








芯东西(公众号:aichip001)
作者 | 李水青
编辑 | 云鹏
芯东西6月13日报道,今日,在2024上海国际嵌入式展期间,芯原AI专题技术研讨会举办。
芯原执行副总裁、IP事业部总经理戴伟进在会上透露,芯原神经网络处理器(NPU)已在全球累计出货超过1亿颗,覆盖AI视觉、AI语音、AI图像,以及AIoT/智慧家居、AR/VR、自动驾驶、PC、智能手机、机器人等多种场景。
 ▲芯原执行副总裁、IP事业部总经理戴伟进
▲芯原执行副总裁、IP事业部总经理戴伟进
与此同时,芯原图形处理器(GPU)已在全球累计出货近20亿颗;芯原视频处理器(VPU)也已经赋能智能视频处理等行业。

戴伟进谈及了大模型推进边缘计算变革的机遇与挑战,他谈道,随着大模型的爆发,我们看到在手机、AI PC、汽车等各种终端,大模型正被加速引入嵌入式系统。
今天,大模型已经运行在AI PC、医疗系统设备等众多终端。面向这些场景,芯原AI-Computing处理器技术具有可编程、可扩展、高性能、低功耗的特征。
具体来看,芯原AI-Computing IP产品体系全面覆盖数据中心、边缘服务器及端侧设备。其中,NPU IP VIP9X00是面向推断、增量训练,GPGPU IP CC8X00是通用计算,NPU+GPU IP GC9X00AI是AI-GPU/AI-PC,Tensor Core GPU IP CCTC-MP则面向大语言模型推理、训练。

芯原NPU IP研发副总裁查凯南谈道,NPU的发展近年来大概有三个方向:首先是DEEP AI,在很多嵌入式设备里面,要把AI跟其它的处理IP做比较紧耦合的绑定,可以方便做AI-ISP和AI Video;另外就是嵌入式设备和服务器中心。
 ▲芯原NPU IP研发副总裁查凯南
▲芯原NPU IP研发副总裁查凯南
端侧和云端对于NPU的要求分别是什么?
查凯南解读道,端侧更关注的是低功耗,一定要有比较好的PPA(功耗、性能和面积)。AI性能很重要,但是功耗、面积对于端侧的IP更重要。端侧主要是要做推理,也要有一些浮点运算的能力,更关注的是低比特的量化及压缩能力。
在云端,(更重要的)一定是高性能、非常高的TOPS,它要能够去做推理跟训练,而且不光是单卡的训练推理,还要做分布式的推理训练,需要多卡多机的能力。所以,云端需要的更多是通用的GPGPU的编程模型,需要比较高的浮点跟定点算力的配比,高精度是比较重要的,然后还要能够去接入到大的生态系统中去。
下图呈现了芯原NPU大概的架构,芯原NPU可以带浮点32去做大量通用运算,整个软件生态往上支持OpenCL等。
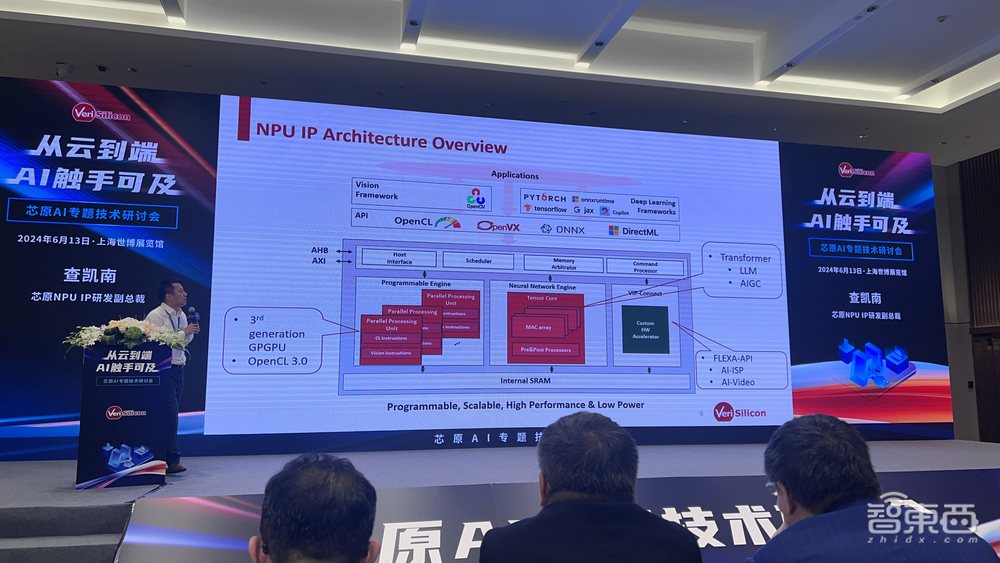
在过去两年,Transformer已经变成一个主导的模型架构。芯原的NPU架构也专门对Transformer做了定制优化,包括4bit、8bit、16×4、16×8等。芯原把权重做4bit和8bit的量化压缩,从而大大减小带宽的消耗。对于通用的矩阵运算,GEMM/GEMV,Transformer需要的大量卷积运算,以及在Transformer里有不同的Vector(向量)直接构建到里面的带宽。
据称,芯原针对Transformer相关的网络性能提升达10倍。也就是说,在一个AI PC的40-48TOPS的算力下,芯原可以做到20Tokens/s,这个性能是相当不错的。
在软件方面,不管是端侧还是云侧,芯原都采用通用的软件栈。
应用层框架支持PyTorch、Transformer,专门针对大模型支持VLLM框架。再往下走,有通用的算子加速库及运算图加速库、多核间通讯库,底层支持有标准的OpenCL、OpenVX等。

整个芯原的推理工具链,是芯原自研的,可以通过工具链直接导入所有类型框架;内部自嵌一些量化的功能,可以去直接生成一个非常易于部署的Generate Binary(生成二进制)。工具链可以支持微软的ONNX Runtime,今年10月还会接入OpenAI的Triton。
基于丰富的流片跟量产经验,芯原还推出了一站式定制芯片服务平台。
芯原高级副总裁、定制芯片平台事业部总经理汪志伟谈道,芯原有丰富的IP储备,有六大类处理器IP:神经网络NPU、图形GPU、视频VPU、音频/语音DSP、图象信号ISP、显示处理IP,所有的这些处理器的IP都被用到了设计AIGC相关的芯片中去。除此之外,芯原还有1500多颗数模混合IP和射频IP。
 ▲芯原高级副总裁、定制芯片平台事业部总经理汪志伟
▲芯原高级副总裁、定制芯片平台事业部总经理汪志伟
“我们每年都要帮客户设计30颗以上的芯片,全球首批7nm EUV芯片在2018年就一次流片成功,已经有多颗5nm芯片成功量产跟流片。我们在各种先进工艺节点有着丰富的流片与量产经验,从28nm-5nm,有大量的流片与量产的经验。”汪志伟说。据悉,芯原SiPaaS(芯片设计平台即服务)系统级芯片设计平台已经迭代多年,一次流片成功率能够达到90%以上。
结语:大模型推进边缘计算变革
随着AI技术的快速发展与应用,大模型的部署已从云端训练,逐渐向边缘端推理和微调延伸,这一转变预示着边缘计算领域将迎来前所未有的机遇与挑战。
为了让大模型平滑顺利地进入嵌入式系统,芯原已经做了深入研究和布局。一方面,芯原的系列IP在手机、汽车等领域已经帮助客户部署了一些模型的应用,同时其AI-Computing软硬件技术也取得了新的进展,有望在AGI浪潮中引领新的计算变革。
