








芯东西(公众号:aichip001)
编译 | ZeR0
编辑 | 漠影
芯东西8月27日报道,一年一度的夏季芯片顶会Hot Chips 2024正在斯坦福举行,在生成式AI热潮下,果不其然AI计算全面霸场,AI辅助芯片设计、AI计算、AI芯片等成为焦点议题。
当地时间周一上午,高通、英特尔分享AI PC处理器设计,IBM公布新一代处理器和AI加速器,加拿大AI芯片创企Tenstorrent展示独立AI计算机及其编程模型,SK海力士分享AI专用计算内存解决方案。
下午更是AI芯片的专场,英伟达披露Blackwell架构细节,美国AI芯片独角兽SambaNova解读如何突破万亿级参数规模的AI计算障碍,英特尔讲解AI训练芯片Gaudi 3,AMD分享Instinct MI300X生成式AI加速器,博通展示具有光学粘接的AI计算ASIC,美国AI芯片创企FuriosaAI介绍采用创新架构的云端AI芯片RNGD。
其中,IBM和FuriosaAI都在Hot Chips大会上首发AI芯片新品。
IBM宣布推出内置AI加速器的新一代Telum II大型机处理器。Telum芯片上的AI加速引擎可以处理传统的机器学习,AI加速器Spyre则进一步实现了在大型机处理器上部署最新大语言模型。
 ▲Tellum II片上AI处理器(图源:IBM)
▲Tellum II片上AI处理器(图源:IBM)
