








智东西(公众号:zhidxcom)
作者 | 程茜
编辑 | 漠影
如今,个人大模型和企业大模型以及在其基础上发展出的个人智能体和企业智能体,将与公有大模型共存互补,以混合AI形态加速落地。
在此背景下,大模型的形态更加多元、数量增长愈发使得“算力为王”成为当下AI时代的主题,让“如何用好算力”这件事也被注入了更多新的期待。但这并不意味着“得算力者得天下”,企业更需关注的是如何驾驭海量算力,充分让算力成为支撑个人智能体和企业智能体在各种行业中应用的养料。

算力的高效利用迫在眉睫。其中,医疗领域在进行大规模数据处理、分析,需要考虑避免算力资源的浪费节省成本;从数字人助教到课程大模型等丰富应用在教育行业出现,需要让算力足够支撑这些多元应用……
同时,由于当下生成式AI的应用场景丰富,涉及的算法框架多样且需要面临不同的GPU选配、硬件搭配等,这些中间环节都为算力使用者提出了不小的挑战。未来,算力的利用率将持续攀升,产业焦点正从拼卡、拼硬件堆叠过渡到拼软件。相比于硬件堆叠,软件调度在可获得性、灵活性、可靠性等方面的优势,成为企业解决当前算力利用率提升困境行之有效的一大解决方案。
联想集团提出的AI for ALL战略,在这场混合式人工智能的竞赛中占得先机。在Q4财报发布之际,联想集团再次发布一支硬核科普视频,视频通过UE5搭建了科幻感十足的场景,模拟《沙丘》般的混合算力基建,并辅以AI生成内容等手段,对抽象技术进行了3D立体呈现。

针对企业合理分配调用现有算力的迫切需求,通过拆解算力在企业AI训练感知、调度、加速、应用的全链路流转,看到联想集团在层层交织的巨大算力网络中,如何以混合算力基础设施软件为企业抽丝剥茧,将星罗棋布的混合算力单元探索、挖掘、输送到企业的不同业务需求中。
一、 混合式AI加速落地,企业用好算力面临三大拦路虎
如今,软件已成为加速计算的根本必要条件,简单的硬件叠加部署算力已经难以追赶混合AI步伐,各行各业必须意识到从硬件堆叠向软件基础设施转变才是大势所趋。
因此,在企业现有的多元化混合算力基础设施上,亟需更优的混合算力基础设施软件释放全部混合算力资源,这在当下几乎已经成为企业大模型与业务相结合的必要条件。

但是,充分调度现有的混合算力面临三大难点。
首先是多元化应用场景与算力匹配的难题。为了满足AI愈加多元化的应用场景,企业构建的计算集群往往有上百种,不同组合的服务器、存储、网络需要不同的调度方式,同时AI领域目前至少有5种以上的算法框架和10种以上算子库,企业的适配难度极高。
第二点在于,集群的故障断点次数多,恢复成本极高。根据统计,目前业界顶尖的千卡集群,每月至少有15次断点故障。每月额外费用超过百万元,常规的断点续训技术上,每次故障恢复时间达到2个小时,使得训练效率大幅降低。
并且现在规模更大的万卡集群出现,其面临的故障中断次数及恢复时间也呈指数级增长。
第三点则在算力利用率方面,出乎意料的是,AI模型算力利用率MFU(Model FLOPs Utilization)普遍在30%左右,几乎有超过一半的算力被浪费,大量算力仍处于闲置状态,在算力供需不平衡的当下,提高算力利用率至关重要。

这些难题无疑给算力使用者、AI基础设施提供者带来了不小的挑战。但挑战背后正是历史机遇,联想集团作为算力基础设施提供者在技术积累、产品创新、应对挑战上齐头并进,为算力使用者带来了更佳的创新解决方案。正如联想集团董事长兼CEO杨元庆在联想创新科技大会Tech World上所说:“人工智能变革不是一场集成商的角逐,而是一场创新者的赛跑。”
二、拆解混合算力基础设施软件,全流程为企业释放算力资源
数据中心往往由三种集群构成,包括服务于AI的集群、通用计算集群、高性能计算集群,它们共同为企业的计算需求效力。但因调度器不同,这三种集群存在调度壁垒——使得企业的AI需求无法调度全部GPU资源,部分昂贵的GPU资源闲置,这在AI需求紧迫的当下已经成为企业一大桎梏。

