








智东西(公众号:zhidxcom)
作者 | 程茜
编辑 | 心缘
智东西7月5日报道,昨日下午,在2024年世界人工智能大会(WAIC)上,蚂蚁集团前副总裁漆远创办的明星大模型创企无限光年发布可信光语大模型,将大语言模型与符号推理相结合,百亿参数规模的模型在垂直领域数据集上表现优于GPT-4 Turbo。
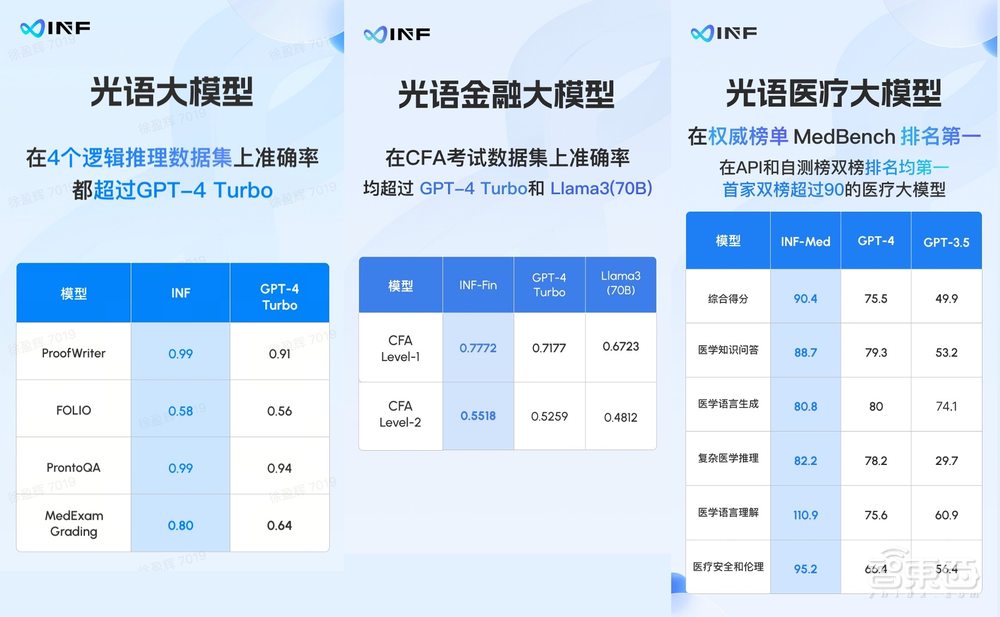
在无限光年自建的CFA考试数据集中,无限光年金融大模型在一级和二级考试中的准确率均超过了GPT-4 Turbo和Llama 3。无限光年医疗大模型在权威医疗数据集MedBench上,API和自测榜双榜第一,是首家双榜超过90分的医疗大模型,API榜综合得分90.4。
无限光年成立于2022年5月,其创始人是蚂蚁集团前副总裁漆远。2021年年底,时任蚂蚁集团副总裁漆远重返学界,任复旦大学AI创新与产业研究院院长,随后他于2022年成立无限光年。据了解,无限光年已完成多轮融资,投资人包括阿里云、启明创投等头部投资机构。

▲无限光年创始人漆远(图源:阿里云北京峰会)
在无限光年可信大模型发布之前,智东西等媒体与无限光年创始人漆远进行了深入交流,深入拆解了无限光年可信大模型背后的技术差异性,以及其在解决大模型幻觉方面的独特优势。
一、融合先验知识和海量数据,走独特“灰盒大模型”路线
漆远谈道,无限光年的技术路线就是将大语言模型和符号推理相结合。无限光年的可信大模型参数规模为百亿,在垂直领域数据集上表现优于GPT-4 Turbo。
AI在多年发展长河中形成了符号学派和联结学派两种不同的路径和理念。该公司采用神经符号技术将符号学派的推理能力与联接学派的学习能力有机结合,并落地于金融、医疗领域。
这种技术路线既可以使大模型落地应用场景时提高推理的精准性,同时可以降低服务的成本。
他解释说,将先验的知识规则和海量数据相结合,就是他本人最开始做机器学习的方向。20世纪90年代,基于规则的专家系统式微,背后的原因第一是单纯依靠死板的规则,不能在真实的场景中被灵活应用;第二是数据本身的价值很大,但这些数据需要经过处理才能实现有效的训练。
因此,将先验的知识或规则和海量数据相结合,就是无限光年的核心技术方向。无限光年的神经符号技术可以自动激活有用的规则,明确哪些规则有用,哪些数据需要受到规则的限制很重要。
正如诺贝尔经济学奖得主丹尼尔·卡尼曼提出的“人类思维有快与慢两个系统”的理论。漆远解释说,人有两个大脑,一个是神经网络式的快思考,也就是让人类无需思考即作出行动,如“见到老虎立马跑”,在执行这一任务时,大脑不需要考虑老虎的各项特征,另一个就是需要进行逻辑推理的慢思考。
符号计算与大模型的结合不仅能用神经网络实现快速的“黑盒”概率预测,更能进行慢思考的“白盒“逻辑推理。这两个系统的融合代表是通用人工智能未来的重要技术方向,也正是无限光年独特的“灰盒大模型”路线。
