








智东西(公众号:zhidxcom)
作者 | GenAICon 2024
2024中国生成式AI大会于4月18-19日在北京举行,在大会第一天的主会场大模型专场上,安谋科技产品总监杨磊以《大模型端侧部署提速,NPU赋能终端算力革新》为题发表演讲。
从GPT-3.5到GPT-4.0,从多模态交互到插件支持,从闭源到开源,AI任务处理正加速从云侧向端侧迁移,NPU及其生态迎来全新的发展阶段。安谋科技产品总监杨磊谈道,生成式AI正逐步成为客户端设备上的人机交互界面,而具备100亿参数级别的大模型已成为现有终端设备的最佳匹配规格。
然而,在终端部署这类AI大模型时,仍面临成本、功耗及软件生态等多重挑战。在当前大模型发展的硬件驱动方面,杨磊认为异构计算才是本地部署端侧大模型的理想选择,它能最大限度地提升SoC的性能、能效以及面积利用率。其中,NPU作为端侧AI应用的关键算力资源,将为大模型的分布式落地演进提供核心动力。
当前,随着大模型持续向边缘侧和端侧渗透,AI计算和推理工作逐步由云端迁移至手机、PC、智能汽车等终端产品上运行。在这一过程中,NPU能够以其更简单的控制流、更高的效率以及更低的功耗,处理AI工作负载。安谋科技自研“周易”NPU面向大模型场景做了架构、内存墙等多方面改进,正在研发的下一代“周易”NPU将采用多核设计,能够同时支持卷积神经网络(CNN)和Transformer架构,将会适配国内外多个主流大模型。
一、生成式AI革新人机交互界面,端侧大模型应用有望迎来爆发
近年来,大模型不仅在对话式文本方面取得巨大成功,也在图像处理、音视频生成等多模态领域展现出强大的潜能。随着生成式AI在人们日常工作及生活中被广泛应用,数据处理和存储需求急剧增加,使得智能计算体系结构发生根本性转变。
大模型对人机交互界面产生了深刻的影响,生成式AI已成为人与终端设备的最新交互界面。在生成式AI加持下,从写作、编程、绘画到视频创作,多种模态的内容创作门槛正被前所未有地降低,人机交互的流程也被大大简化。
在杨磊看来,端侧设备的核心交互问题关乎入口,这是争夺用户时间、持续时长、资金投入的关键所在,也是业内竞争的焦点。以典型的端侧设备——手机为例,在本地设备上运行大模型已是兵家必争之地,各家手机大厂都在想方设法占据这一入口。
在此过程中,一方面,多模态模型正成为大势所趋;另一方面,针对不同的应用场景、设备或成本考量,众多厂商都推出了不同参数规模的模型。以智能手机为例,旗舰手机芯片算力可达40~50TOPS,中档手机的算力在10~20TOPS的范围内,而入门级手机目前尚未专门配备AI能力,更多地依赖于CPU的通用计算能力。

据杨磊预测,随着半导体技术的持续演进,旗舰手机的算力水平有望达到100TOPS,入门级手机也将从当前的无算力水平提升至5~10TOPS范围。预计两年后,不论是高价位段的手机,还是性价比优良的千元机,都有望具备本地部署AI大模型的硬件计算能力。
此外,在杨磊看来,除智能手机和PC等终端设备外,如今智能化水平不断提速的新能源汽车以及目前炙手可热的人形机器人也是大模型落地的硬件载体之一。在大会现场,杨磊列举了一些数字:目前智能汽车的算力已经能达到500TOPS左右,一些机器人方案也在按照这一算力规模进行相应的技术规划。
