








智东西(公众号:zhidxcom)
作者 | GenAICon 2024
2024中国生成式AI大会于4月18-19日在北京举行,在大会第二天的主会场AI Infra专场上,阿里云高级技术专家、阿里云异构计算AI推理团队负责人李鹏以《AI基础设施的演进与挑战》为题发表演讲。
李鹏谈道,大模型的发展给计算体系结构带来了功耗墙、内存墙和通讯墙等多重挑战。其中,大模型训练层面,用户在模型装载、模型并行、通信等环节面临各种现实问题;在大模型推理层面,用户在显存、带宽、量化上面临性能瓶颈。
对于如何进一步释放云上性能?阿里云弹性计算为云上客户提供了ECS GPU DeepGPU增强工具包,帮助用户在云上高效地构建AI训练和AI推理基础设施,从而提高算力利用效率。
目前,阿里云ECS DeepGPU已经帮助众多客户实现性能的大幅提升。其中,LLM微调训练场景下性能最高可提升80%,Stable Difussion推理场景下性能最高可提升60%。
以下为李鹏的演讲实录:
今天我分享的是关于AI基础设施的演进和挑战。我讲的内容分三个部分:第一部分是关于生成式AI对云基础设施的挑战;第二部分是如何进一步压榨云上GPU资源的性能,保证训练和推理的效率达到最大化;第三部分是生成式AI场景下训练和推理的客户案例和最佳实践。
一、算力需求规模10倍递增,带来三大计算结构挑战
关于生成式AI最近的发展和行业趋势,我们看到的情况是,2023年生成式AI爆发,文生视频、文生图、文生文等场景下有很多垂类大模型或通用大模型出来。我和公司的产品团队、架构师团队与客户进行了很多技术分享和交流。
我的感受是,现在很多云上客户逐渐在拥抱生成式AI场景,开始使用大模型,比较典型的行业是电子商务、影视、内容咨询、办公软件这几大部分。
大模型发展对AI算力的需求方面,左边这张图是前几天GTC大会上黄仁勋展示的关于模型发展对算力的需求曲线图。2018年开始,从Transformer模型到现在的GPT-MoE-1.8T,其对算力的需求呈现出10倍逐渐递增的规模性增长,可以看出训练的需求非常大。
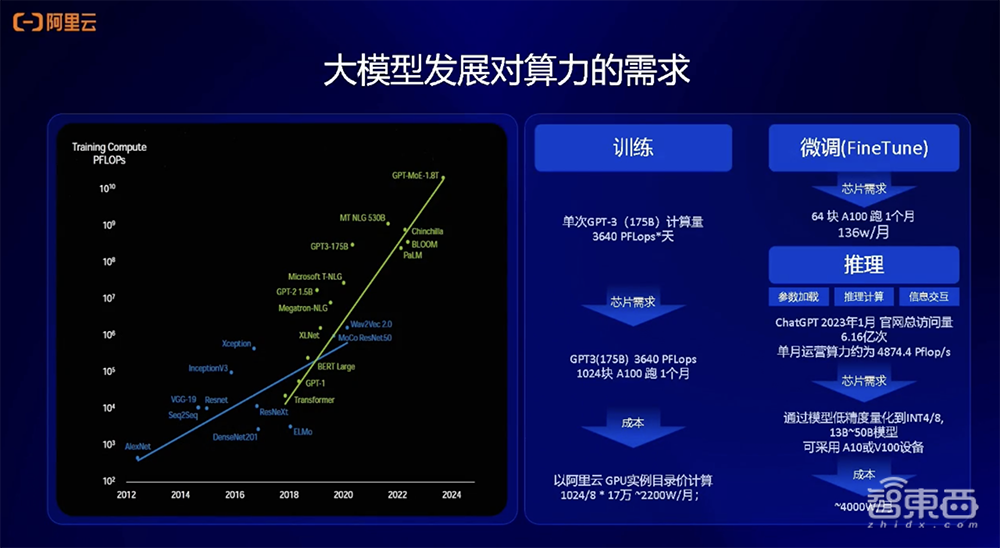