事实上,这在很多应用场景中可以发挥重要作用。他举了一个例子,在金融行业,大模型落地的挑战在于,如何将其嵌入工作流程,以及如何让大模型在真实场景中发挥作用,不出现幻觉。尤其在金融行业,大模型需要进行市场分析,如果结果不精准对于企业而言就是致命性的。
二、金融大模型表现超GPT-4 Turbo,已落地头部券商和三甲医院
目前,无限光年可信大模型主要的落地方向就是金融和医疗,漆远谈道,选择金融和医疗的原因是,他本人在金融科技公司工作多年对行业本身了解多,另外他认为这两个领域很重要,事关人的健康和资金。
目前在金融行业,无限光年基于特许金融分析师(CFA)考试为大模型构建了考试数据集,CFA分为三级考试,包含金融类知识问题和计算推理问题,基于该数据集,无限光年金融大模型在一级和二级考试中的准确率均超过了GPT-4 Turbo和Llama 3。
在未公开数据集FinanceIQ和Fin-Eval上,无限光年金融大模型的表现也均超过GPT-4 Turbo和Llama 3。
可信光语大模型在ProofWriter、FOLIO、ProntoQA和MedExam Grading中的得分分别为0.99、0.58、0.99和0.80,而GPT4分别为0.91、0.56、0.94和0.64。在医疗领域,无限光年医疗大模型在权威医疗数据集MedBench上,API和自测榜双榜第一,是首家双榜超过90分的医疗大模型。API榜综合得分90.4。
去年第三季度,无限光年就与头部券商合作打造了相关工具。对于券商而言,竞争焦点就是分析报告的发布速度,AI投研助手的特点就是快、精。一般人工需要2个小时,AI投研助手+人工审核的方式可以将这个时间缩短到20分钟。第二个特点是覆盖数据广且数据准,并且还会基于用户或者公司的特色生成。
无限光年的产品有个性化的分析框架、财务和非财务信息、结构化和非结构化数据的处理能力、外部报告搜索能力等。
据漆远透露,AI的加持下可以让百人投研分析师团队,从原来的分析几百家企业扩展到五千家。对于知识搜索而言,大模型的能力都很相近,这背后的关键就是做到生成内容个性化且靠谱。每个场景的细分规则也可以让用户直接输入,做到个人提供规则,构建自己的大模型。
在医疗领域,无限光年与国内头部三甲医院合作,共同基于可信技术创新打造医疗行业大模型,在体检报告解读方面有效协助医生提升了报告效率和准确度。
他也在此强调了可信大模型的含义,其指的是在技术路线上可信,就是核心技术使结果更靠谱,但并不是达到百分之百的精准。这对于大模型真正落地行业应用的意义至关重要。
三、Transformer架构缺陷导致大模型幻觉,需与图谱突破结合提高精准度
2021年底,时任蚂蚁集团副总裁的漆远离开蚂蚁,宣布就任复旦大学AI创新与产业研究院院长,当时他就在想,人生下一步怎么走。
回溯到2014年漆远刚从美国回国之际,他见证了中国互联网时代的蓬勃发展,加入阿里巴巴大展拳脚的同时构建了阿里云核心AI平台PAI。
