








智东西(公众号:zhidxcom)
作者 | GenAICon 2024
2024中国生成式AI大会于4月18-19日在北京举行,在大会第一天的主会场开幕式上,北京大学助理教授、银河通用机器人创始人&CTO、智源具身智能中心主任王鹤以《通向开放指令操作的具身多模态大模型系统》为题发表演讲。
成立于2023年5月的银河通用机器人,是国内具身智能代表初创公司之一,迄今已完成4轮融资,美团是公司外第一大外部股东,北大燕缘创投、清华无限基金SEE Fund均是投资方,其累计融资额已超过1亿美元。
作为国内具身智能领域资深专家,王鹤详细解读了具身智能大模型的定义、范围和关键技术。他谈到目前面向通用机器人的具身多模态大模型的局限在于数据来源有限、很难高频输出动作。应对这两大挑战的方向,一是通过仿真世界提供训练数据,二是采用三维模态模型提升泛化性和速度。
对此,银河通用机器人构建了三层级大模型系统,包括硬件、仿真合成数据训练的泛化技能、大模型等。基于该系统,机器人可实现跨场景、跨物体材质、跨形态、跨物体摆放、依据人类语音指令进行的开放语义泛化抓取,成功率达95%。
以下为王鹤的演讲实录:
今天我带来的内容与机器人相关,这个话题也是今年“AI+”中最火热的话题之一。
大模型公司OpenAI和机器人公司Figure AI联手演出,让我们看到机器人在厨房里拿苹果、端盘子、放杯子的惊艳视频。还有巨头英伟达在GTC大会官宣要做Project GROOT,GROOT就是通用机器人。
那么,对于通用机器人我们的期待是什么?就是它能像人一样干各种各样的体力劳动,可以实现我们告诉机器人指令,它通过视觉去看、各种传感器去感知,然后连续高频输出动作,也就是能够听懂我们跟它说的任务指令。这就是“言出法随”。
此外,机器人还应该做到环境泛化,在家庭、工厂、商超等不同的环境中工作。
这样的通用机器人显然不是只造出机器人本体就可以,那么背后的技术是什么?什么赋予了它这样的能力?就是具身多模态大模型。
一、拆解大模型分类,自动驾驶是典型的具身大模型
具身多模态大模型就是能高频输出动作的大模型,我将其分为非具身和具身大模型两类。
今天前面看到的一些大模型实际是非具身大模型,如GPT-4、GPT-4V、Sora等,它们的特点是,输出都是给人看或者给人读的。无论语言、图片还是视频大模型,最终服务的对象是人,显示的设备是各种手机、电脑、AR设备等。
而具身大模型的特点是:拥有一个身体,最终输出的对象是身体的运动。
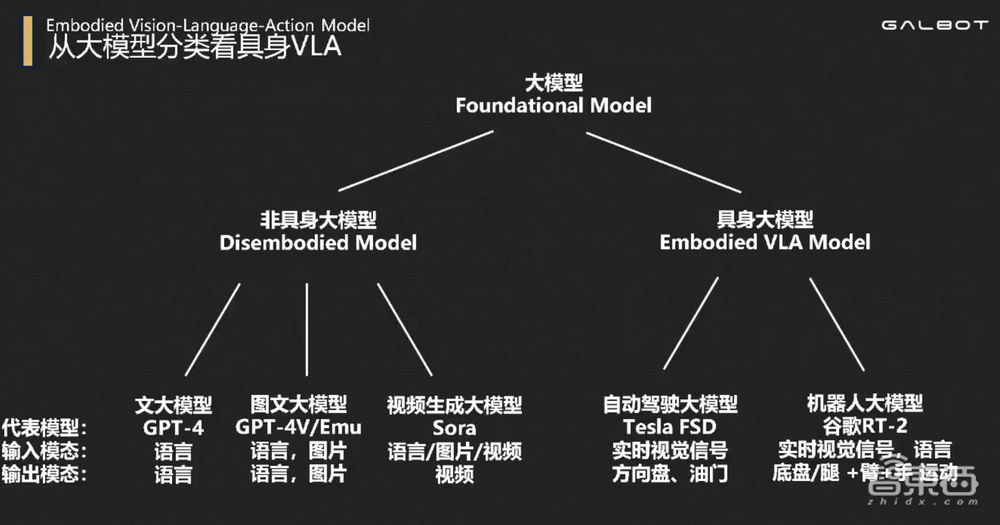
这样来看,自动驾驶大模型就是一种典型的具身大模型,比如特斯拉的FSD全自动驾驶系统,今年8月号称要开始无人出租车业务Robotaix。
自动驾驶大模型的输入是视觉信号和终点的位置,输出是方向盘的动作和油门、刹车的大小。机器人相比于车来说,动作空间自由度更高,输出是底盘或者腿、手臂、手指等全身的运动。这样的机器人大模型也是这几年学术界、工业界研究的热点。