Telum II和Spyre采用三星5nm制程工艺。Spyre具有1TB内存,每个芯片都有32个计算核心,支持八卡协同工作,每张卡功耗不超过75W。
另一个令人印象深刻的全新AI芯片是RNGD,发音为“Renegade”,专为数据中心里的高性能、高效大语言模型和多模态模型推理而设计。
 ▲Furiosa张量收缩处理器(TCP)
▲Furiosa张量收缩处理器(TCP)
RNGD是一款张量收缩处理器(TCP,Tensor Contraction Processor),是FuriosaAI打造的第二代数据中心AI芯片,定位为“英伟达GPU的替代品”。
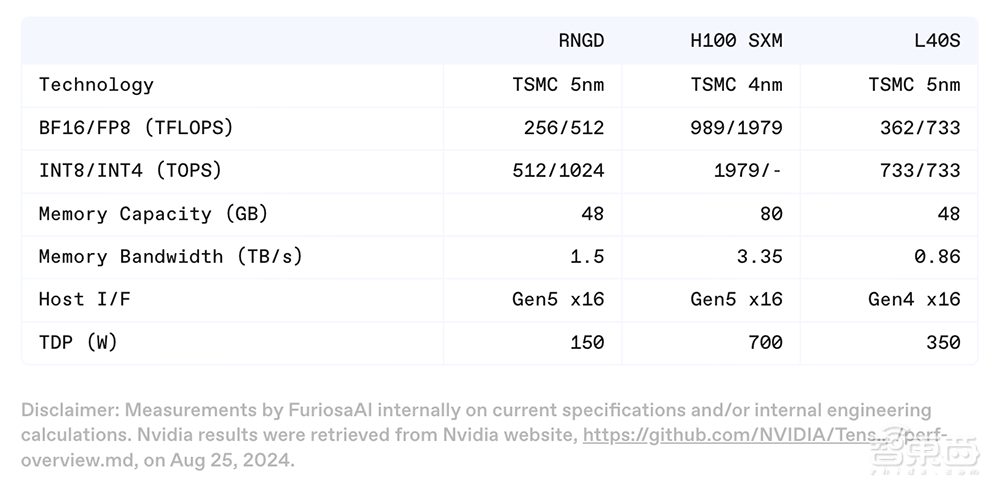
该芯片采用台积电5nm制程工艺,Die面积为653mm²,内置400亿颗晶体管,频率为1.0GHz,具有256MB片上SRAM,配备48GB HBM3、内存带宽为1.5TB/s,可在单张卡上高效运行Llama 3.1 8B等大语言模型,提供最高可达512TFLOPS(FP8)和1024TOPS(INT4)的计算能力。


其他基础规格包括支持PCIe Gen5 x16互连、被动散热解决方案,热设计功耗(TDP)仅为150W。相比之下,游戏PC中的GPU可能更耗电,目前市面上一些领先GPU的热设计功耗更是超过了1000W。
目前,该芯片正在向早期试用客户提供样品,将于今年晚些时候推出,预计2025年初广泛上市。
