








智东西(公众号:zhidxcom)
作者 | ZeR0
编辑 | 漠影
生成式AI似乎有个隐形规律:每隔一段时间,就会上演一场令人瞠目的大型“撞车”事件。
仅是今年,就有谷歌Gemini 1.5 Pro模型发布撞期OpenAI视频生成模型Sora推出、OpenAI GPT-4o发布撞期谷歌I/O开发者大会,让全球围观群众都能嗅到大模型争霸的浓浓火药味。
如果说之前种种巧合有OpenAI刻意截胡谷歌之嫌,那么上周4天内Hugging Face、OpenAI、Mistral、苹果连珠炮般相继发布自家最强轻量级模型,绝对是AI产业最新趋势的显形。
现在,AI大模型不再只竞速“做大做强”,还猛烈地卷起“做小做精”。
超越GPT-4o已经不是唯一KPI,大模型进入争夺市场的关键博弈期,要打动用户,不能只靠晒技术实力,还要力证自家模型更具性价比——同等性能下模型更小,同等参数下性能更高更省钱。
 ▲上周新发布的轻量级模型GPT-4o mini、Mistral NeMo都在性价比上非常领先(图源:Artificial Analysis)
▲上周新发布的轻量级模型GPT-4o mini、Mistral NeMo都在性价比上非常领先(图源:Artificial Analysis)
事实上,这股“大模型反卷小型化”的技术风向,在去年下半年已经开始酝酿。
游戏规则的改变者是两家公司。一家是法国AI创企Mistral AI,去年9月用70亿参数大模型击败有130亿参数的Llama 2技惊四座,在开发者社区一战成名;一家是中国AI创企面壁智能,今年2月推出更加浓缩的端侧模型MiniCPM,用仅仅24亿参数实现了超过Llama 2 13B的性能。
两家创企都在开发者社区有口皆碑,多款模型登顶开源热榜。特别是从清华大学自然语言处理实验室孵化出的面壁智能,今年其多模态模型被美国顶级高校团队“套壳”引起轩然大波,面壁的原创性工作在国内外学术圈都得到认可,令国产开源AI模型扬眉吐气。