谷歌RT-2大模型是端到端的具身大模型代表,能够把香蕉放到写有“3”的纸上,把草莓放到正确的碗里。“找到正确的碗”,这背后需要大模型的通用感知和理解能力,以及连贯的动作生成能力。还有把足球移到篮球旁边,把可乐罐移到Taylor Swift的照片旁边,将红牛移动到“H”字母上。
这样的具身大模型,如果能完全达到Open-Instruction(开放指令)、Cross-Environment(跨环境泛化),就能替代大量的体力劳动。
今天,全球语言大模型、视频大模型、图片大模型、自动驾驶大模型的市场规模都达到至少千亿美元,试问如果能有一个完成任何指令的机器人代替人,它的市场规模会有多大?可能相比于目前车的市场提升两到三个数量级。
二、通用机器人面临两大局限性:数据来源有限,机器人反射弧长
谷歌的RT-2大模型背后就是通过多模态大模型输出动作,那么这样的大模型是否已经成熟了?是否今年我们可以期待有机器人保姆在家里干活?目前,无论OpenAI、英伟达,还是谷歌,做通用机器人都还有巨大的局限性。
谷歌的技术局限性第一点在于,具身机器人数据来源非常有限,谷歌在Mountain Village(美国加州)办公室的厨房里采集了17个月,得到13万条数据,使得其机器人在谷歌的厨房里表现可以非常好。
但一旦出了这个厨房,需要考察其环境泛化性,它的成功率就从97%骤降到30%左右。并且这种泛化是有选择的泛化,不是将其直接放到施工工地、非常嘈杂的后厨等场景中,它最大的问题就是数据采集没有办法做到Scalable(可扩展)。
今天,有百万台车主在开特斯拉,为特斯拉的端到端自动驾驶模型提供数据,互联网上有无穷无尽的用户上传的照片等作为多模态大模型的数据,那么机器人大模型的数据在哪儿?这是谷歌、OpenAI、英伟达没有完全解决的问题。
第二点局限为,RT-2大模型中包含了谷歌上一代大模型PaLM-E,它的速度只能达到1~3Hz,机器人的反射弧长达0.3秒甚至1秒,这样的机器人恐怕你也不敢用。
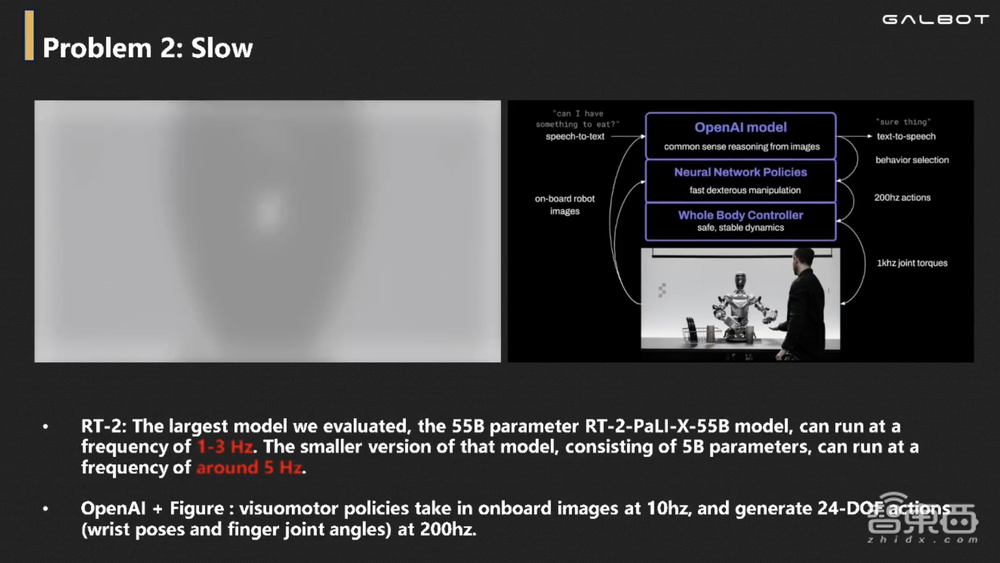
OpenAI和Figure AI合作用的是小模型,它能够达到200Hz的动作输出频率,大模型如何做到以200Hz的频率输出动作也成为通用机器人领域的重要问题。
三、打造三层级大模型系统,解决泛化、响应速度难题
今天给大家带来一些银河通用在这个问题上的探索。
如何能够做到又快又泛化?泛化说的是数据问题,今天真正可以满足机器人大模型需求的数据且含有动作标签的数据,只能来自于仿真世界、物理传感器。
在2017年,我读博士期间就开始研究如何通过仿真生成大量的合成数据,来训练机器人的视觉和动作。今天我们可以把各种家用电器等物体搬到仿真设备里面,并且可以真正做到物理仿真,机器人要沿着一定方向用力拉抽屉,而不是像游戏里面手一过去抽屉就弹开了。如果是那样的话,机器人学到的东西在真实世界里面没有用。