更多技术细节可参见TCP研究论文。该论文最近被国际计算机架构研讨会ISCA接收。

一、从设计到交付紧锣密鼓,一块芯片解决三大挑战
FuriosaAI成立于2017年,奉行专注于快速迭代和产品交付的战略。其创始人是三名硬件和软件工程师。他们曾在AMD、高通、三星等芯片巨头处工作数十年。

▲FuriosaAI联合创始人兼首席执行官June Paik
在创立早期,FuriosaAI首先先花了几年时间测试和验证其自研TCP架构背后的理念。完成这项基础工作后,这家创企于2021年与三星和华硕合作推出了第一款基于TCP架构的Vision NPU作为商业产品。
vision NPU专为计算机视觉工作负载而设计。2022年,FuriosaAI是唯一一家向行业标准MLPerf推理基准提交结果的AI芯片创企。测试结果显示,其第一代Vision NPU在视觉任务中的表现优于英伟达A2芯片。

在用第一代验证了TCP设计后,FuriosaAI设计了RNGD来运行要求更严格的AI算法。第二代芯片RNGD的研发于2022年启动,今年5月收到台积电交付的第一批硅片样品,不到一周后就启动了硬件,6月初运行Llama 3.1模型,几周后全面完成RNGD的实现,7月始向早期客户交付RNGD芯片并进行了大语言模型演示。

