学习并基于第五代至强优化过的模型,供开发者调用;并加大了对主流大模型、生成式AI模型的框架等的投入,让用PyTorch和TensorFlow开发的资产可无缝拓展到至强处理器上。
英特尔还开发了很多高性能库,比如oneDNN、OneCCL。OneDNN能把单机性能提升到最高,OneCCL提供集群式做运算的可能,让20B参数以上的模型能在CPU上做推理。同时英特尔对底层的虚拟化层、云原生层、OS Kernel层等给予了很多的资源,让最新技术能适配最新软件栈。
不同大小的模型需要不同的算力支持。如果卡在100ms延迟的标准上,一颗第四代或第五代至强可支持13B参数的模型,两颗可做到30B参数的模型。如果想要更短的延迟,只需把模型缩小。而对于6B或7B参数的模型,一颗第四代英特尔至强可扩展处理器能做到60ms。
综合来看,得益于至强处理器强大的AI能力以及内存带宽,一颗至强可扩展处理器可以为小于20B参数的大语言模型推理提供性能支持。
对于分布式,英特尔至强主要聚焦在超大模型的推理,比如超过30B参数的模型推理就需要上分布式。此外,相比于全量对计算的高要求,对于非全量的调优,CPU也是很好的选择。

在oneCCL加持下的分布式推理,可支持更大的模型。英特尔和百度一起用4台基于第五代至强的双路服务器(8颗第五代至强),采用oneCCL和RDMA(远程直接内存访问)网络,能支持70B参数的模型,推理时长可达87ms。
由此可见,CPU也可以做70B参数模型的推理,并且延迟可以达到100ms以内。
所以,GPU并非是大模型的唯一选择,CPU也有能力做同样的事。业务需要不同延迟对应不同的节点数量,将来客户也可以按需调控资源。
CPU另一大优势是灵活,无论是业务扩容还是通过分布式快速地获取部分资源,不受限制。
除了支持中、小模型外,有些企业不愿意降低模型参数量来损失业务效果。大语言模型实现了在公有云网络中使用eRDMA来加速性能。英特尔资深技术专家称,在公有云网络上,英特尔有很强的能力支持超大模型的推理。
目前AI生态都是基于英伟达CUDA构建的,如何让广大AI开发者可以更好、更快、更轻松地在至强服务器上部署他们的AI应用?
英特尔正与一站式企业级大模型MaaS平台百度千帆合作。百度千帆已开放英特尔至强大语言模型推理服务白名单测试。用户可在千帆平台中部署大语言模型推理服务时选择至强CPU平台,获得更高性价比和更低起建成本,目前已上线Llama、ChatGLM等9个大语言模型。
六、从云计算时代到AI时代,底层能源利用率成关键竞争力
解决方案旨在将底层硬件的能力充分发挥出来,真正将硬件能力转化为用户价值。
在这方面,英特尔在中国投入了许多资源,与中国生态合作伙伴针对CPU的每个特性做了大量优化定制工作。
云计算解决的第一个问题是“资源池化”,池化目的是规模化经营,将资源整合,从而最大化应用底层硬件能力。在云中进行资源池化和底层基础设施自动化时,英特尔通过IPU、XPU等使数据更靠近用户端,存放在内存中,同时通过IPU以及RDMA技术加快网络连接速度。
上端,英特尔致力于将工作负载自动化,其中包括强大的虚拟化技术,使工作负载在调取资源时能减少损耗。但此类优化在AI时代有所改变,在AI中,虚拟化的内容较少,而是转为大规模的物理机。对此,英特尔关注到三个瓶颈——算力、数据、工程化能力,这三项对底层硬件、软件和人员的需求完全不同。