我们在仿真世界里面放满了各种各样的物体,赋予它跟真实世界相同的交互方式,我们再把传感器放到仿真环境里面去训练,就拥有了一个足够好的数据生成来源。
那么如何做到快?就是小模型,如同OpenAI和Figure AI的小模型一样,高频输出动作。三维视觉的小模型给我们带来了一个比Figure AI更好的选择方案。
Figure AI的方案采用了二维视觉模型,二维视觉模型最大的特点是很难泛化。如果你之前在黑色房间做训练,那么换成白色的房间此前的训练就白费了。三维视觉看到的是点云、物体的几何,不会受光照、纹理、颜色影响。
那么,这样可以做到泛化、快,还是从仿真数据里面学习的模型,能不能解决我们真实世界开放与易操作的问题?今天我把我们做的标志性成果跟大家分享一下。
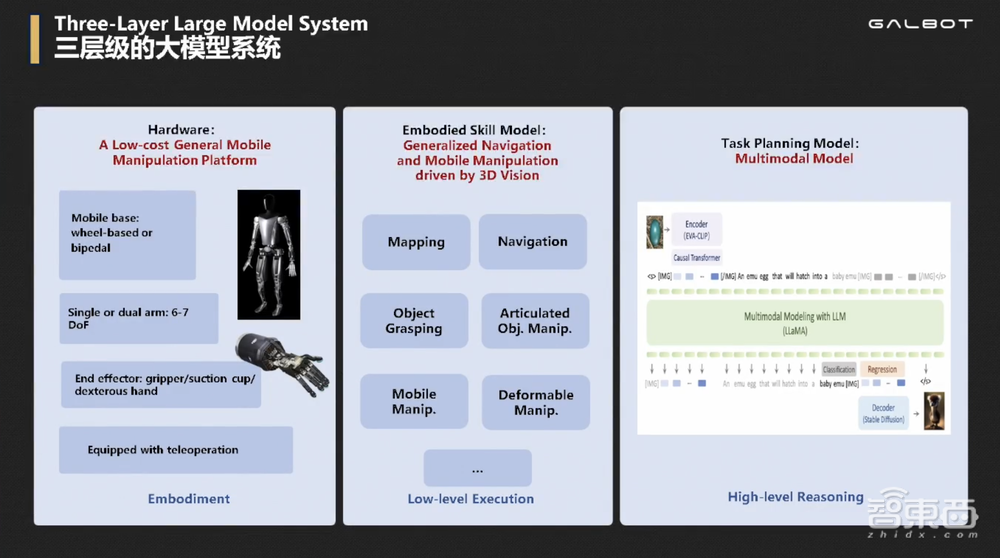
我们用的是三层级大模型系统,底层是硬件层,中间层是通过仿真合成数据不用任何真实世界数据训练的泛化的技能,包括自主建图、自主导航、物体抓取、开门开抽屉开冰箱、移动操作、挂衣服叠衣服柔性物体操作的泛化技能。
这里谈泛化的原因为,我们可以在仿真环境里生成千万级场景,十亿规模的动作来训练机器人,让其可以应对各种真实世界的情形和挑战。这种采集方式,相对于在真实世界里用遥控器遥控机器人采集具有极高的效率和丰富的数据来源。
最上层是大模型,可以调度中间技能API,来实现完整的从任务的感知、规划到执行的全流程。
四、大型仿真平台Open6DOR,破解六自由度操作难题
先展示第一个例子,我们如何做开放语义关节类物体的操作。
我们与斯坦福大学合作,机器人执行开关微波炉、开锅、使用搅拌机等任务时,背后不是靠我们去挨个训练不同类别,而是直接在这些物体上测试我们的模型。
这一技能来源于CVPR 2023的满分论文,我们提供了世界上第一个以零件为中心的数据集,该数据集覆盖了各种家用电器上可能存在的主要操作零部件,包括旋转盖、推盖、转钮、按钮、直线把手、圆形把手、门等。
然后我们把这些零部件放在仿真世界里面,并标注了它的位姿、所有轴的使用方法,从而帮助推理相应开门等操作的方法。
这样的合成数据集就能教机器人如何去开生活中没见过的柜子,机器人只要有三维点云、找到把手的位置,正确抓取把手在沿着柜子的方向一拉就可以打开任何抽屉。
我们的实验也证实了机器人可以完全依赖仿真世界的数据,实现真实世界里关节类物体的泛化操作,包括没见过的物体类别,如遥控器、计算器、圆形把手的锅盖等。图上面是三维视觉的输出,下面是机器人技能的展示。

这样的技能如何与大模型相结合?GPT-4V与我们十分互补,GPT-4V是典型的二维语言双模态大模型,它具有很强的推理和感知能力。但其缺点在于,会偶尔看不出来,对物体零部件的数量判断错误,且不知道零部件在三维空间中的具体位置,定位能力为零。
三维视觉的模型就可以提供GPT-4V检测到零部件的数量、位置和形态,把它作为Prompt交给GPT-4V,让它去思考这个东西怎么去用。