另外,我们也做了一些估算,比如训练1750亿参数的GPT-3模型,训练的计算量大概在3640PFLOP * 天,相当于需要大概1024张A100跑1个月,达到了千卡规模。换算到成本上就是一笔巨大的计算开销。总体来看,因为当前的GPU算力价格还比较昂贵,所以推理或微调本身的成本,以及计算需求和推理部署成本也会比较高。
大模型发展给计算体系结构带来挑战。
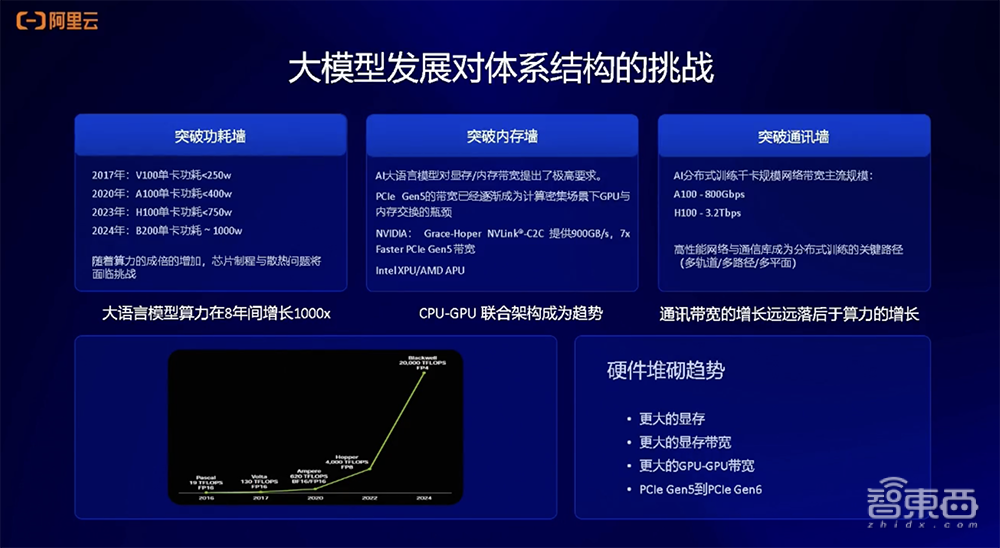
首先就是功耗墙的问题。以NVIDIA的GPU举例,V100的功耗大概只有250W,A100功耗增加到400W,H100功耗达到750W,最新的B200功耗大概为1000W。可以看到,算力8年间增长1000倍,其计算功耗也会相应增加。最近有相关的讨论提到,AI的尽头是能源,计算需求的增大会带来更大的能源需求。
第二个体系结构挑战就是内存墙。所谓内存墙,就是数据在CPU和GPU之间做搬移或者交换,现在PCIe的体系结构已经成为数据交换和传输的瓶颈。目前,NVIDIA已经在Grace Hoper架构上推出了NVLink-C2C的方案,能够大幅提升整个数据传输的速率。
第三个是通讯墙。分布式训练的规模非常大,已经从去年的千卡规模达到了现在的万卡甚至十万卡的规模。分布式训练场景下如何增强机器之间的互连带宽有很大的挑战。从国内外厂商的进展来看,他们会在A100上采用800Gbps互连的带宽,在H100上采用3.2Tbps带宽。
总结下来,现在的趋势就是硬件堆砌,会有更大的显存、更高的显存带宽、更高的CPU和GPU之间的互连带宽,同时PCIe本身也会向下迭代。
以NVIDIA的GPU为例,可以看到从Ampere这一代架构到Blackwell架构的变化。算力计算规模会越来越高,从不到1P增长到1P以上;显存规格越来越高,从80GB增加到100多GB规模;显存带宽不断增加。这反映了未来AI计算上硬件规格的变化趋势。
二、大模型训练的现实难题:模型装载、并行、互连
第二部分是大模型训练对于云上技术的挑战。