FuriosaAI称RNGD的一大亮点是“解决了数据中心大规模AI推理的实际问题”,是一款真正能运行Llama 3.1 70B等模型的实际产品。
如今,在生产环境中运行大语言模型和多模态模型既困难又昂贵,即使不考虑购买高性能GPU的巨额前期成本,企业还必须应对令人瞠目结舌的电费、复杂且昂贵的液体冷却系统,以及从未设计过的服务器机房基础设施。
而RNGD芯片的TDP低至150W,能轻松运行Llama 3.1,还具有可编程性,用一块芯片解决三大挑战,是一款“数据中心真正需要的芯片”。
 ▲Furiosa第二代数据中心AI芯片RNGD
▲Furiosa第二代数据中心AI芯片RNGD
在论文中,FuriosaAI团队提供了运行Llama 2 7B模型时,RNGD 与领先GPU之间的基础配置和示例性能比较。
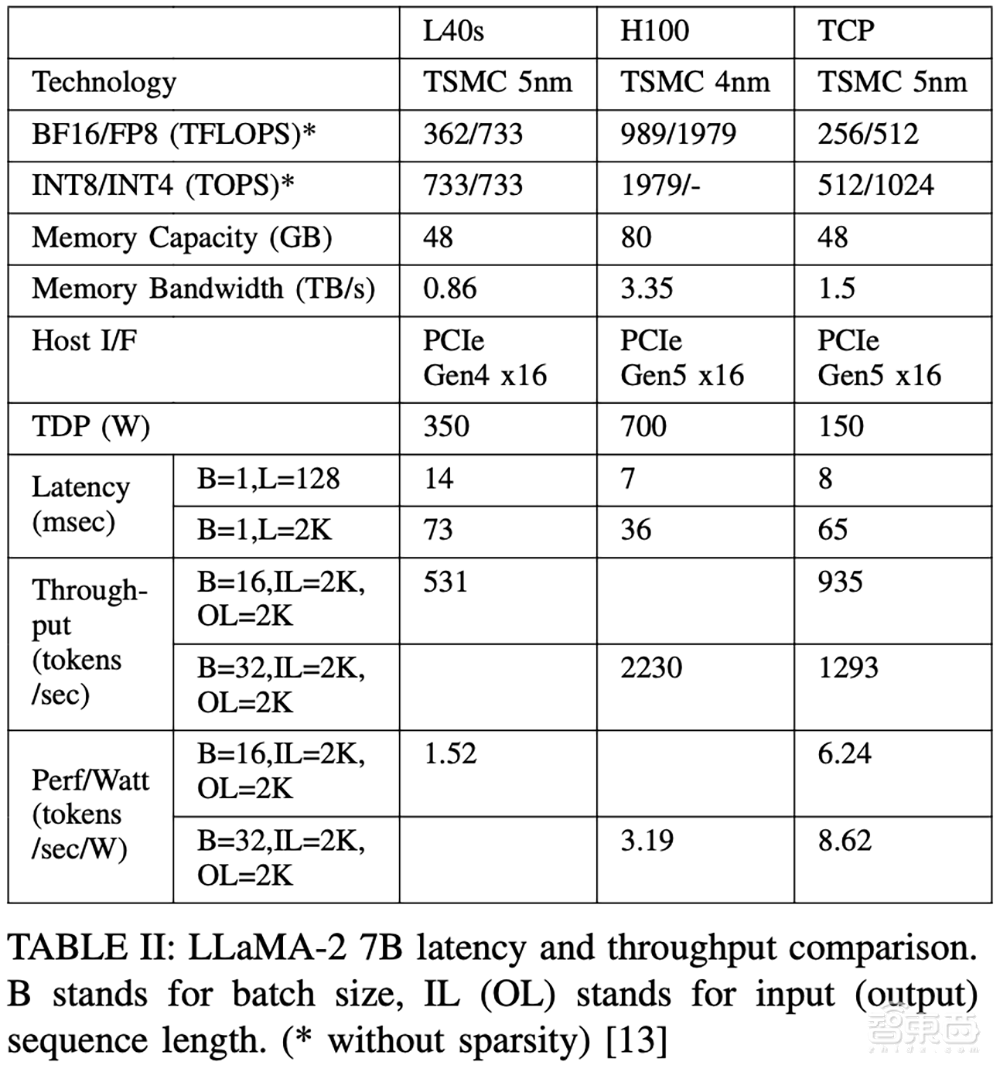
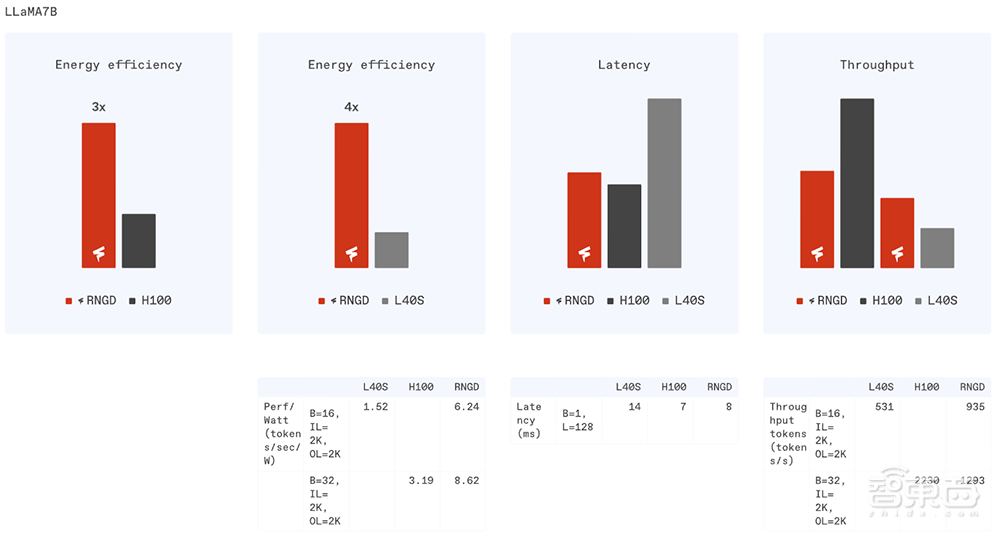
TCP的每瓦性能分别是H100和L40的2.7倍和4.1倍。
其论文说明了RNGD和GPU如何以不同的方式管理内存。在Llama 2 7B中,前馈网络的第一次计算必须存储中间激活的输出,同时加载下一层约4400万个权重。在RNGD芯片中,256MB的片上内存不仅可以存储前馈网络的所有中间张量,还可以预取下一层的权重。