苹果也从去年开始研究能更好适配手机的端侧模型。一直走粗放式暴力扩张路线的OpenAI,倒是个相对令人意外的新入场者。上周推出轻量级模型GPT-4o mini,意味着大模型一哥主动走下“神坛”,开始顺应业界趋势,试图用更廉价易得的模型来撬动更广泛的市场。
2024年,将是大模型“小型化”的关键之年!
 ▲2024年新发布的轻量级通用语言模型不完全统计,仅计入可在端侧部署的参数量≤8B的通用语言模型,未计入多模态模型(图源:智东西)
▲2024年新发布的轻量级通用语言模型不完全统计,仅计入可在端侧部署的参数量≤8B的通用语言模型,未计入多模态模型(图源:智东西)
一、大模型时代的“摩尔定律”:高效才能可持续
当前大模型研发正陷入一种惯性:大力出奇迹。
2020年,OpenAI的一篇论文验证了模型表现与规模存在强相关。只要吞下更多的高质量数据,训出更大体量的模型,就能收获更高的性能。

沿着这种简单但奏效的路径,近两年全球掀起一场狂飙追击更大模型的疾速竞赛。这埋下了算法霸权的隐患,只有资金和算力充裕的团队,才具备长期参与竞赛的资本。
去年OpenAI CEO萨姆·阿尔特曼曾透露,训练GPT-4的成本至少有1亿美元。在尚未探出高利润商业模式的情况下,即便是财大气粗的科技大厂,也很难承受长期不计成本的投入。生态环境更无法容忍允许这种无底洞式的烧钱游戏。
顶尖大语言模型之间的性能差距正在肉眼可见地缩小。GPT-4o虽然稳居第一,但与Claude 3 Opus、Gemini 1.5 Pro的基准测试分数之差并未断层。在一些能力上,百亿级大模型甚至能取得更出色的表现。模型大小已经不是影响性能的唯一决定性因素。
倒不是顶级大模型缺乏吸引力,实在是轻量级模型更有性价比。
下图是AI工程师Karina Ngugen今年3月底在社交平台上分享的一张AI推理成本趋势图,清晰绘制出了从2022年以来大语言模型在MMLU基准上的性能与其成本的关系:随着时间推移,语言模型获得更高的MMLU精度分数,相关成本大幅下降。新模型的准确率达到80%左右,而成本能比几年前低几个数量级。
