








「智猩猩AI新青年讲座」由智猩猩出品,致力于邀请青年学者,主讲他们在生成式AI、LLM、AI Agent、CV等人工智能领域的最新重要研究成果。
AI新青年是加速人工智能前沿研究的新生力量。AI新青年的视频讲解和直播答疑,将可以帮助大家增进对人工智能前沿研究的理解,相应领域的专业知识也能够得以积累加深。同时,通过与AI新青年的直接交流,大家在AI学习和应用AI的过程中遇到的问题,也能够尽快解决。
2022年,Stable Diffusion模型横空出世,为工业界,投资界,学术界以及竞赛界都注入了新的AI想象空间。然而文本本身具有的模糊性与歧义性,往往需要用户熟练提词技能与反复调试;而LoRA与Dreambooth为代表的逐图重训需要昂贵且缓慢的训练,即速度慢开销大。如何让大规模文-图生成模型如臂使指?急需对大规模文-图基础模型的精细控制管线与推理阶段通用知识注入机制进行研究,以降本增效,推动其在业务场景的广泛应用。
针对以上问题,上海交通大学与阿里巴巴淘天集团共同提出了图像生成模型推理阶段的知识注入方法,并基于该方法合作开发了虚拟试衣模型AnyFit,取得了目前SOTA的试衣效果。相关论文为《AnyFit: Controllable Virtual Try-on for Any Combination of Attire Across Any Scenario 》,目前NeurIPS在投。

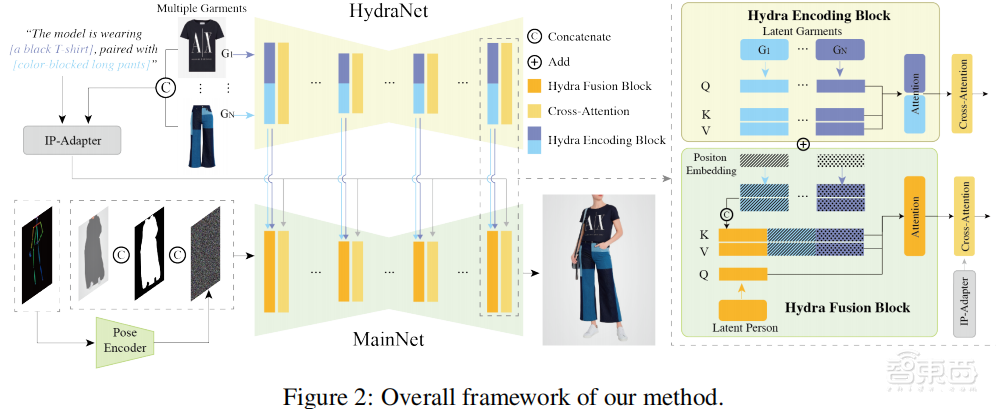
AnyFit主要由两个同构的U-Net组成:HydraNet和MainNet。其中,HydraNet负责提取细粒度的服装特征;MainNet负责生成试穿效果。
AnyFit以一个人像图像和一个或多个目标服装图像为输入。再使用OpenPose等工具从人像图像中提取出人体的轮廓部分,以便后续将服装图像融合到该轮廓上。
利用HydraNet对目标服装图像特征提取。在HydraNet中,通过共享的U-Net结构和并行化注意力模块来高效地整合不同服装的特征。
HydraNet提取的服装特征通过Hydra Fusion Block特征融合融合块注入到MainNet中。MainNet的输入包含三个组件(带噪声的图像、潜在的与服装无关的图像和调整大小的遮罩),然后通过内部的U-Net结构和Pose Guider进行处理,最终生成逼真的试穿图像。
同时,为了提升模型在生成服装图像时的强度和适应性,AnyFit采用了一种先验模型演化策略。该策略融合了三种不同且强大的模型权重,分别是:SDXL-base-1.0、SDXL-inpainting-0.1和DreamshaperXL alpha2,来演化模型的初始权重,以极低的成本提升了模型的性能。
8月20日10点,智猩猩邀请到论文一作、上海交通大学在读三年级博士生、阿里学术合作实习生李昱翰参与「智猩猩AI新青年讲座」248讲,主讲《图像生成模型的知识注入在虚拟试衣AnyFit中的应用》。
讲者
李昱翰
上海交通大学在读三年级博士生、阿里学术合作实习生
第248讲
主 题
图像生成模型的知识注入在虚拟试衣AnyFit中的应用
提 纲
1、大规模文-图基础模型的精细控制管线面临的挑战
2、条件注入控制技术的演进与前沿进展
3、基于细粒度条件注入的虚拟试衣技术开发
-服装保真性研究
-模型泛化性研究
-业务场景鲁棒性研究
4、总结与展望
直播信息
直播时间:8月20日10:00
直播地点:智猩猩GenAI视频号
成果
论文标题
《AnyFit: Controllable Virtual Try-on for Any Combination of Attire Across Any Scenario》
论文链接
https://arxiv.org/abs/2405.18172
项目网站
https://colorful-liyu.github.io/anyfit-page/
入群申请
本次讲座组建了学习交流群。加入学习交流群,除了可以观看直播,并提前拿到课件外,你还能结识更多研究人员和开发者,所提问题也将会优先解答。
希望入群的朋友可以扫描下方二维码,添加小助手米娅进行申请。已添加过米娅的老朋友,可以给米娅私信,发送“ANY248”进行申请。

