








智东西(公众号:zhidxcom)
作者 | 香草
编辑 | 李水青
智东西6月3日报道,近日,AI技术公司彩云科技发布了全新通用模型结构DCFormer,通过改进注意力矩阵,在相同训练数据下,最高可以将算力智能转化率提升至Transformer的2倍。
具体来说,DCFormer改变了向量矩阵的推理通路,将Transformer结构中绑定的矩阵改进为任意线性组合,可以用2组原来的注意力矩阵组合出4种搭配,用8组注意力矩阵组合出64种搭配。
根据实验,在相同训练数据和算力下,用DCFormer架构改进后的69亿参数模型,拥有比120亿参数模型更好的效果。如果GPT-4o能够应用,其推理一次128k上下文的成本,就可能从4元变成2元。
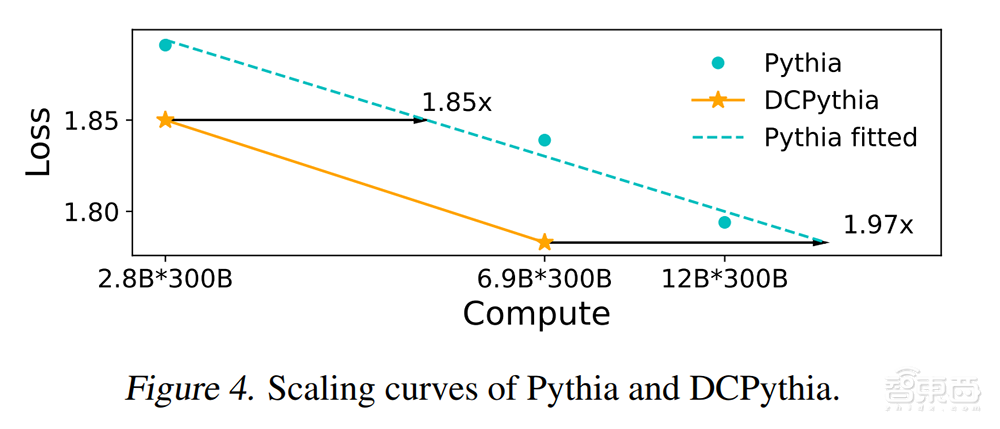
▲同一款模型在DCFormer架构改进前后的性能偏移曲线
该模型结构相关论文已于5月15日发布在arXiv,并将在第41届国际机器学习大会ICML 2024正式发表。彩云科技引用一位ICML评委的话透露,今年录用论文的平均分为4.25-6.33,而DCFormer论文获得平均7分。
DCFormer模型代码、权重和训练数据集已开源发布,相关成果后续将在彩云科技旗下彩云天气、彩云小译等产品,以及小梦V4、小梦V5等模型上应用。
在媒体沟通会上,智东西及少数媒体与彩云科技CEO袁行远进行了深入交谈。
当智东西问道,与市面上其他挑战Transformer的模型架构,如Mamba、RetNet等相比,DCFormer采取的路径有什么不同?具体有哪些差异化优势?
袁行远称,Mamba等架构对模型的改动都比较大,是没有办法在已有模型上去做改进的,需要从头重新训练模型。
相较之下,DCFormer是在Transformer的基础上进行改进,能够和现有的模型叠加,而不是互斥,因此所有基于Transformer架构的大模型都能在DCFormer的基础上降低成本
DCFormer对Transformer的改动很小,那么为什么7年间没有其他团队实现这一突破?是没有想到这个路径,还是其他原因?