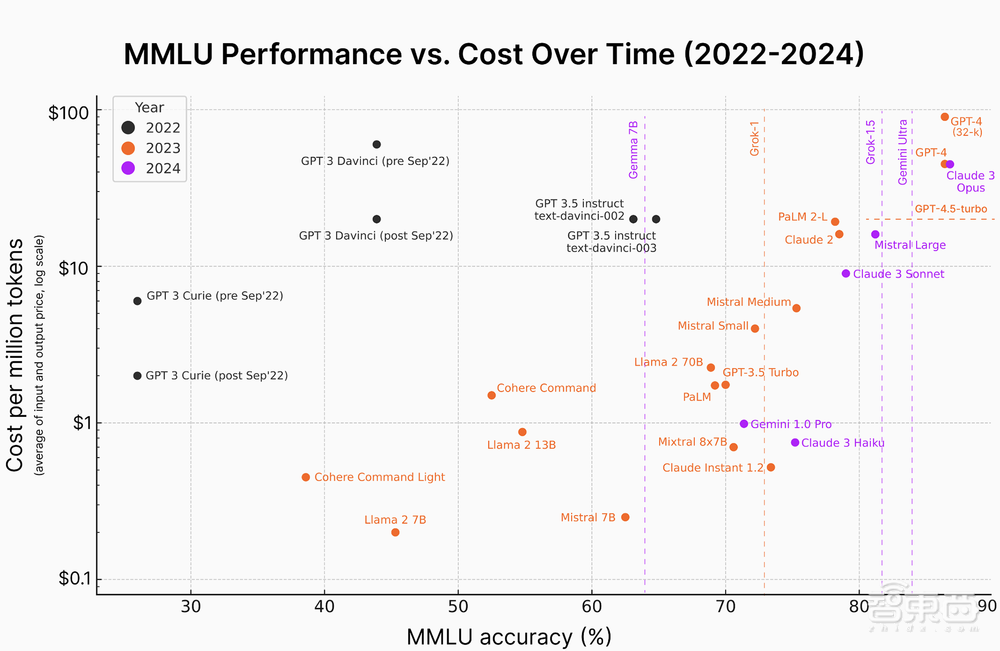
世界变化相当之快,这几个月又有一大波经济高效的轻量级模型上新。
 ▲更小尺寸的模型能以更低成本实现出色的性能(图源:Embedded AI)
▲更小尺寸的模型能以更低成本实现出色的性能(图源:Embedded AI)
“大语言模型尺寸的竞争正在加剧——倒退!”AI技术大神Andrej Karpathy打赌:“我们将看到一些非常非常小的模型‘思考’的非常好且可靠。”
模型能力÷参与计算的模型参数=知识密度,这个衡量维度可以用来代表同等参数规模的模型能具备强的智能。2020年6月发布的GPT-3大模型有1750亿个参数。今年2月, 实现同等性能的面壁智能MiniCPM-2.4B模型,参数规模已经降到24亿,相当于知识密度提高了约86倍。
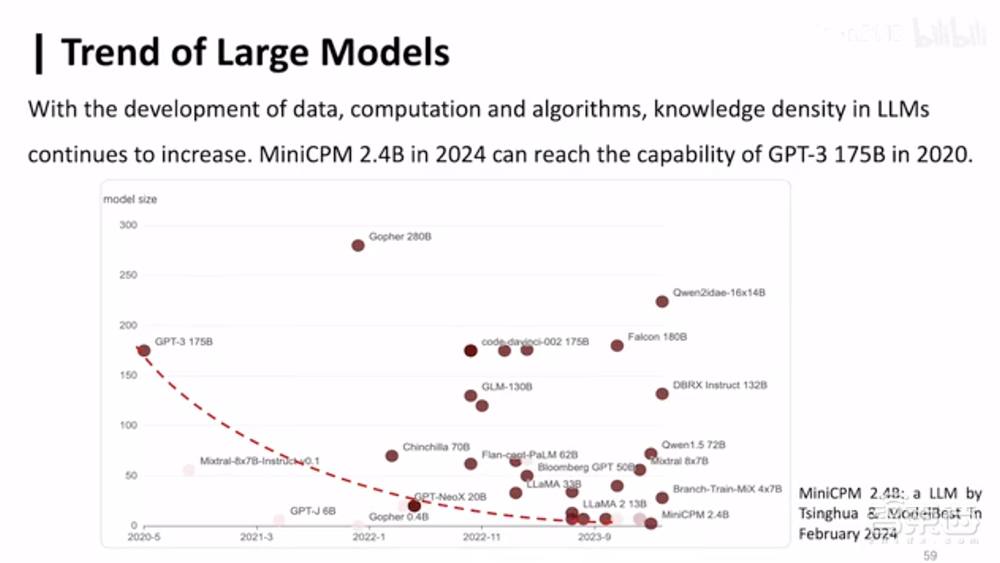
根据这些趋势,清华大学计算机系长聘副教授、面壁智能首席科学家刘知远最近提出了一个有意思的观点:大模型时代有自己的“摩尔定律”。
具体而言,随着数据-算力-算法协同发展,大模型知识密度持续增强,平均每8个月翻一番。

▲从OpenCompass榜单变化可以看到小参数、高性能模型成趋势
通过提高芯片上的电路密度,推动实现同等算力的计算设备从好几间屋子才装得下的超级计算机进化到能揣进口袋里的手机,接下来大模型的发展也会遵循类似的规律。刘知远将他提出的指导性规律命名为“面壁定律”。
以此趋势下去,训练一个千亿参数模型,它所具备的能力,8个月后500亿个参数的模型就能实现,再过8个月只需250亿个参数就能做到。
二、兵分多路:闭源价格战热火朝天,开源中美欧三足鼎立
目前进入大模型轻量化竞赛的玩家兵分多路。
OpenAI、谷歌、Anthropic都走了闭源路线。它们的GPT-4o、Claude 3.5 Sonnet、Gemini 1.5 Pro等旗舰模型把控着最强性能档,这些模型的参数规模高达千亿级乃至万亿级。
