








智猩猩机器人新青年讲座由AI与硬科技知识分享社区「智猩猩」全新企划,致力于邀请全球知名高校、顶尖研究机构以及优秀企业的青年学者,主讲在具身智能、强化学习、多智能体系统、建模仿真等机器人关键前沿技术上的研究成果和开发实践。
具身智能的发展离不开对物理世界的理解与交互,这些理解与交互受限于三维数据的获取,尤其是与语义对齐的三维场景数据。这在很大程度上限制了现有模型及方法在具身智能方向上的有效性。
针对当前问题,北京通研院BIGAI通用视觉实验室研究员贾宝雄博士等研究人员提出一个百万级别的3D视觉语言数据集SceneVerse,并提出了Grounded Pre-training for Scenes (GPS)预训练框架。与SceneVerse相关成果收录于ECCV 2024上。

他们通过SceneVerse试图汇集现有大部分真实三维场景数据,并开发基于大语言模型的工具链进行有效地三维场景-语义数据生成,通过scaling来提升现有模型在三维场景理解方向上的效果。

然而,想要完成可泛化的具身智能体训练,尤其是涉及与场景的真实交互,需要大量的真实数据。但真实扫描数据很难被放入模拟器中,因此在数据量和质量上很难满足要求,故而还需要依赖合成数据来辅助智能体训练和学习。现有三维场景生成算法并不考虑物理合理性,因此贾宝雄等研究人员提出一种面向具身智能的场景生成算法PhyScene。与PhyScene有关的论文收录于CVPR 2024并获得Highlight。

PhyScene基于条件扩散模型捕捉场景布局,设计了物理和互动指导机制,整合了物体碰撞、房间布局和物体可达性约束。通过引入物理和互动指导机制,能够在考虑物理合理性的情况下有效地完成场景生成工作。大量实验表明,PhyScene能够有效地利用指导函数进行物理可互动场景的合成,大大优于现有的最新场景合成方法。
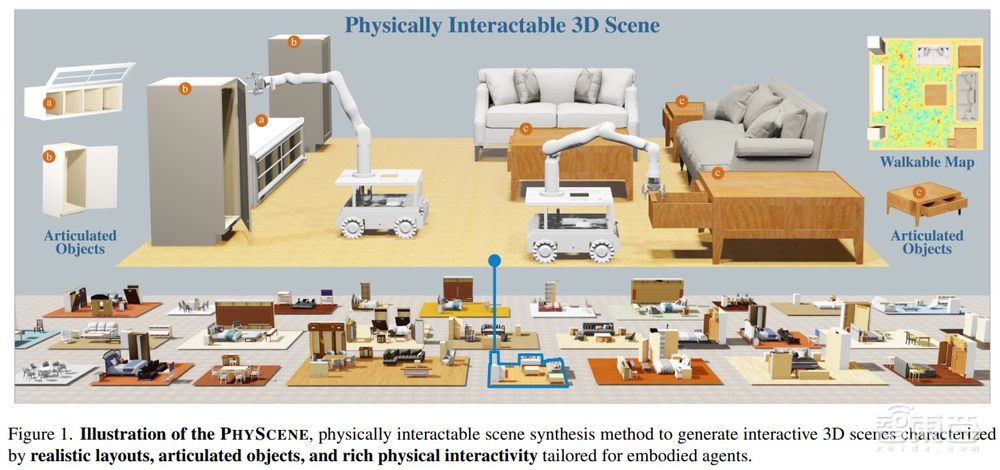
在能够有效地理解真实场景数据并能有效地生成合成数据的基础上,针对基于对场景理解能力的两个典型的下游任务,贾宝雄等研究人员又提出基于场景的人体动作生成算法AffordMotion和真实场景中的移动操作系统COME-Robot。
AffordMotion包括一个可及性扩散模型(ADM)用于预测显式的可及性图,和一个可及性到动作扩散模型,将场景信息作为条件输入生成复合场景及语言指令的动作,解决了在有限数据下生成复杂人类动作的问题。与AffordMotion相关的成果获得了CVPR 2024Highlight。