GPU必须将数据从全局L2缓存或DRAM再次加载到共享内存中。但使用RNGD,前馈网络第一层的计算输出可以直接用于下一层的计算,而无需片上内存的任何移动。换句话说,RNGD仅消耗一次内存带宽来加载权重,而GPU不仅要加载权重,还要加载中间激活结果。此外,即使使用L2缓存,也需要额外的成本来全局遍历片上网络。
新的RNGD测试表明,运行Llama 3.1和GPT-J等大语言模型,RNGD可以取得显著高于H100、L40S的能效比。
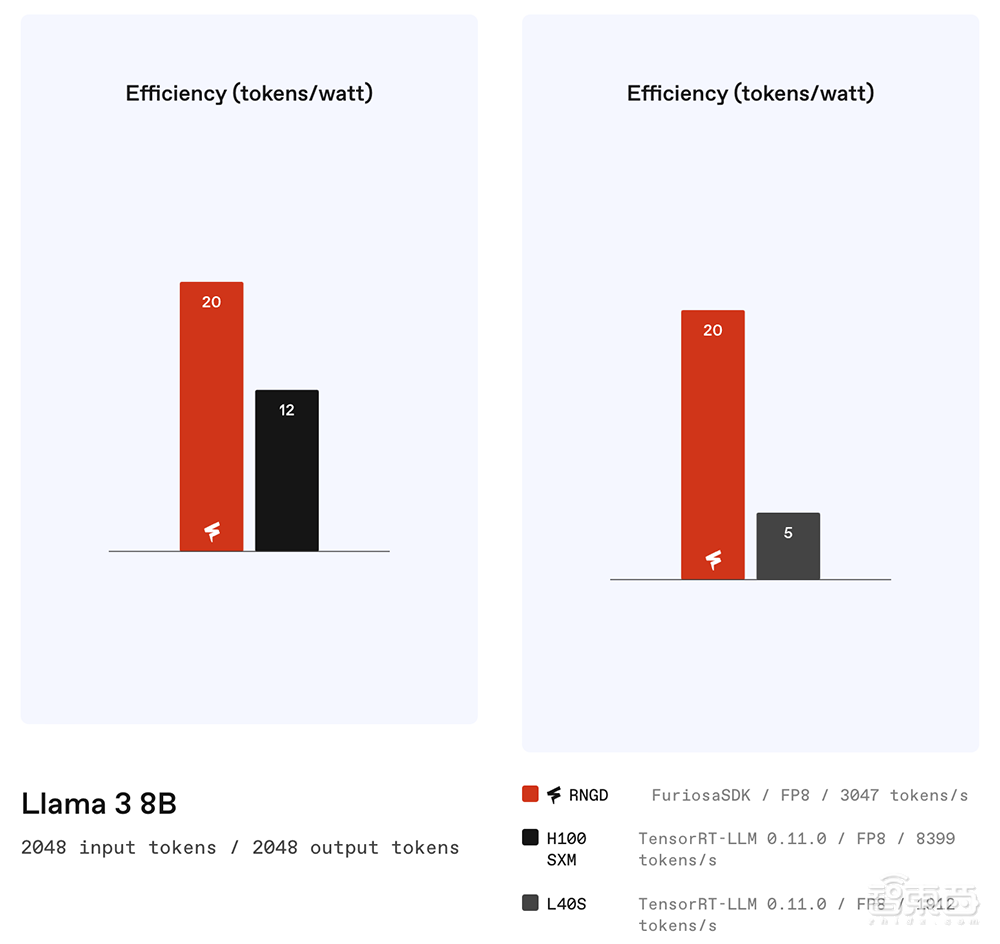
对于有约100亿个参数的模型,单张RNGD PCIe卡可提供每秒2000~3000个token的吞吐量性能,具体取决于上下文长度。
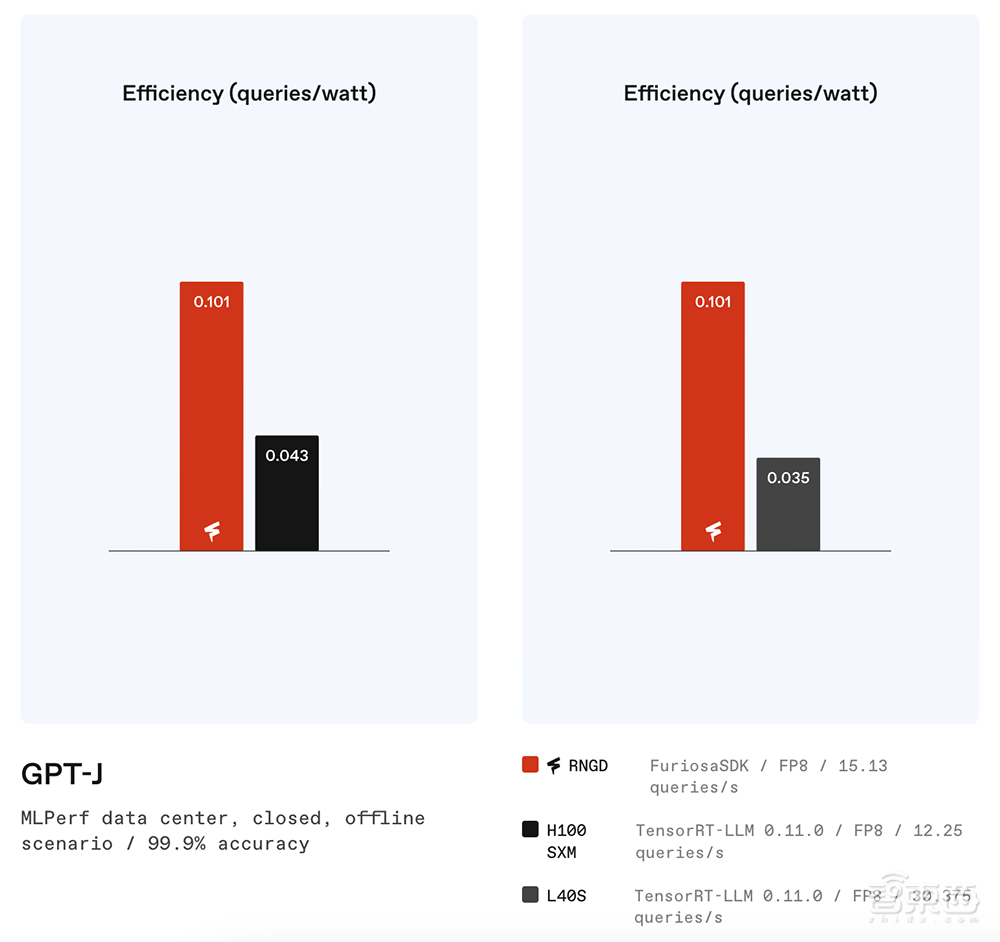
RNGD在运行OpenAI的GPT-J 6B模型时,每秒能处理大约12~15个查询。与其他AI芯片的性能、功耗对比如下:
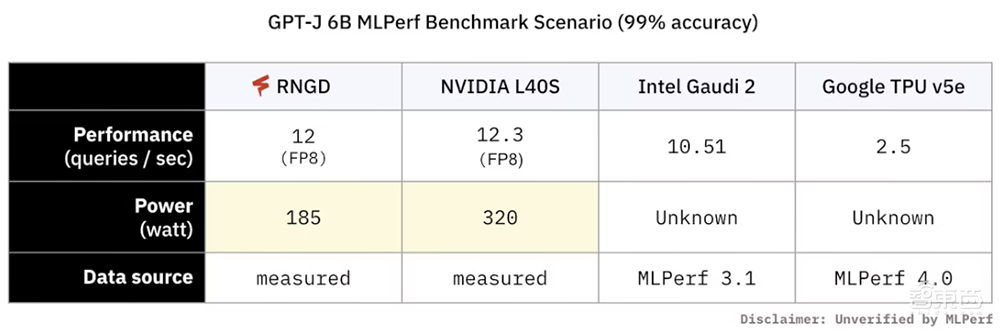
有意思的是,FuriosaAI似乎对其他同行的营销行为感到不屑,在其新闻稿及博客文章中多次拉踩同行的炒作行为,比如:
“迄今为止,Furiosa一直刻意保持低调,因为我们知道,行业不需要对尚不存在的事物进行更多的炒作和大胆的承诺。(此外,Furiosa 95%的工程师都是工程师,因此营销并不是首要考虑的问题。)”
