








智东西(公众号:zhidxcom)
作者 | 长颈鹿
编辑 | 李水青
智东西4月8日消息,据《纽约时报》6日报道,多年来,互联网似乎是无穷无尽的数据来源。但随着AI的进步,各个AI实验室已经利用了所有可靠的英文文本数据来训练他们的AI系统,但他们意识到为了进一步提高系统的性能,他们需要更多的数据来进行训练。因为更多的数据可以帮助系统更好地理解语言的不同用法、语境和含义,从而提高大模型的准确性和适应性。
OpenAI、Google、Meta等科技巨头公司正在涉入一个“灰色地带”来收集更多的数据用于训练AI模型,其中一些公司正在尝试开发“合成”信息。
一、曝OpenAI挪用100万小时油管数据,训练GPT-4
AI领域正快速发展,特别是在大型语言模型的开发方面。2020年11月,OpenAI推出了GPT-3,它是在一个庞大的数据集上进行训练的,大约包含3000亿个token。GPT-3展示了在各个领域生成文本的惊人准确性,包括博客文章、诗歌,甚至计算机程序。2022年,谷歌的AI研究实验室DeepMind,表现最好的模型超出了预期,其中一个名为Chinchilla的模型被训练在惊人的1.4万亿个标记上。2023年,中国的研究人员发布了Skywork,这是一个在包括英文和中文文本在内的3.2万亿个标记的数据集上训练的AI模型。
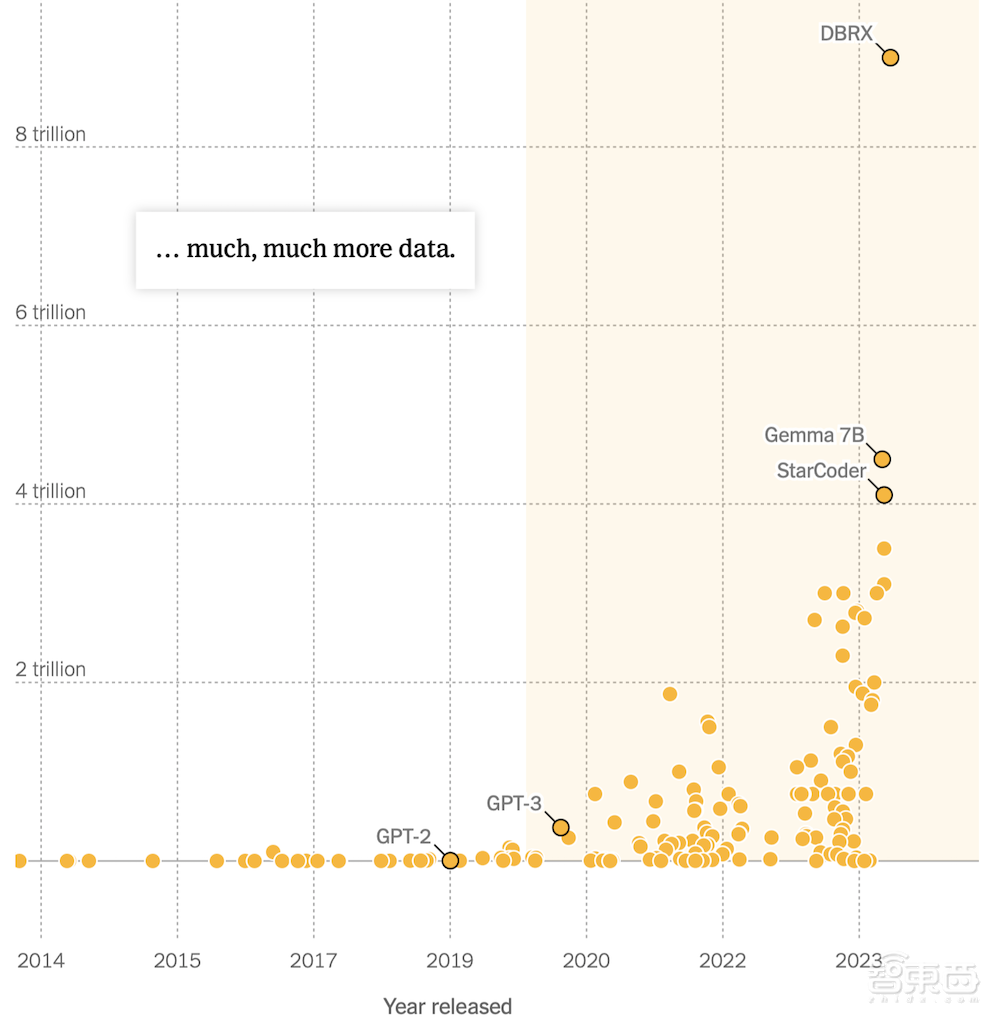
▲AI大模型训练数据(来源Epoch AI)
因此,OpenAI研究人员创建了一个名为Whisper的语音识别工具。它可以转录YouTube视频中的音频,产生新的对话文本,使AI系统更智能。
2023年初,OpenAI团队转录了100多万小时的YouTube视频,以文本形式输入到GPT-4系统中并发布。该系统被广泛认为是世界上最强大的AI模型之一,也是最新版本的ChatGPT聊天机器人的基础。