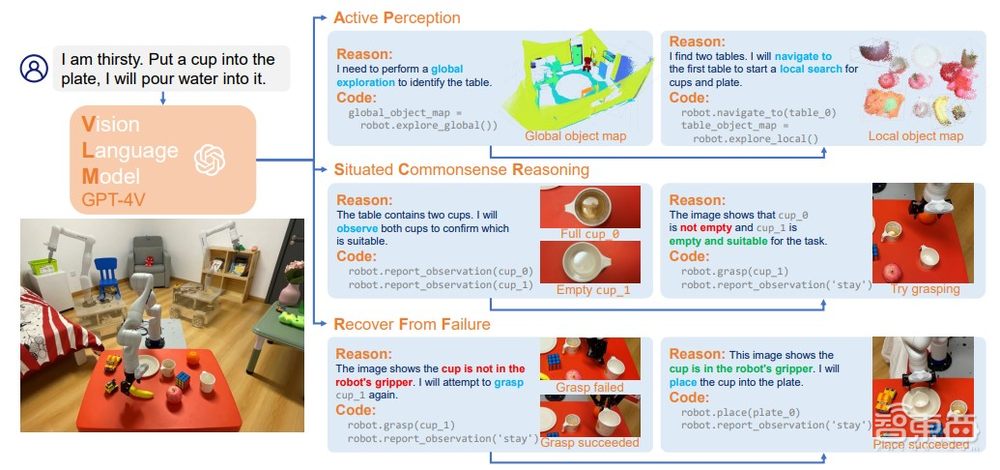
COME-robot是首个利用GPT-4V视觉-语言基础模型进行闭环反馈的移动操作系统,可以在真实场景中实现开放式推理和自适应规划。该系统的设计包括将行动作为API,将GPT-4V作为大脑,实现了机器人行动的闭环控制。与 COME-robot相关的论文目前IROS 2024在投。

COME-robot能够自行认识到执行失误或失败,在归纳原因后进行重新尝试。此外,该相关团队设计了一系列8个具有挑战性的开放词汇移动操作(OVMM)任务,在现实世界的卧室中进行了全面的实际机器人实验,展示了COME-robot在开放环境中的移动和操作任务中的优越性能。
7月5日晚7点,智猩猩邀请到贾宝雄博士参与「智猩猩机器人新青年讲座」第10讲,主讲《具身智能视角下的三维场景理解、生成与交互》。
主讲人
贾宝雄
北京通用人工智能研究院
通用视觉实验室 研究员
博士毕业于美国加州大学洛杉矶分校,期间师从朱松纯教授并曾于Amazon Alexa AI实习,研究方向包括场景理解、行为理解、具身智能等。代表工作为LEMMA,ARNOLD,LEO,SceneVerse,发表顶会论文二十余篇(CVPR,ECCV,ICCV,NeurIPS,ICLR,ICML,IROS)。曾组织多届会议研讨会、长期担任国际顶级期刊及会议审稿人,并曾获得CVPR及ICLR优秀审稿人奖。
第10讲
主 题
《具身智能视角下的三维场景理解、生成与交互》
提 纲
1、具身智能视角下的三维场景研究概述
2、用于场景理解的3D视觉-语言数据集SceneVerse
3、面向具身智能的场景生成算法PhyScene
4、基于场景理解的具身交互
4.1 基于场景的人体动作生成算法AffordMotion
4.2真实场景中的移动操作系统COME-Robot
5、总结及未来展望
直 播 信 息
直播时间:7月5日19:00
直播地点:智猩猩GenAI视频号
成果
论文标题1
《SceneVerse: Scaling 3D Vision-Language Learning for Grounded Scene Understanding》
论文链接1
https://arxiv.org/abs/2401.09340
项目地址1
https://scene-verse.github.io/
论文标题2
《PHYSCENE: Physically Interactable 3D Scene Synthesis for Embodied AI》
论文链接2
https://arxiv.org/abs/2404.09465
项目地址2
https://physcene.github.io/
论文标题3
《Move as You Say, Interact as You Can:Language-guided Human Motion Generation with Scene Affordance》
论文链接3
https://arxiv.org/abs/2403.18036
项目地址3
https://afford-motion.github.io/
论文标题4
《Closed-Loop Open-Vocabulary Mobile Manipulation with GPT-4V》
论文链接4
https://arxiv.org/abs/2404.10220
项目地址4
https://come-robot.github.io/
直播预约
本次讲座将在智猩猩GenAI视频号进行直播,欢迎预约~
入群申请
针对本次讲座,也组建了学习群。希望入群学习和交流的朋友,可以扫描下方二维码,添加小助手莓莓进行报名。已添加过莓莓的老朋友,可以给莓莓私信,发送“机器人讲座10”申请入群。