我举一个例子,当我们直接把检测到的微波炉零部件交给GPT-4V作为Prompt时,让它生成关于这个场景的综合描述,它会说这个微波炉有直线门、直线把手、按钮和旋钮,然后问它:“如果我想打开微波炉,我应该动哪个零部件?使用哪个API?”
大模型的回应是“动把手,调用的API是绕门轴转90度”。那么,把手在哪里、门轴在哪里是三维视觉给它的,GPT-4V不能输出三维的坐标和位置。
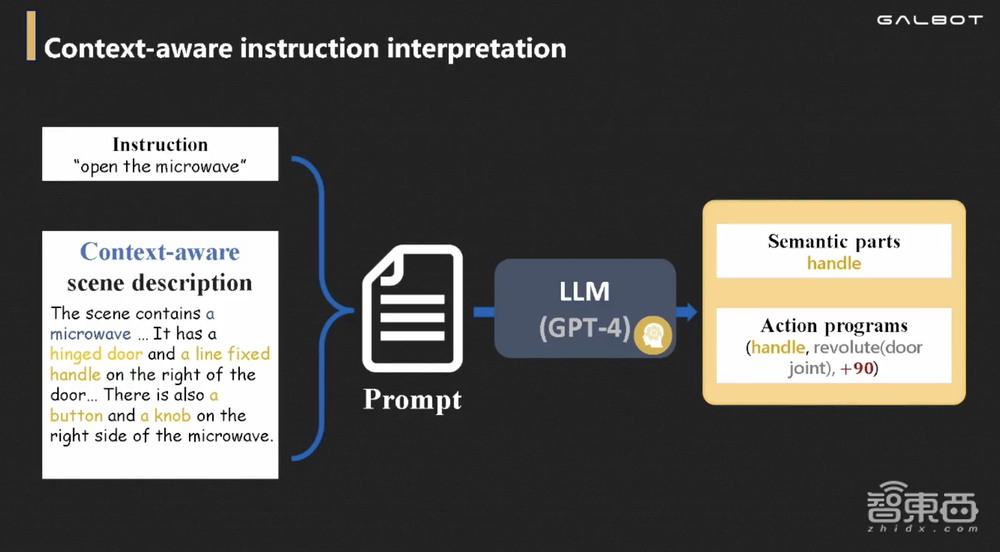
然后机器人尝试时,我们发现这个操作看似合理,但实际操作却打不开,这是为什么?因为微波炉不可以靠蛮力开,这时候我们将“门没有打开,只旋转了零点几度”的三维视觉反馈给GPT-4V,问它接下来怎么办。
大模型给出操作时,可以调用检测出的按钮再开门。这体现了大模型通过丰富的语料训练,已经产生了足够多的知识。我们可以直接信任它进行操作。
这样的例子很多,我们最开始讲的家用电器的零部件,GPT-4V知道零部件的位置等就可以进行操作。这是真正的Open-Instruction(开放指令),它关于环境是泛化的,不受环境的颜色、光照影响,只关心几何。
第二个例子是如何做到六自由度物体的自由摆放。六自由度指的是三自由度的平动、三自由度的转动。
谷歌的工作是三自由度的开放语义操作,它只能做到放在哪儿,不能做到朝哪儿放,其没有方向改概念只有位置概念。我们在全球率先提出桌面级操作要解决的里程碑难题就是六自由度操作,能够在桌面同时执行位置和朝向的指令,我们将其命名为Open6DOR。
Open6DOR是大型仿真平台,里面包含2500个各种各样的任务。这些任务不用于训练,而是拿来检测具身多模态大模型能不能完成,这其中有200多个家用常用物体。
其主要关注三类任务追踪,第一是只关心位置,比如把苹果放到勺子的右边、把瓶子放到锤子和改锥的中间,这就是Position-track;第二是Rotation-track,把锤子冲向左、易拉罐的标签朝左、把碗上下颠倒。而实际我们需要的是Position+Rotation的任务执行,也就是六自由度Track,比如把盒子放到锅和锅盖之间并让标签冲上,或者把卷尺放到中间且让它立起来,像这样的操作是桌面级操作里的关键性里程碑。

谁能够率先完成2500个任务,就说明你的大模型已经初步具备了Open Instuction能力。
五、三维视觉小模型快速生成动作,大模型规划
目前,针对2000多个任务,我们自己提了一套方法。
首先是抓取能力,这是银河通用的独有技术,我们研发出全球首个可以实现基于仿真合成数据训练任意材质的技术。通过海量的合成数据,我们在全球第一次达到了跨场景、跨物体材质、跨形态、跨物体摆放实现泛化抓取,并且首次达到95%的抓取成功率。
此外,对于纯透明、纯反光等物体的泛化抓取对于二维视觉、三维视觉都有极大的挑战性。可以看到,我们的方法能实时将透明高光物体的深度进行重建,并据此进行物体抓取。