尽管AI大模型的应用日趋普及,比如手机上安装了Kimi、豆包、文心一言等诸多应用,但这些应用尚未达到杀手级应用的水平,实际上很多端侧硬件的计算能力已经领先于相关应用的发展。很多用户更多是出于猎奇心理来试用这类应用,并没有产生持续、频繁且高度黏性的使用需求。
“我们目前仍处于硬件先行、应用后发的阶段。安谋科技则希望结合自身独特的技术优势,打造软硬一体且极具竞争力的解决方案,推动AI大模型在端侧设备加速落地。”杨磊谈道。
二、端侧大模型部署面临三重考验,异构计算将是最优解
目前,AI PC、AI手机、“大模型上车”等细分领域已成为终端设备厂商以及半导体行业争相入局的热门赛道,那多大参数规模的大模型适合在端侧部署呢?杨磊将端侧大模型的主流参数范围总结在3亿到100亿,许多业内厂商也都在关注百亿参数这一规格。
兵马未动,粮草先行。尽管大模型应用还未全面爆发,但端侧大模型高效落地必然需要一个可靠的硬件载体,其应用需求涵盖了多个方面,比如大语言模型用于交互、多模态模型用于识别和理解、对实时计算的响应需求等,使得算法能轻松部署在不同硬件平台上,并确保在端侧的运行速度足够快,而不是仅仅能在云端运行。
在杨磊看来,目前端侧大模型部署面临着三重难关:

首先是成本。端侧设备由于使用范围广且频次更高,因而对于成本也更加敏感。不能单纯为了增加AI能力而导致手机或PC的售价上涨太多,由此带来的现实要求则对芯片面积、存储带宽、能效和计算资源这类与成本强相关的因素多加考量和平衡。
其次是功耗。无论是PC、平板电脑、手机还是智能眼镜,其大部分的使用模式都由电池供电,功耗和电池容量决定了设备的续航时长。一张高性能的GPU动辄功耗数百瓦,更适合在云端使用,而非手持设备。相比之下,一般手机的功耗则不超过10瓦,这就要求芯片在兼具算力的同时,也要尽可能降低功耗,以保证设备的使用时长和控制发热。
第三是软件生态。硬件平台需要支持不同的应用场景,让来自不同企业的不同类型算法都能被轻松部署,并且计算效率和速度符合预期,这就涉及到一些软件生态和投入。由此,选择软件适配度高、开发工具和资源更为丰富的技术生态也非常重要。而Arm技术已成为全球应用最广泛的计算平台之一,具有显著的软件生态优势。
对此,杨磊认为,在硬件成本、功耗和软件生态三重难关之下,即使在端侧设备,单纯依靠传统的CPU或者GPU等通用计算单元也难以满足当前以Transformer架构为主的大模型计算要求。因此,结合各种算力单元特性的异构计算将是端侧大模型部署的最优解决方案。

三、抢占端侧部署大模型制高点,安谋科技打造高性能异构计算IP平台
异构计算其实是近年来业界比较热议的话题。其核心在于多种计算单元在SoC上的异构组合,即在硬件方案中协同使用CPU、GPU、NPU等多种不同类型的计算单元,实现更高效的计算能力,以平衡成本、功耗、计算性能等。