云计算时代需要“压榨”资源。云厂商的核心竞争力之一是实例的性价比,既要为客户节省成本,又要能为自己也赚得收益。无论是底层硬件的升级换代,还是工作负载的优化,都需要提高端到端的性价比,关键是效率和效能的提升。
进入AI时代,数据中心耗电量极高,一台GPU服务器可达上万瓦的功率,未来建造越来越多的数据中心,可持续性将是一大挑战。
如何提升能效?有两种方式,一是为前端客户提供智能,二是自身的底层设施智能化。
英特尔在云计算时代在虚拟化技术(包括容器安全性、运行效率、底层指令集合并、操作系统优化等)上投入“重兵”,提升了虚拟化效率,同时减少了对底层硬件的损耗。到AI时代亦是如此。
譬如TDP(热设计功耗),英特尔在框架层、函数库层面上挖掘硬件能力,通过API接口调用把底层硬件能力用起来;同时在系统层、服务器,将CPU、内存、网络整合成一个统一的有机整体,因为高端GPU服务器对CPU的算力消耗也非常大;再往上,英特尔亦大规模投入语言层、模型层和垂直行业应用。
此外在数据安全和模型安全方面,数据安全涉及到数据的传输安全、存储安全、交换安全等,英特尔都有端到端的解决方案。
在安全方面,第五代至强有一个重要特性叫TDX,即整个安全环境的部署。TDX对于AI来讲也非常重要,通过将客户AI业务转移到具备TDX的CPU安全实例上,尽管性能会有一定损耗,但不仅能降低成本,而且能实现安全推理的环境。
过去10年,英特尔致力于构建一个开放的生态,通过软硬件结合帮助生态合作伙伴们充分挖掘和利用底层CPU能力。
英特尔将推出P-core(性能核)和E-core(能效核)处理器,其中P-core看重整体性能的提升,E-core看重每瓦带来的性能提升。未来,底层能源的利用率是企业的一大优势,谁的能源利用率高,转化率高,谁就更有竞争力。
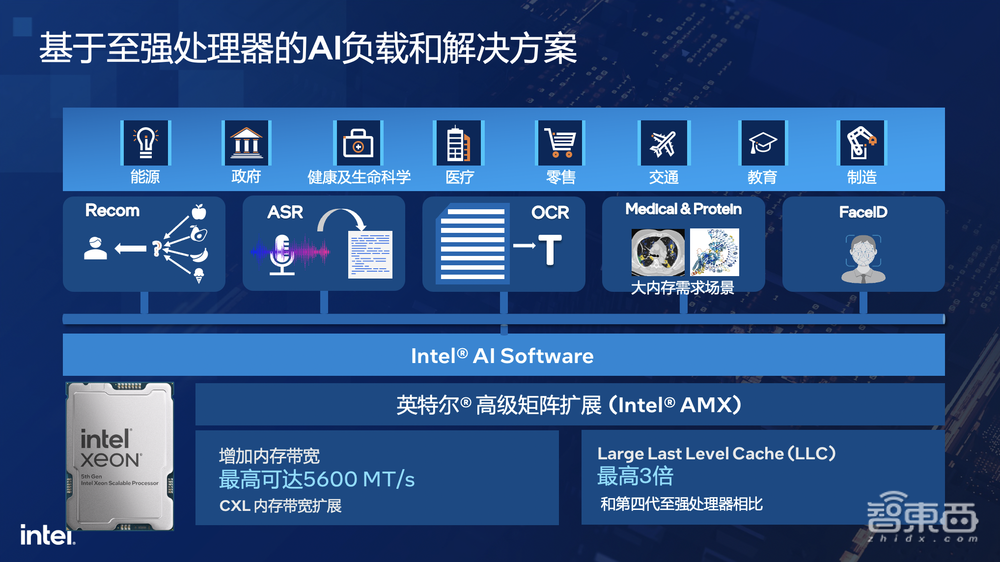
这是传统的非大模型AI应用。英特尔始终致力于在CPU上部署AI,并基于OpenVINO对整个模型进行优化、量化。包括推荐、语音识别、图像识别、基因测序等,英特尔均做了大量的优化。
对于推荐系统、大模型、稀疏矩阵等,用CPU效率更高。推荐系统的模型非常大,当GPU无法运行时,用CPU反而是主流,因为GPU不够时,就意味着需要跨GPU,或者说和CPU有频繁交互。跟主存有频繁交互时,使用CPU会更快。
结语:AI推理,节省能耗才是刚需
在总结CPU和GPU分别更适用什么场景时,英特尔资深技术专家打了个比方:
“CPU更像是一个大侠,十八般武艺样样精通,一个人可以应对很多人,单打独斗能力很强。GPU更像是军队,每个人没有什么特色,但是人多,执行的任务简单且并发高,因为GPU业务逻辑非常简单,但是核数众多。”
据分享,英特尔面向降低功耗将全方位发力,工艺逐渐提升到Intel 3、Intel 20A、Intel 18A,并用先进封装技术把不同制程的芯片通过Chiplet架构放在一起,还有针对不同工作负载做优化,以及微架构、微工艺的调整,每一代都会有两位数的功耗降低幅度。
有时调整应用程序的架构能最大限度降低功耗。例如,训练大模型,假设总共有20个大模型,每个模型的训练周期为3个月,需要1000台机器来训练,每台机器功率为1万瓦。如果规定只需训练其中的5个模型,而剩下15个模型不需要训练,这样就能节省75%的电能。
如今GPU昂贵且难以获得,对于处在业务发展初期的企业而言,在综合考虑产品是否易买、资源是否能充分利用、成本、延迟等因素的前提下,用CPU做大模型推理不失为高性价比的选择。