轻量级模型则是其旗舰模型的精简版。在上周OpenAI上新后,GPT-4o mini凭借超过Gemini Flash和Claude Haiku的性能,成为市场上10B以下最具性价比的选项,To C取代GPT-3.5供用户免费使用,ToB把API价格猛降一把,让采用大模型技术的门槛变得更低。
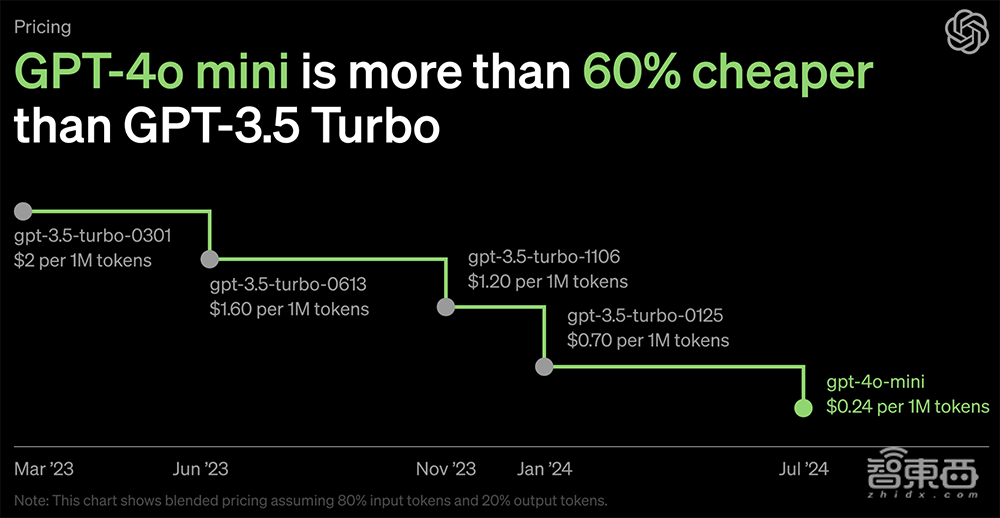
《机器学习工程》作者Andriy Burkov根据价格推断GPT-4o mini的参数规格在7B左右。面壁智能CEO李大海推测GPT-4o mini是一个专家数量较多的“宽MoE”模型,而非端侧模型,以一个高性价比云端模型的定位,来极大降低大模型落地产业成本。
开源轻量级模型的阵营则更为庞大,中美欧各有代表玩家。
国内阿里、面壁智能、商汤和上海人工智能实验室等均已开源一些轻量级模型。其中阿里Qwen系列模型是轻量级模型基准测试对比的常客,面壁智能的MiniCPM系列模型亦是用小参数越级秒掉大模型的典范,在开源社区好评度很高。
面壁智能是个前瞻性很强的创业团队,2020年在国内率先走大模型路线,很早开始探索如何用高效微调技术降低训练成本,去年年初开展对AI Agent的探索并于8月发布千亿多模态大模型,把大模型与Agent技术落地到金融、教育、政务、智能终端等场景,年末制定端云协同方向,然后今年密集推出多款高效、低能耗的端侧模型。
过去半年,面壁智能已经发布了基座模型MiniCPM 2.4B、MiniCPM 1.2B,长文本模型MiniCPM-2B-128k,多模态模型MiniCPM-V 2.0、GPT-4V性能水准的MiniCPM-Llama3-V 2.5,混合专家模型MiniCPM-MoE-8x2B等。截至目前,MiniCPM系列的整体下载量达到近95万,有1.2万个星标。
这家创企还通过高效稀疏架构实现了更高能效的MiniCPM-S 1.2B模型:知识密度达到同规模稠密模型MiniCPM 1.2B的2.57倍、Mistral-7B的12.1倍,进一步演绎“面壁定律”,推动大模型推理成本大幅降低。
