








「智猩猩AI新青年讲座」由智猩猩出品,致力于邀请青年学者,主讲他们在生成式AI、LLM、AI Agent、CV等人工智能领域的最新重要研究成果。
AI新青年是加速人工智能前沿研究的新生力量。AI新青年的视频讲解和直播答疑,将可以帮助大家增进对人工智能前沿研究的理解,相应领域的专业知识也能够得以积累加深。同时,通过与AI新青年的直接交流,大家在AI学习和应用AI的过程中遇到的问题,也能够尽快解决。
「智猩猩AI新青年讲座」现已完结238讲,错过往期讲座直播的朋友,可以点击文章底部 “ 阅读原文 ” 进行回看!
近年来,文字转视频模型领域取得了令人瞩目的成就。但当前的文本驱动视频生成模型大多仍依赖于UNet作为核心网络架构,这一选择不仅制约了模型性能的提升,还难以实现大规模扩展。相比之下,Transformer架构因适合处理长序列数据和易于规模化而展现出独特的优势。
基于以上分析,莫纳什大学在读博士马鑫联合上海人工智能实验室的研究团队创新地提出了全球首个DiT类文生视频开源模型Latte,旨在视频生成领域率先探索构建稳定高效的超大型神经网络的新途径。相关论文为《Latte: Latent Diffusion Transformer for Video Generation》。

Latte将Latent Diffusion Transformer应用于视频生成任务,代替传统扩散模型中的U-Net架构,其主要包含预训练VAE网络和视频生成DiT架构。
VAE编码器将输入视频编码为潜在空间中的特征,解码器用于将特征映射回像素空间以生成视频。
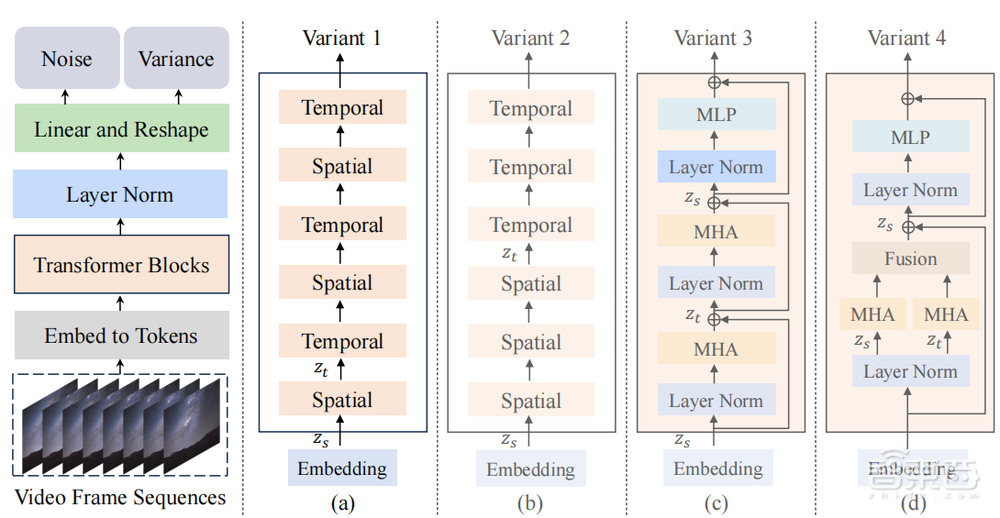
为了充分获取输入视频的时间与空间维度的信息,提出了如图所示时空交错式、时空顺序式、串联及并联式时空注意力机制四种Transformer变体探究最优处理视频输入的方式。
Latte还对视频补丁嵌入方法、条件注入模式、时空位置编码、学习策略等进行了探索与对比,来提高视频生成的质量。
6月14日10点,智猩猩邀请到论文一作、莫纳什大学在读博士马鑫参与「智猩猩AI新青年讲座」239讲,主讲《DiT架构在视频生成模型中的应用与扩展》。
讲者
马鑫
莫纳什大学在读博士
上海人工智能实验室见习研究员,研究兴趣为视频和图像生成,目前在CVPR、ICLR、Pattern Recognition等会议和期刊上发表多篇文章,所开源的代码和模型在Github上获得超过1300stars。
第239讲
主 题
DiT架构在视频生成模型中的应用与扩展
提 纲
1、视频生成的研究现状和进展
2、基于Transformer的视频扩散生成模型Latte
3、方法对比及结果展示
4、文生视频模型的任务拓展
直 播 信 息
直播时间:6月14日10:00
直播地点:智猩猩知识店铺
成果
论文标题
《Latte: Latent Diffusion Transformer for Video Generation》
论文链接
https://arxiv.org/abs/2401.03048
项目网站
https://maxin-cn.github.io/latte_project
对本次讲座感兴趣朋友,可以扫描下方二维码,添加小助手米娅进行报名。已添加过米娅的老朋友,可以给米娅私信,发送“239”即可报名。
我们会为审核通过的朋友推送直播链接。同时,本次讲座也组建了学习群,直播开始前会邀请审核通过的相关朋友入群交流。