▲在OpenAI发布ChatGPT后,谷歌的研究人员和工程师讨论了利用其他用户数据开发AI产品的问题(来源:纽约时报)
2023年,谷歌扩大了其服务条款,以允许利用公开可用的在线资料用于其AI产品的开发。据该公司隐私团队成员和《泰晤士报》查看的内部消息称,这一变化的动机是为了让谷歌利用公开的谷歌文档、谷歌地图上的餐厅评论和其他在线材料,以提供更多的数据来训练和改进他们的AI产品。
与此同时,根据《泰晤士报》获得的内部会议录音,Facebook和Instagram的母公司Meta,在2023年讨论了收购Simon&Schuster出版社以获得图书的全部使用权。他们还从互联网上收集受版权保护的数据,即使这意味着面临诉讼。他们说,与出版商、艺术家、音乐家和新闻行业谈判许可证需要很长时间。
这些公司的行为说明了在线信息在AI领域中的重要性。新闻、小说、社区留言、维基百科文章等,提供了丰富的数据资源,使得AI技术能够学习和理解人类的语言,从而创造出更加创新性的技术。正如约翰·霍普金斯大学理论物理学家Jared Kaplan阐述的那样 “训练大模型语言的数据越多,其性能就越好。”
二、增强训练大模型,引发道德争议
去年起,AI巨头OpenAI和微软受到了许多关于版权和许可的诉讼和争议。
《泰晤士报》去年起诉OpenAI和微软,控诉他们在未经许可的情况下使用受版权保护的新闻文章来培训AI聊天机器人。但两者均表示他们使用这些作品是在版权法允许范围内的“合理使用”,因为他们认为这种做法仅是为了发展人类的未来趋势—-AI。
以OpenAI总裁Brockman为主的团队收集了YouTube视频数据开发了GPT-4。据知情人士透露,谷歌也转录YouTube视频并利用在线资料收集文本来训练其AI模型,即使他们意识到这种做法可能侵犯版权。

负责全球合作和内容的Meta副总裁Nick Grudin(来源:Variety)
Meta为了增强训练自身大模型,在内部会议也展开了针对数据不足的道德探讨。根据内部员工分享的录音,Meta的高管谈到他们如何在非洲聘请承包商来汇总小说和非小说作品的摘要。这些摘要有些受到版权保护,但他们不得不收集这些内容。
OpenAI似乎在没有获得许可的情况下使用了很多受版权保护的材料。他们表示,与出版商、艺术家、音乐家和新闻行业进行许可协商也许会花费太多无意义的时间。Meta觉得,唯一阻碍产品成为ChatGPT一样好的东西实际上只是数据量。
三、解决数据短缺,开发 “合成”数据
科技公司非常渴望新数据,以至于一些公司正在开发“合成”信息。合成信息指的是系统从它们自己生成的内容中学习。
OpenAI的高管们认为,由于AI模型可以产生类似人类的文本,这些系统可以创建额外的数据来开发更好的自己版本。这将帮助开发人员构建越来越强大的技术,并减少对受版权保护数据的依赖。OpenAI的CEO Altman也赞同“只要能跨越合成数据的界限,也就是说,让模型足够聪明并能生成好的合成数据,一切都会好的。”
但建立一个可以自我训练的AI系统说起来容易做起来难。从自己的输出中学习的AI模型可能会陷入循环中,强化产品的怪癖、错误和局限性。
为了解决这个问题,OpenAI和其他公司正在研究两个不同的AI模型如何协同工作,以生成更有用和更可靠的合成数据。一个系统生成数据,第二个系统判断信息以区分好与坏。但研究人员对此方案仍存在分歧。
结语:数据荒来袭,大模型的新挑战
AI巨头们对AI大模型的进步仍旧在探索环节,一些做法步入了 “灰色”地带存在道德争议,一些合成数据的创新也仍旧模糊。所以界定科技企业使用公共数据和其合法来源来训练AI大模型仍是业界任重而道远的问题。
来源:纽约时报