下图中演示的抓取不是简单的从上往下抓,它其实是六自由度的抓取,既有三自由度的转动,又有三自由度的平动。此外,当其耦合大模型后,可以实现开放语义的物体抓取,从抓取能力上今年我们已经实现了泛化的一指令抓取。

那么如何做到位置抓取有效?下面四张图演示的指令分别是,抽一张纸盖在改锥上、把瓶子竖直放到红碗里、把足球放到抽屉里、把水豚放到金属杯子里面。
它背后是怎么做的?首先我们要用GPT-4V提取指令中的关键信息,这里的指令是“把水豚放到写着‘Open6DOR’的纸上,并且把水豚冲前”,我们用GPT-4V+Grounded-SAM把所有的物体进行分割,并且把其三维Bounding Box(边界框)输出给GPT-4V。GPT-4V理解这些物体现在的位置后,就会输出应该把物体放在哪个位置的指令。
那么旋转怎么办?GPT-4V是否可以直接输出旋转矩阵?输出机械臂左转上转横转分别多少度?答案是不能,GPT-4V没有这个能力,它并不知道转轴在哪里。
我们在全球提出了Real-same-real的Pipeline,先将真实物体在仿真环境里面重建,再把重建的物体Mesh自由落体撒满整个仿真环境,让物体处于各种可能待的位置。然后将这些位置交给GPT-4V评判,谁满足语言指令的需求,随后GPT-4V通过两轮筛选,选择出符合指令物体的摆放位置。

这样的仿真是全并行,可以很快完成,其中比较慢的就是GPT-4V需要在很多张图里选最好的一张图。我们会将十张图拼成一张图,上面打出标签0~9,GPT-4V直接输出选择哪个,可以同时解决位置在哪儿、朝向在哪儿的问题,后面就用我们的抓取算法结合路径规划,将任务完成。
我今天谈的例子是,当我们用GPT-4V端到端去做动作生成时,它并不快,就像视频生成现在是离线的一样。而机器人需要在线实时生成,因此我们提出了用中间的三维视觉小模型进行动作快速生成,大模型进行规划的三层级思路。
但未来还是端到端,谁能做好端到端的视觉、语言、动作大模型?这里隐含了一个条件——没有做好小模型的公司、没有能让动作小模型泛化的公司,不可能让大模型泛化。因为大模型在单一任务上的数据需求远高于小模型。
银河通用携带着一系列从抓取、放置、柔性物体操作到关节类物体操作等各种小模型,我们将百川归海,最终融汇到大模型里实现通用机器人。在这一点上,我们已经率先打造了全球首个跨场景泛化的导航大模型,你可以用一句话让机器人在没见过的环境里面跟着指令走,这样的机器人没有任何三维定位、建图、激光雷达,只有图片作为输入,这与人走路找路的方式一模一样。
我们相信这样通用、泛化的端到端的Vision Language Action Model(视觉语言动作大模型)将迅速革命现有的机器人产业格局,在非具身大模型和自动驾驶大模型之后创造出一条万亿的赛道。
银河通用成立于去年6月,用10个月的时间完成四轮融资,累计融资额达到1亿美元,我们有一众明星投资人。
以上是王鹤演讲内容的完整整理。