大模型训练技术栈包含Transformer模型结构、海量数据级、梯度寻优算法,这三块构成了AI训练的软件和算法。硬件就是GPU计算卡,从单卡扩展到单机8卡的服务器,再扩展到千卡、万卡互连规模的更大服务器集群,构成整个大模型训练硬件的计算资源。
大模型训练中遇到的典型现实问题是模型的加载和模型的并行。
以175B参数的GPT-3模型为例,其训练需要的显存规模大概为2800GB。我们可以根据A100 80GB来计算所需卡的数量。但是要解决的问题,一是我们需要多少张卡装载模型?二是装载这个模型之后如何提升训练效率?解决这个问题就需要用到模型并行技术,现在已经有各种各样的模型并行技术去解决这样的问题。三是互连的问题,有NVLink单机内部互连、机器跟机器之间的互连网络。对于分布式训练来说,这都是非常重要的问题,因为会在通信上产生瓶颈。
大模型训练中的模型装载过程中,175B模型以FP16精度计算,大概需要350GB显存规模,模型梯度也需要350GB,优化器需要的显存规模大概为2100GB,合并起来大概是2800GB规模。分布式训练框架目前已经有比较成熟的方案,比如NVIDIA的Megatron-LM框架、微软开发DeepSpeed ZeRO3的算法,都可以用来解决模型装载和并行的问题。
在大模型训练方式上也有比较多的并行技术,包括张量并行、流水线并行、数据并行等。
在模型分布式训练过程中,我们还看到一些比较关键的问题,如集合通信性能问题。比如在TP切分中会产生一些All-Reduce(全局归约操作),这些操作夹杂在计算流当中,会产生计算中断影响计算效率,因此会有相应的集合通信算法、优化软件被开发出来,去解决集合通信性能的问题。
三、显存、带宽、量化,成大模型推理瓶颈
大模型推理时我们需要关注三个点:一是显存,模型参数量大小决定了需要多少显存;二是带宽,大模型推理时是访存密集型计算方式,在计算当中需要频繁访问显存,所以这种情况下带宽的规格会影响推理速度;三是量化,现在很多模型发布时除了提供基础的FP16精度的模型,还会提供量化后的模型,因为低精度量化可以省下更多显存,也可以提高带宽访问速度,这也是模型推理中业界经常会采用的一种技术。