对此,杨磊在大会现场进一步阐述异构计算为何更适合端侧大模型部署的背后原理。举例来看,要在手机上部署一个“压缩版”的ChatGPT或Llama大语言模型,其实最大的难点不在于计算量,更为棘手的是数据访问量,即内存墙。杨磊解释说,目前AI大模型除了对话式的语言类应用场景以外,还涵盖了文生图、文生视频等场景,这类应用所涉及的大量AI计算任务对于端侧设备里原有的CPU或GPU来说就比较吃力,更适合调用专为AI设计的计算单元NPU来进行计算。
对此,安谋科技将全球领先的Arm CPU、GPU等通用计算单元,与本土自研的NPU、SPU、VPU等专用计算单元相结合,打造一体化、高质量的异构计算IP平台,持续助力本土芯片创新。
其中,正如前面提到的,NPU作为面向AI计算场景应运而生的计算单元,自然也是加速端侧AI应用的关键算力资源。对此,杨磊重点介绍了安谋科技针对深度学习而自研的人工智能处理器——“周易”NPU。
目前,“周易”NPU已迭代了Z系列和X系列的多款产品,满足多样化计算需求。其中,Z系列主要面向AIoT市场,为物联网设备提供AI算力支持;X系列则主要面向车载、边缘计算等高算力应用场景,进一步提升计算效率。以安谋科技最新发布的“周易”NPU为例,该产品采用第三代“周易”架构,在算力、精度、灵活性等方面均有大幅提升,支持多核Cluster,最高可达320TOPS子系统,为新兴领域不断迭代的计算需求提供更为完善的解决方案。
据杨磊补充,“周易”NPU将针对端侧大模型场景进行专门的升级优化,包括微架构改进、内存优化、并行结构升级等多个方面,并透露正在研发的下一代“周易”NPU将会适配国内外多个主流的开源大模型方案,覆盖硬件及其配套的软件工具。
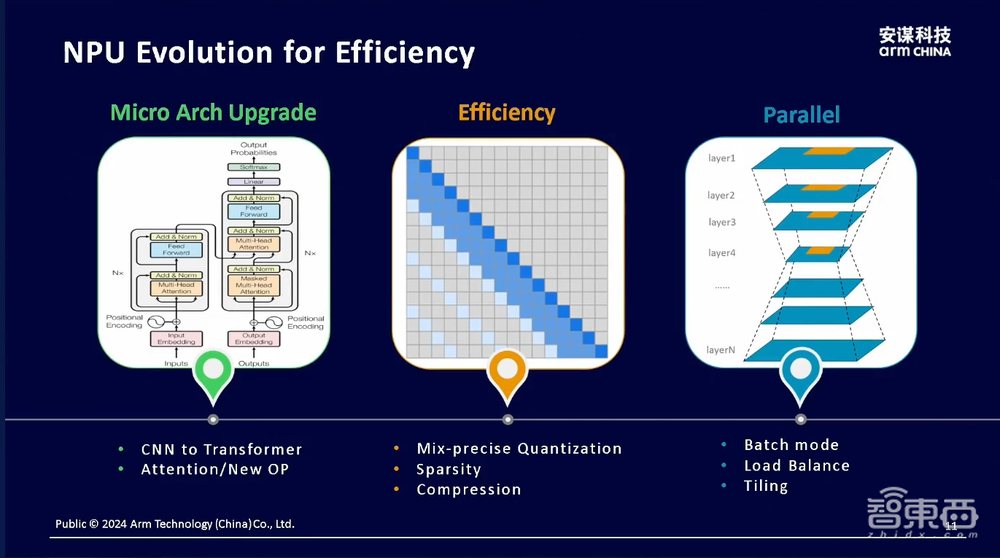
在微架构方面,“周易”NPU架构将面向Transformer结构进行专门的加速改进;在内存方面,“周易”NPU也会针对存储限制做进一步优化,包括常见的低比特量化技术等;而在并行计算方面,下一代“周易”NPU则重点考虑满足并行计算的需求,能够同时支持卷积神经网络和Transformer架构,更好地满足当前应用端的不同场景需求。
此外,据杨磊介绍,安谋科技的下一代“周易”NPU将采用多核架构,能够根据不同场景需求来配置不同的算力,例如AI PC等高算力场景可配置多个NPU核心,而AR眼镜等更需平衡性能和功耗的场景则可以考虑配置单核,多核架构可以更好地满足算力从小到大的灵活扩展。
结语:端侧大模型爆发将至,安谋科技提供底层核心技术支撑
技术进步为大模型在云边端的部署提供了广泛的可能,大至在成百上千张卡的大型集群上做训练,小至在手持设备上部署,大模型正通过越来越多元的硬件载体,走进千家万户和千行百业。
在云端,国内外已有很多GPU和AI芯片企业在开展相关工作。但在边缘端侧,目前还没有一个成熟、统一的硬件平台,能够支撑大模型部署到手机、PC或机器人等设备上,因此市场潜力巨大。
“端侧设备已成为大模型部署的兵家必争之地”,杨磊如此形容端侧大模型的竞争态势。综合来看,抢占入口的不止是硬件设备制造商,还有众多算法开发者,以及像安谋科技这类专注于芯片底层技术创新的企业,大家不约而同地看到了其中蕴藏的市场机会。
杨磊最后谈到:“AI大模型不仅仅部署到云上,未来在端侧也将迎来爆发式增长,我们非常期待与产业链上下游的伙伴们加强沟通与合作,携手共赢生成式AI未来。”