当时,漆远就看到了大模型的发展潜力,并实现了分布式机器学习训练。2014年之际,他计划将大模型参数规模提升百倍,也就是从百万到亿级规模。但这一技术路径争议很大,漆远谈道,在那个时间点,他们需要2000台服务器、数据时间跨度翻倍,但好在阿里巴巴领导的支持下顺利推进了该项目。
这也就是现在大模型第一性原理Scaling Laws的初期验证,他看到了大模型参数规模上升后性能的显著提升。
回到当下,大模型智能的涌现很大程度上就是极大工程、算力和数据相结合推动AI 2.0热潮来临。因此,复旦大学AI创新与产业研究院在做的,一层是将AI与科研结合进行底层创新,另外一层是实现产品创新、工程落地。
不过,漆远谈道,Scaling Laws的发展也面临很大挑战,短期来看这条路线还有红利可挖,但背后暗含着大模型竞争成为红海、底层大模型研发成本居高不下、“遗忘性灾难”的挑战。其中“遗忘性灾难”指的是大模型在一个领域学的好,其他领域的能力就会慢慢下降。因此,无限光年关注的重点就是——小模型,让大模型真正在场景里发挥作用。
还有一大关键是“大模型幻觉”。大模型幻觉在艺术创作中或许能为用户提供灵感,但一旦进入金融、医疗等领域成为新质生产力,其必须保证生成内容的准确性。但大模型幻觉无法单纯依靠参数规模扩大解决,这是由Transformer本身的缺陷导致的。漆远解释说,Transformer架构通过前几个词预告下一个词,无法真正考虑到限制条件。
因此,无限光年将逻辑推理和知识结构进行了结合,以避免大模型幻觉。这一技术路径与漆远此前的项目直接相关。2020年,漆远和蚂蚁的研究人员提出对文本进行QDGAT,其结合了知识图谱与注意力机制来提升数值推理准确性。在OpenAI官网上,GPT-4与其他团队成果在数据集上的比较中,阅读理解和数据推理任务上,GPT-4落后于QDGAT。
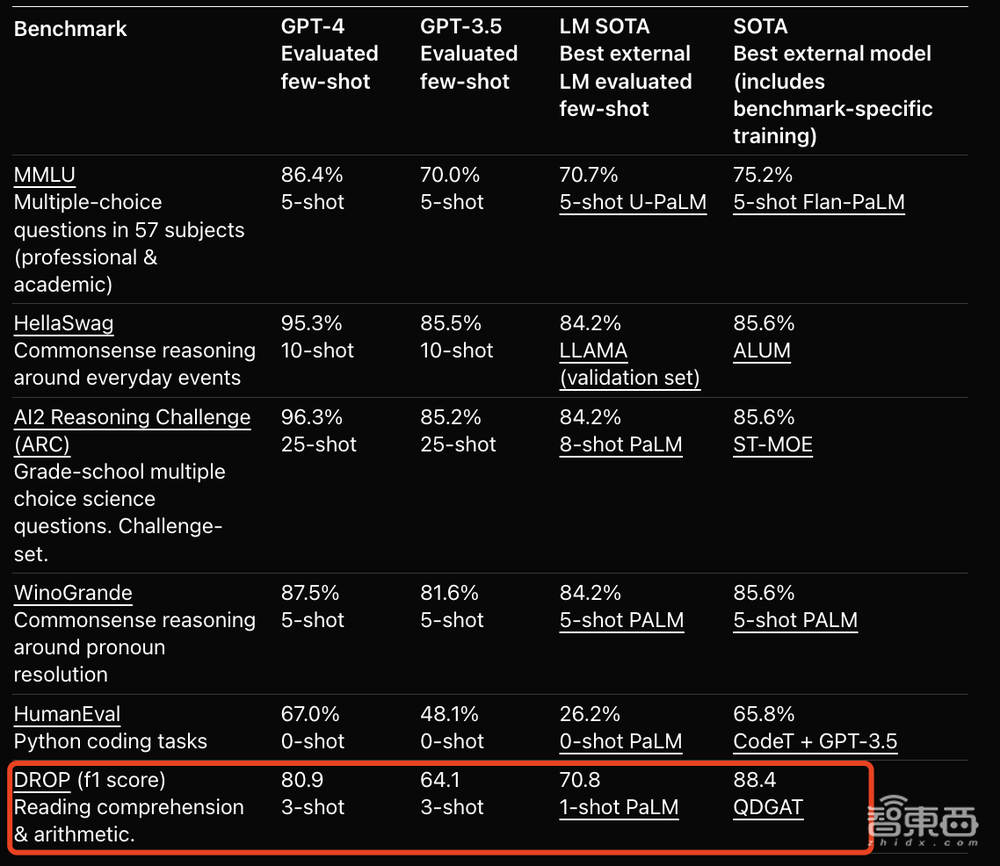
▲GPT-4与QDGAT的表现比较(图源:OpenAI官网)
这项工作就暗含了现在无限光年将Transformer架构和知识图谱结合起来的技术路线。
漆远强调说,可信大模型就是大模型作为生产力工具的核心,无限光年的技术路线一方面能大规模提升推理的精准性,另一方面可以控制成本。
走向落地,可信大模型需要吸取AI 1.0的教训,场景很关键,他谈道。在一个领域中基于垂直大模型训练出专业的金融分析师、设计师,无需让大模型在企业的生产流程中同时兼顾两个工作,在能让其在企业的需求中真正发挥作用。
结语:冲破幻觉、成本瓶颈,加速大模型商业落地
经历了百模大战,今年大模型的应用落地已经成为国内的发展重心。但当通用大模型深入企业内部时,往往会因为缺乏行业深度无法针对性解决企业的核心痛点,真正做到降本增效。同时还有大模型的幻觉问题,这也是制约其让企业接受大模型能力的关键。
无限光年提出的将先验知识和海量数据结合的创新路径,从测评结果以及应用落地案例来看,能以百亿参数规模在垂直领域表现高于更大规模的GPT-4 Turbo,为大模型商业落地的大规模铺开提供了新思路。