袁行远告诉智东西,实际上这个路径之前也有人想到,但其大多选择在预训练之后去改进,没有达到理想的效果。为什么彩云科技做到了?袁行远用“中二”这个词来形容自己和团队,“我们相信能做到,并且坚持做了下去。”
谈及近期大模型厂商之间的“价格战”,袁行远认为,现在处于一个市场抢占的过程,大模型的价格肯定是存在一些补贴的。从电力发展的历程来看,这些资源未来都会变得越来越便宜,甚至免费,因此厂商提前去做一些补贴也不会有太大的影响。
同时,如果大模型厂商能利用DCFormer架构压缩大模型训练推理的成本,也能进一步降低自身的成本,在提供低价云服务时更具优势。
论文地址:
https://arxiv.org/abs/2405.08553
开源地址:
https://github.com/Caiyun-AI/DCFormer
一、算力智能转化率提升2倍,可将GPT-4o成本压缩一半
在传统的Transformer模型中,如果输入“上海的简称”和“中国的人口”,它们将分别被拆分成两组注意力矩阵Q1、K1、V1、O1和Q2、K2、V2、O2。
但其中,QKVO这四个矩阵是绑定的,因此要解决新问题,必须重新再来2组注意力矩阵。
比如输入新问题“上海的人口”和“中国的简称”,Transformer模型需要Q3、K3、V3、O3和Q4、K4、V4、O4这两组新矩阵来解决。
而在DCFormer中,查找通路和变换通路可以根据输入的不同而任意组合。对于上面这两个新问题,只需要搭配成Q1、K1、V2、O2和Q2、K2、V1、O1,就能在不创造新矩阵的条件下解决问题。
这就意味着,可以用2组原来的注意力矩阵组合出4种搭配,用8组注意力矩阵组合出64种搭配。
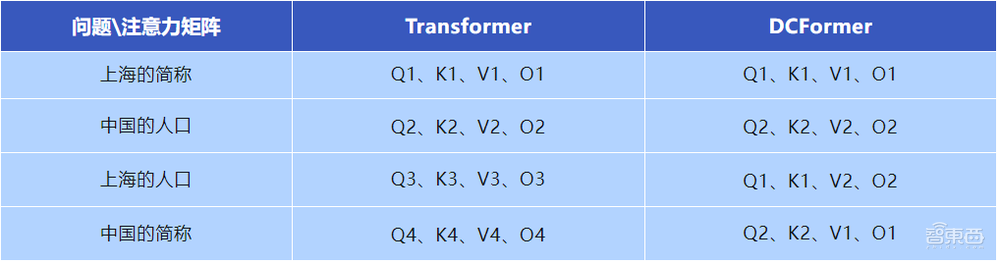
▲DCFormer与Transformer在注意力矩阵上的搭配
袁行远为我们举了个用更通俗的例子:Transformer就像一家只能点套餐的麦当劳,麦辣鸡腿堡只能搭配可乐,奥尔良烤鸡只能搭配薯条;而DCFormer就是可以任意单点的麦当劳,麦辣鸡腿堡可以搭配薯条,奥尔良烤鸡也可以搭配可乐,甚至可以只点半个麦辣鸡腿堡,组合半只奥尔良烤鸡。
反映在具体模型上,DCFormer可以达到1.7-2倍算力的Transformer模型效果,即算力智能转化率提升1.7-2倍。
袁行远称,如果GPT-4o能够用上DCFormer,推理一次128k上下文的成本,就可能从4元变成2元。此外,DCFormer模型越大效果越好,考虑到GPT模型的巨大参数量,在千亿、万亿模型上,DCFormer可能将价格压缩至一次128k上下文推理1.5元、1元。
二、打开神经网络“黑盒”,动态组合改进注意力机制
Transformer架构问世已经7年,期间虽然不乏挑战者,但能真正做到有效改进的架构并不多。无论是国内还是海外,Transformer仍是使用率最高的模型基础架构。
袁行远认为,如果底层模型没有突破,AI终将停滞不前,“人人都说神经网络是个黑盒,我们需要勇气和耐心打开这个黑盒,通过分析模型运转原理,我们才能知道智能的本质规律,从而可以改进模型,提高模型的运行效率。”