总结下来就是,大模型推理有显存瓶颈;在推理方面可以走多卡推理,训练卡也可以用在推理业务,而且会产生不错的效果。
我们在做模型微观性能分析时发现,典型的Transformer-Decoder,很多大模型都是Decoder Only结构,里面包含注意力结构和MLP层。
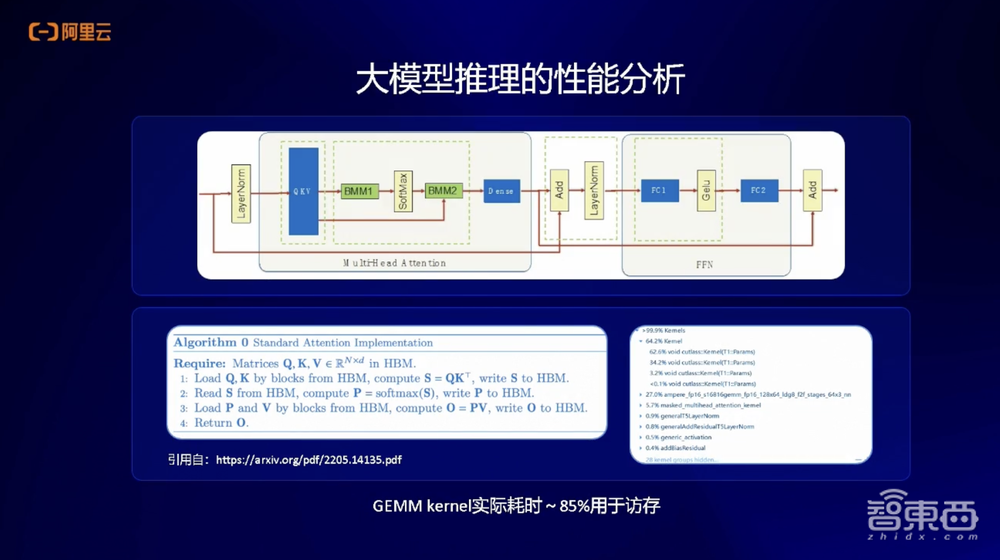
在这些算子中,我们通过微观性能分析会看到,大部分的计算都是矩阵乘操作,实际85%的耗时都是访存,进行显存读取。
由于大模型推理是自回归的生成方式,上一个生成出来的Token会被用于下一个Token的计算。这种访存方式就是我刚刚提到的访存密集型计算。基于这种行为,我们会把这些注意力结构和MLP层分别进行融合,形成更大的算子后执行推理,就会显著提高计算的效率。
在大模型推理的带宽需求方面,下图展示了Llama 7B在A10、A100上推理性能的对比。在不同的Batch Size下,A100和AI的比例关系基本是一条比较水平的线(图中红线)。
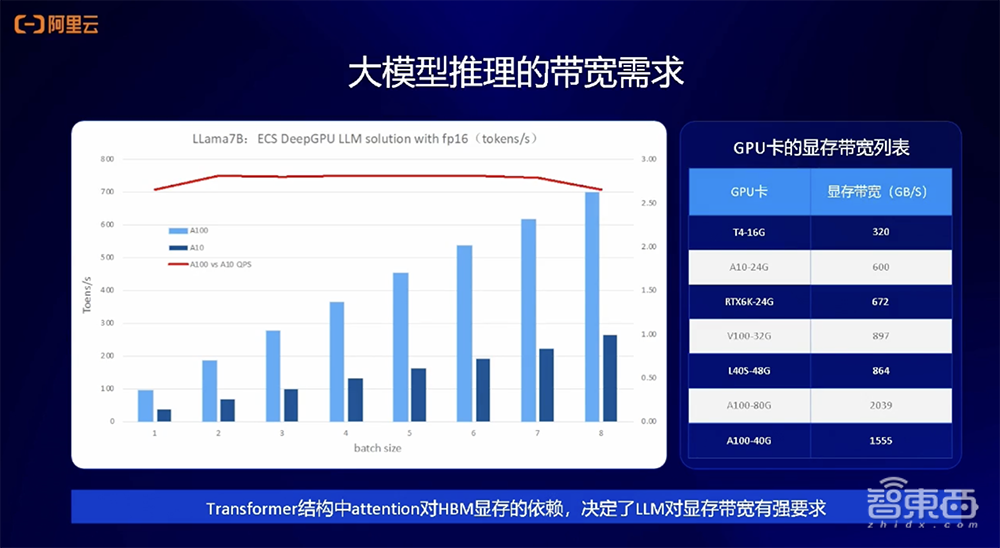
这也可以反映A100的显存带宽和A10的显存带宽之间的比例关系,从侧面印证了大模型推理基本是访存密集型的操作,它的上限由GPU的HBM显存带宽决定。
除此之外,我们还分析了大模型推理时的通信性能。这里主要说的通信性能是指单机内部的多卡推理,因为如果跑Llama 70B的模型,仅靠A10一张卡没办法装载,至少需要8张卡的规格进行装载。
因为计算时做了TP切分,实际计算是每张卡算一部分,算完之后进行All-Reduce通信操作,所以我们针对这种通信开销做了性能分析。最明显的是在推理卡A10上,通信开销占比较高,达到端到端性能开销的31%。
我们如何优化通信性能的开销?通常来说比较直观的方法是,如果有卡和卡之间的NVLink互连,性能自然会得到提升,因为NVLink互连带宽本身就比较高;另一个方法是,如果卡上没有NVLink,你就需要一些PCIe的P2P通信,这也能帮助提高通信开销占比。
基于在阿里云上的亲和性分配调优,我们摸索出了一套调优方法,能够在4卡、8卡场景下进一步优化通信开销占比。