4月18日,联想集团在2024 Tech World上最新发布了联想万全异构智算平台HIMP(Lenovo wanquan Heterogeneous Intelligence Management Platform)。面对企业算力应用困境,它能够极致压榨企业混合算力资源,让算力充分为企业AI训练所用。

视频中颇具视觉冲击力的“四棱锥”,便是联想的混合算力基础设施软件HIMP,在企业AI训练的感知、调度、加速、应用全链路过程中助力各行各业释放全部的算力。
首先要感知和调度算力,这是其合理分配算力资源的关键,也构成算力使用的基础。
针对不同计算集群间调度存在壁垒,无法将全部GPU资源为AI需求所用这一痛点,联想HIMP的一大独创性就是能跨越集群间不同网络定位拥有最优训练速度GPU的拓扑感知机制。视频中在三维空间中不断变化的网络拓扑动画,打破了不同集群间的调度壁垒,成为算力网络中的重要一环。拓扑感知机制可以使千卡集群的网络通信效率提升10%-15%。
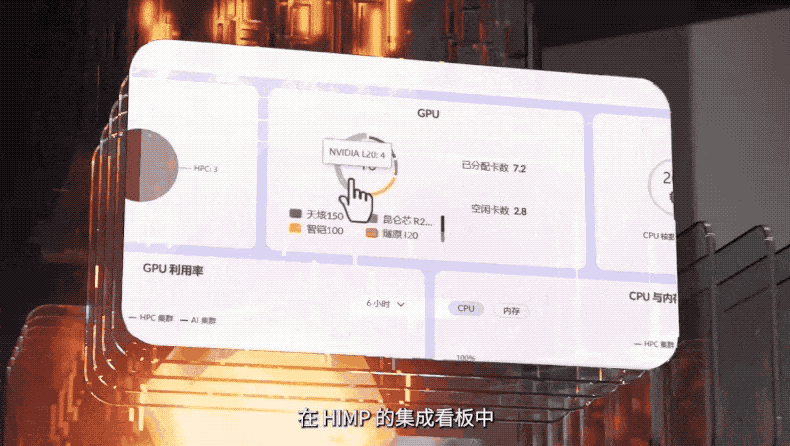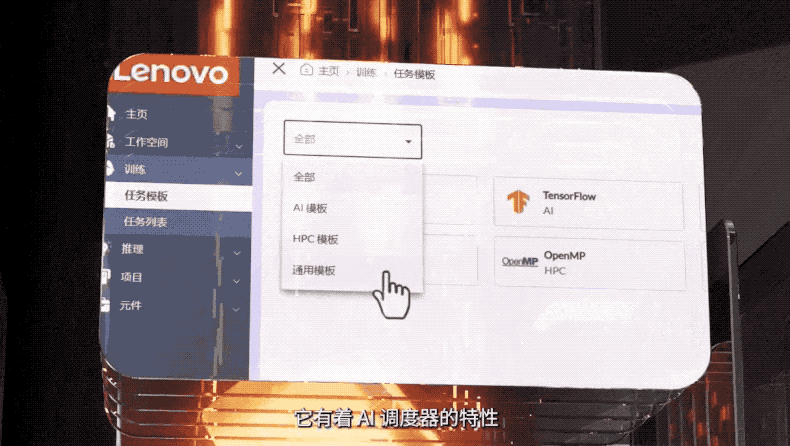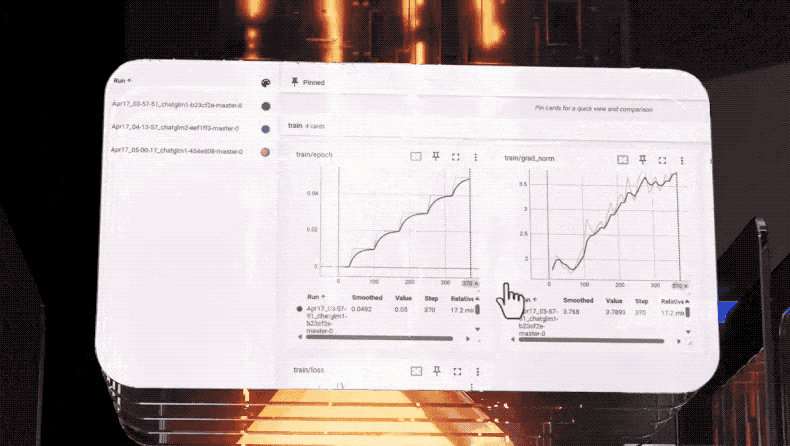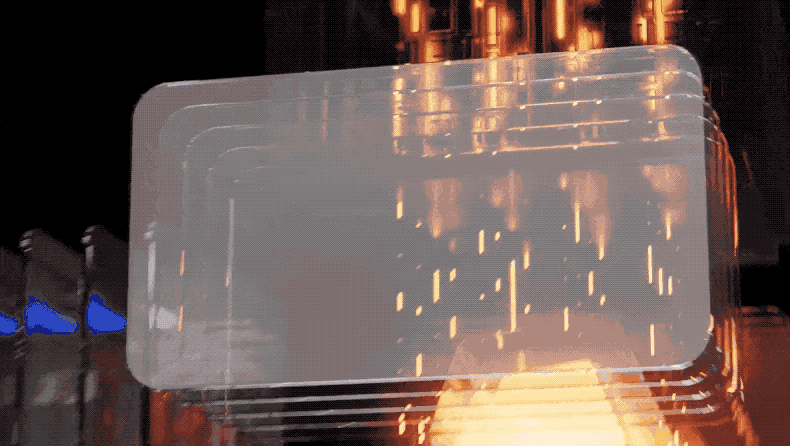
同时,联想集团打造的超级调度器,可以一举盘活AI集群、通用计算集群、高性能计算集群。通过一个面板,能够清晰看到联想HIMP可以实时感知、监测和收集算力数据以及不同业务的算力需求,通过分析相应数据进行算力的合理分配与调度,将所有GPU资源为AI所用。
合理分配之后的下一步就是如何让算力加速。
往往在企业AI训练过程中,几乎有一半的响应时间会在网络中被消耗,网络通信速度慢直接影响算力的使用效率。
联想集团以近似于“蚁群觅食行为”的集群调度算法,为AI计算提速。视频通过蚁群算法的仿生学比喻超级调度器,生动再现蚁群在复杂的环境中,驾轻就熟地找到最佳路径,减少网络中消耗的时间。