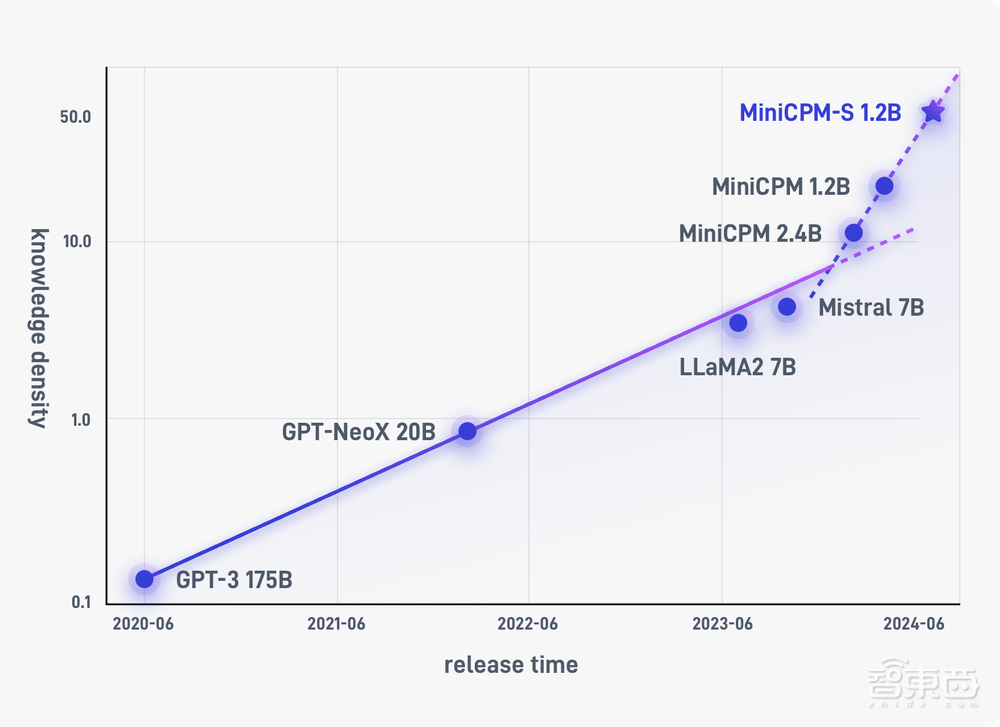 ▲面壁智能MiniCPM系列模型快速迭代并提升知识密度
▲面壁智能MiniCPM系列模型快速迭代并提升知识密度
美国轻量级开源模型阵营中,科技大厂的参与度较高,有Meta、微软、谷歌、苹果、Stability AI等,而且高频上演“后浪把前浪拍倒在沙滩上”的剧情。
Hugging Face也在上周推出135M、360M、1.7B三种参数规格的SmolLM模型,与同等尺寸模型相比性能很有竞争力,其中1.7B版本在多项基准测试的分数超过了微软Phi-1.5、谷歌MobileLLM-1.5B和阿里Qwen2-1.5B。
以“封闭”闻名的苹果,在AI领域却是知名的开源派:去年10月发布Ferret多模态模型;今年4月发布参数量从27亿到300亿的4款OpenELM预训练模型;还有最新推出的DCLM模型,其中6.9B版本性能超过Mistral 7B,1.4B版本MMLU分数超过了SmolLM-1.7B。
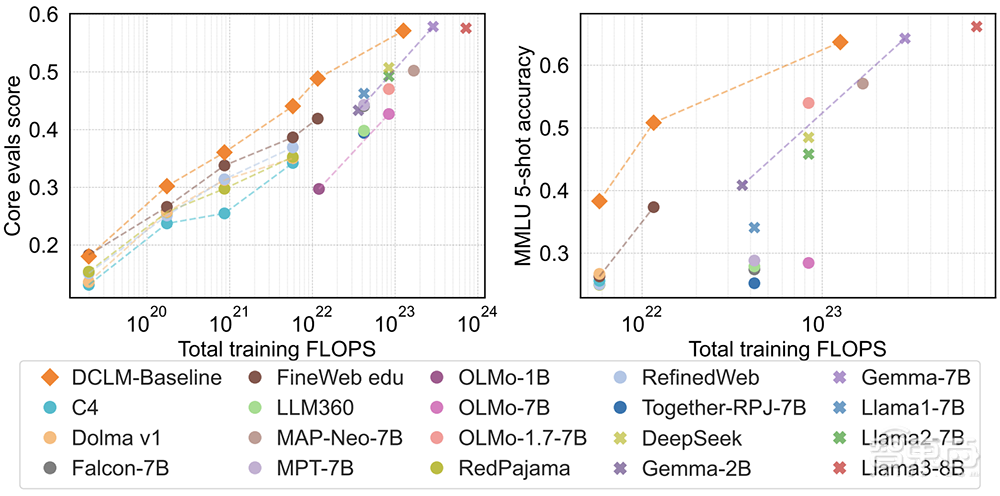
▲苹果用DCLM-Baseline训练模型(橙色),相对于闭源模型(叉)和其他开源数据集及模型(圆圈)显示出良好的性能
欧洲的代表玩家则非法国大模型独角兽Mistral AI莫属。它在上周刚发布Mistral Nemo 12B小杯模型,支持128k上下文处理,性能超过谷歌Gemma 2 9B和Llama 2 8B,推理、世界知识和代码能力都是同量级开源模型中最强的。
这些进步正展现出大模型小型化的应用潜力。
Hugging Face联合创始人兼CEO Clem Delangue预言道:“更小、更便宜、更快、更个性化的模型将覆盖99%的用例。你不需要一辆100万美元的F1方程式来每天上班,你也不需要一款银行客户聊天机器人来告诉你生活的意义!”
三、大模型界的省钱小能手,是怎么炼成的?