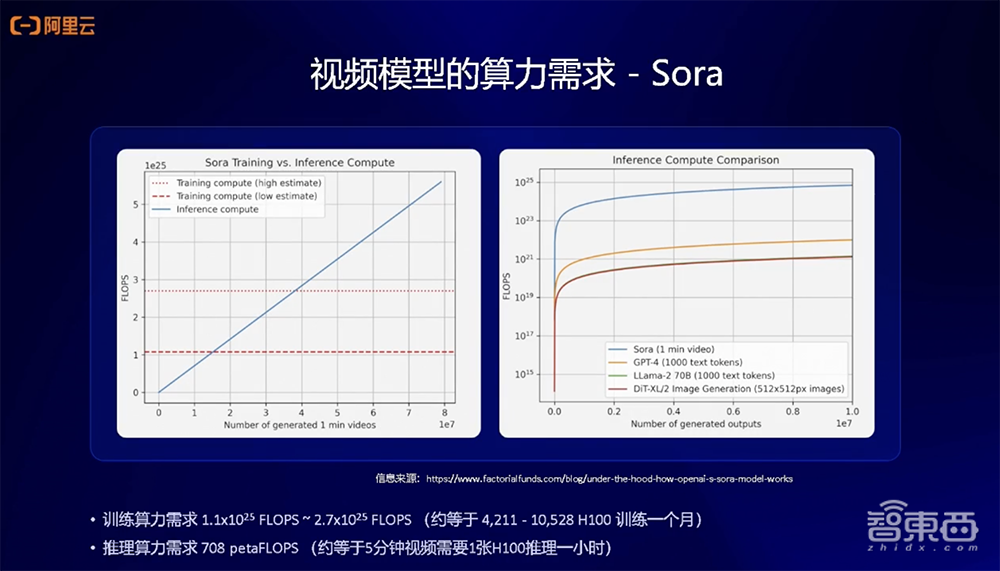
对于视频模型,今年年初OpenAI发布Sora,虽然没有公开太多技术细节,但国外机构已经给出了其关于算力需求的分析。
因为Sora的模型结构与文生图模型结构不同,其中比较显著的区别就是,从原来的UNet结构变成Diffusion Transformer结构,通过结构上的变化和算力的估算,我们看到的结果就是Sora在训练和推理上都会对算力有比较大的要求。
下图是国外研究机构估计的算力需求,他们估算训练Sora这样的模型,需要大概4000到10000多张A100训练1个月。在推理需求上,如果要像Sora这样生成5分钟长视频,大概需要1张H100算1个小时。
四、软硬协同优化方案,可将大模型微调效率提升80%
阿里云弹性计算为云上客户在AI场景提供了关于基础产品的增强工具包DeepGPU。DeepGPU是阿里云针对生成式AI场景为用户提供的软件工具和性能优化加速方案。用户在云上构建训练或者推理的AI基础设施时,该产品就能提高其使用GPU训练和推理的效率。

这非常重要,因为AI算力现阶段比较贵,我们需要通过工具包的方式帮助用户优化使用GPU的效率。我们也会提供文生图、文生文等的解决方案,并且帮助众多云上客户实现了性能的大幅提升。
接下来是阿里云帮助客户进行训练微调和推理案例。
第一个案例是文生图场景下的微调训练。我们将DPU和阿里云GPU结合,在客户的业务场景下帮助客户提升端到端微调的性能,大概会实现15%-40%提升。
第二个案例是关于大语言模型场景的微调。很多客户想做垂直领域或者垂直场景下的大模型,会有模型微调的需求。针对这种需求,我们会做相应的定制性解决方案或优化方案,在这个场景下,客户可以通过软硬结合的优化方法,提升大概10%-80%的性能。
第三个案例是关于大语言模型的推理,这个客户需要在细分场景做智能业务问答、咨询等,我们在这个场景下为客户提供了端到端的场景优化方案,从容器、环境、AI套件、DeepGPU到下层云服务器,帮助客户优化端到端推理性能,这会帮助客户提升接近5倍的端到端请求处理或推理的效率。
以上是李鹏演讲内容的完整整理。