同时,为了验证大模型训练的效果,其中会夹杂部分推理任务。正如视频中从训练任务中分离而出的红色小方块,其所需的算力资源小,不需要占满整颗GPU。以往用户会在操作系统层进行GPU虚拟化的算力分配,这过程中,会产生大概20%的算力损耗。
因此,为了提升算力的使用效率,联想HIMP的另一大独创性就是GPU驱动层的内核态虚拟化技术,视频使用三维动画展示了GPU在驱动层的虚拟切割,代表推理任务的红色方块在其中极速飞梭,使GPU成为一个算力蜂巢。推理任务之间能实现任务隔离,单独任务分开计算。算力在虚拟化过程中损耗可以降到5%以下,在极致情况可以降到1%以下,几十张卡实现“千卡集群”,驱动企业的混合算力应用率提升。

最后就是应用层面,这也是算力被可持续利用起来,保证成功率的关键。
AI训练中任一节点故障都会导致整个集群停摆。联想集团创新性提出以模型之力拯救模型,通过对大量AI训练故障进行特征采样,构建了可以预测AI训练故障的模型。
如视频中呈现的蓝色粒子向集群输送任务时,遇到故障就会迅速在旁路蓝色粒子中备份,使断点续训的恢复时间从几小时减少到一分钟,大幅提升了企业的训练效率。

联想集团的异构智算平台HIMP打通了全部的算力网络,这一全流程AI训练框架落成,使得AI模型算力利用率MFU(Model FLOPs Utilization)大幅提升。在混合AI落地的需求背景下,联想集团的混合算力基础设施软件调度加持,助力企业释放全部混合算力。
联想HIMP也成为AI 2.0时代联想集团AI基础设施战略框架的核心,大模型训练和推理的基础设施底座。
结语:极致压榨算力潜能,直面算力指数级增长
生成式AI浪潮席卷千行百业,正如这支可视化财报科普解读视频所提到的:“AI所带来的新工业革命,本身就是人类对算力这一资源的挖掘和应用”。在算力资源稀缺的背景下,作为AI基础设施的行业领军者之一,联想集团正循序渐进去极致压榨算力资源推动AI基础设施释放最大动能,让企业充分利用好海量算力,与搭载个人大模型的AI PC一起助力混合AI时代加速到来。

过去20多年,PC互联网和移动互联网引领了互联网产业革命,并带动了相应的基础设施产业繁荣,如今AI有望应用于千行百业,放眼未来10年,对于AI技术的强大需求将催生一个指数级增长的算力市场,基础设施巨头联想集团正立于潮头,成为守在风口的先行者。