大模型反卷小型化,是AI普惠的必然走向。
不是所有应用都要用最强性能的大模型。商业竞争考量性价比,讲究物美价廉,不同场景、业务对输出质量与成本效益的需求迥乎不同。
超大规模的模型会给开发者带来陡峭的学习成本,从训练到部署都大费周折。更精简的模型则能够拉低投入产出比,用更少的资金、数据、硬件资源和训练周期来构建有竞争力的模型,从而降低基础设施成本,有助于提高可访问性,加快模型部署与应用落地。

▲根据苹果DataComp-LM论文,模型参数量越少,训练所需算力和时长越少
面向特定应用,轻量级模型需要的数据更少,因此能更轻松地针对特定任务进行微调,实现满足需求的性能和效率。由于架构更精简,这类模型需要的存储容量和计算能力更少,针对端侧硬件优化设计后,能够在笔记本电脑、智能手机或其它小型设备上本地运行,具备低延时、易访问、保护隐私安全等优势,确保个人数据不会外传。
轻量级高性能模型虽小,但要做到“用有限的算力、能耗,把知识浓缩到更小参数的模型中”,技术门槛不低。
其训练过程是先变大,再变小,从复杂大模型中蒸馏出知识的精华。例如谷歌的小杯多模态模型Gemma-2,就是用27B模型的知识提炼而成的。
但在具体技术路线上,不同玩家做法各不相同。
比如在训练数据方面,Meta豪气地给Llama 3喂了15T tokens训练数据。微软、苹果等则将重心放在优化训练数据集和数据方法的创新上,微软Phi-3只用了3.3T tokens,苹果DCLM 7B只用了2.6T tokens。根据苹果DataComp-LM论文,改进训练数据集能在计算和性能间取得平衡,降低训练成本。上周新发布的Mistral NeMo通过使用先进的Tekken标记器,能比以前的模型更加有效地压缩文本和代码。
“变小”还需要架构创新。比如苹果OpenELM模型面向硬件瓶颈来做模型分层精调设计,以提高在端侧的运行效率;面壁智能的MiniCPM-S 1.2B高效稀疏模型实现了近88%的稀疏度,让全链接层能耗降低至84%,解码速度相比对应的稠密模型提高2.8倍,同时不折损性能。
 ▲实现资源高效大语言模型的技术分类(图源:《Beyond Efficiency: A Systematic Survey of Resource-Efficient Large Language Models》论文)
▲实现资源高效大语言模型的技术分类(图源:《Beyond Efficiency: A Systematic Survey of Resource-Efficient Large Language Models》论文)
大模型是一项系统工程,需要探索“人工智能科学化”方向,也就是通过算法、架构、数据治理、多模态融合等技术方案的持续迭代,更可靠、更可预测、更高质量地训练模型,以不断提升大模型的知识密度。
要做到快速训练和优化模型,需要建立高效的生产线,既要构建全流程工具套件平台,又要形成高效可扩展的模型训练策略。比如面壁的模型沙盒机制通过用小模型预测大模型性能、大小模型共享超参数方案,实现模型能力快速形成。

▲MiniCPM 1.2B和MiniCPM-S 1.2B推理解码速度实测对比
为了加速大模型赋能智能终端,面壁智能最新开源了业内首个开箱即用的端侧大模型工具集 “MobileCPM “,并提供保姆式教程,帮助开发者一键集成大模型到App。

▲面壁智能端侧大模型工具集 “MobileCPM ”
恰逢今年是端侧AI爆发元年,从英特尔、英伟达、AMD、高通等芯片巨头到AI PC、智能手机大厂,都在力推丰富的端侧AI应用。终端厂商开始与通用模型厂商联手,推动轻量级模型在广泛的端侧设备中落地。
随着端侧芯片性能变强和模型知识密度的增加,端侧设备本地能运行的模型变得越来越大、越来越好。现在GPT-4V已经能在端侧运行,刘知远预测未来一年内可将GPT-3.5水平的模型放到端侧运行,未来两年内可将GPT-4o水平的模型放到端侧运行。
结语:开启不疯狂烧钱的大模型竞赛
在科技世界,变小、变便宜、变好用的历史潮流总是不断复现。大型机时代,电脑是富豪和精英才能接触到的高精尖奢侈品。进入小型机时代,技术进步把计算设备变得越来越便携好用,PC和手机才进入普罗大众的日常工作与生活。
就像我们需要有庞大算力的超级计算机,也需要普通人能塞进口袋的手机,生成式AI时代需要极致智能的大模型,也需要离用户更近、更具成本效益、能满足特定应用需求的经济型模型。
OpenAI GPT-4o仍然站在最强AI大模型的峰顶,但它不再像以前那般举世无敌,多款GPT-4级大模型已经实现了相近的性能。同时,更加紧凑、高效的大模型正在挑战“越大越好”的观念,“以小博大”的新趋势有望改变AI开发方式,为AI在企业及消费环境中的落地开辟新可能。
卷向小型化的转变,标志着AI产业的重大变革,大模型竞赛开始从专注于提升性能转向关注现实世界更细致的需求。在这股热潮之中,以面壁智能为代表的中国开源力量正在盎然生长,通过一系列技术创新,以更加经济可行的方式来验证大模型知识密度定律,最终推动大模型在实际应用场景中的落地进程。