为了改进Transformer,彩云科技团队提出了一种动态可组合多头注意力机制(DCMHA),通过动态组合注意力头来提高Transformer的表达能力。
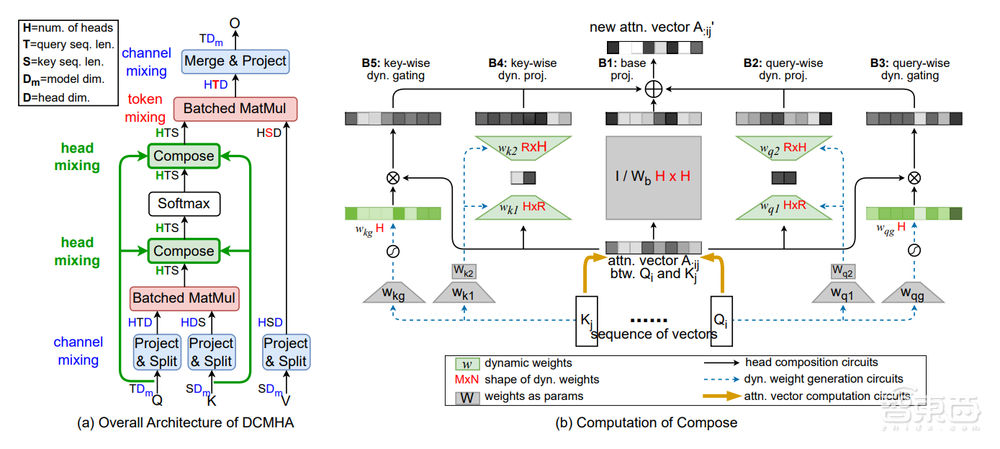
▲DCFormer整体架构及计算合成
论文提到,该机制的核心是一个可学习的Compose函数,能够根据输入数据变换注意力分数和权重矩阵,这种动态性增加了模型的表达能力,同时保持参数和计算的效率。
将DCMHA应用于Transformer架构中,就得到DCFormer模型。实验结果表明,DCFormer在不同架构和模型规模上的语言建模任务上显著优于原始的Transformer,甚至在计算量减少的情况下也能达到相似的性能。
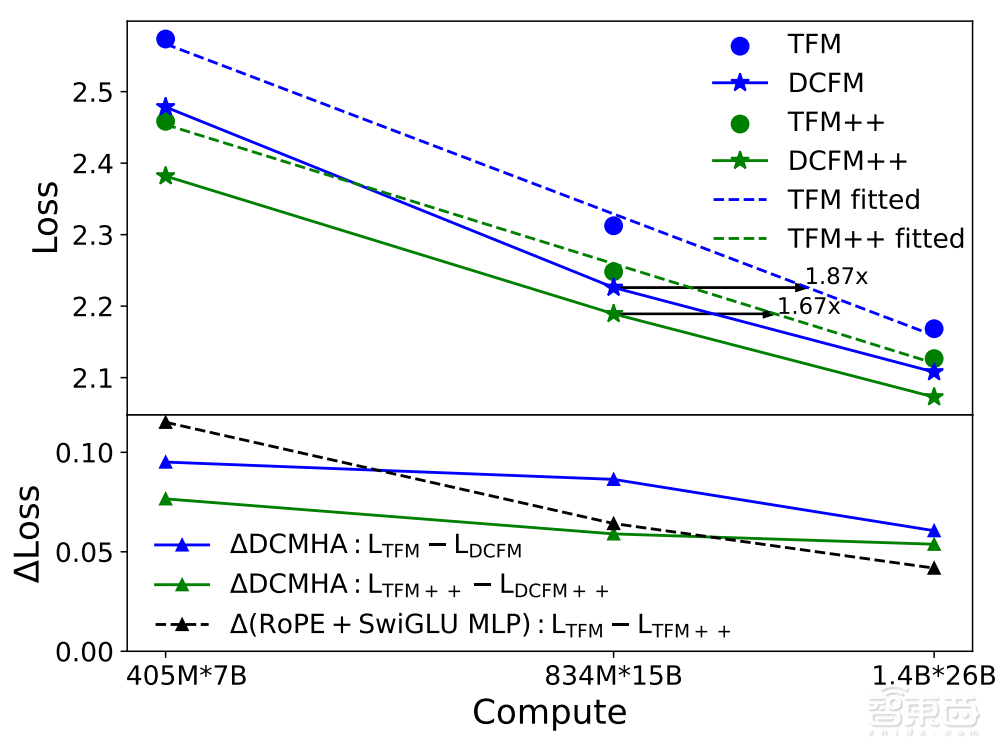
▲Transformer和DCFormers的Scaling曲线
在众多NLP下游任务和图像识别任务上的测评也验证了DCFormer的有效性。根据实验,DCFormer对性能算力比的提升幅度,超过被广泛采用的两项结构改进架构Transformer++的提升幅度之和。
随着模型规模的增大,DCFormer的提升越来越大,而Transformer++的提升越来越小。可以说,DCFormer让Transformer的能力又跃上一个新台阶。
三、将用于天气、翻译、写作产品,以1/10价格提供10倍效率
谈到未来的发展战略,袁行远分享道,首先是在2倍效率提升的基础上继续提升优化效率,目标是以目前1/10的价格,提供10倍以上的智能能力。
其次,DCFormer将应用于彩云科技目前的三款应用产品矩阵中,包括彩云天气、彩云小译、彩云小梦。
彩云天气是一款分钟级高精度天气预报应用,其基于三维时空卷积神经网络技术,每天为公众和开发者提供超过15亿次天气预报服务。据介绍,彩云天气目前累计用户数超5000万,每日服务上百万用户。

▲彩云天气的实时天气预测
袁行远谈道,基于DCFormer带来的模型效率的提升,彩云天气有望在未来将分钟级的高准确率预测时长,从2小时扩展到3-12小时。
彩云小译是一款中英同传应用,基于残差长短期记忆网络提供服务,目前月活超100万,每天翻译量达到10亿字。
袁行远向我们分享了一个有趣的数据:在彩云小译的翻译服务中,有80%的流量都用于小说翻译。他认为,虽然这看起来是娱乐用途,但小说本质上是对世界的模拟。
彩云小梦是一款AI RPG(角色扮演游戏)平台,基于相对位置编码与人设编码的Transformer能力,有超过1500万用户创作的虚拟角色,国内版日产4亿字。
目前,彩云小梦基于V2、V3模型,在保持逻辑通顺与描写细致的前提下单次可以创作几百字到一千字的内容。袁行远称,在DCFormer的加持下,下一代V4、V5版本有希望扩展到2-5千字的创作;再通过故事工程优化,目标是一年内可以轻松创作出达到专业作家水平的5万字长度中篇故事,同时小梦角色扮演的故事体验也能达到专业编剧的水平。
结语:大模型算力智能转化率现新里程碑
DCFormer的推出,让大模型在提升效率和降低成本方面迈出重要一步。其模型代码、权重和训练数据集已全面开源,期待计算机科学界和产业界能在DCFormer的基础上,带来更多研究与应用上的精彩演绎。