“一些新技术产品之所以能引起轰动,是因为它们拥有出色的营销平台。或者对尚不存在的产品进行了华丽的渲染。或者从最精通媒体、收集独角兽的沙山路梦想家那里获得了数十亿美元的风投资金。那不是FuriosaAI。”
二、TCP架构:兼顾高性能、高能效、可编程性
RNGD采用创新的非矩阵乘法、张量收缩处理器(TCP)架构。FuriosaAI称这一架构“可实现能效、可编程性和性能的完美平衡”。
 ▲FuriosaAI RNGD 芯片的硬件样本
▲FuriosaAI RNGD 芯片的硬件样本
FuriosaAI首席技术官Hanjoon Kim认为,为了实现AI普惠,AI硬件除了能够并行执行多项计算之外,还必须提供两个关键功能:可编程性与能效。
可编程性能够更好适应快速发展的AI模型创新,可通过GPU实现,但通常并不容易。使用新模型获得最佳性能,往往需要手动调整内核和其他耗时的编译器优化。能效也是GPU架构的一个主要限制,每一代GPU耗电都比上一代多得多,最新硬件的每块芯片功耗超过了1000W。
为了使高性能AI计算可持续且广泛使用,FuriosaAI开发了一种新的芯片架构——张量收缩处理器(TCP)。
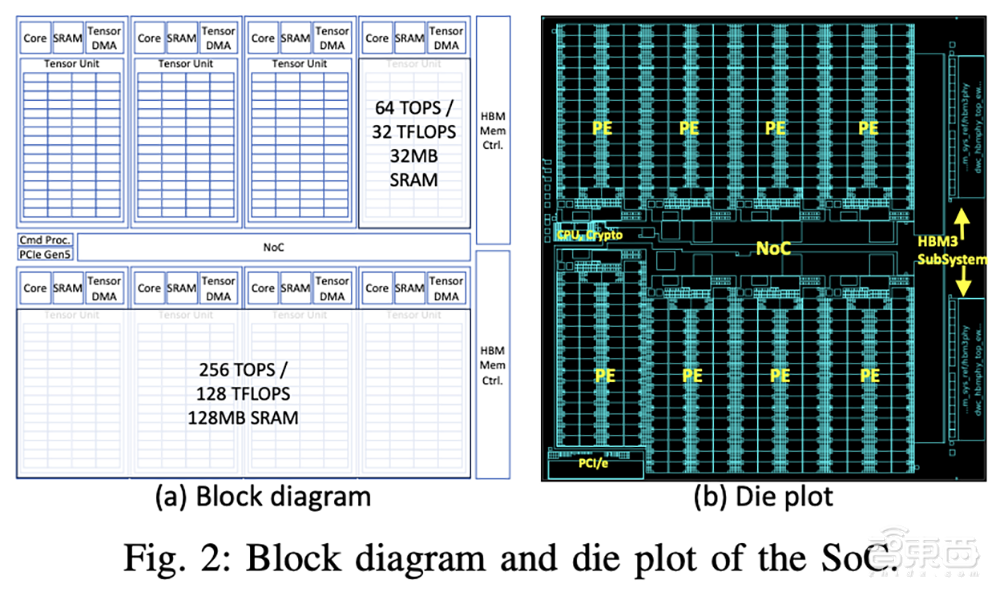
TCP架构是围绕AI的核心计算构建的,由粗粒度处理单元(PE)组成,可以比GPU更高效地管理数据和内存,提供了运行高性能生成式AI模型(如Llama 3)的计算能力,并显著提高了能效。
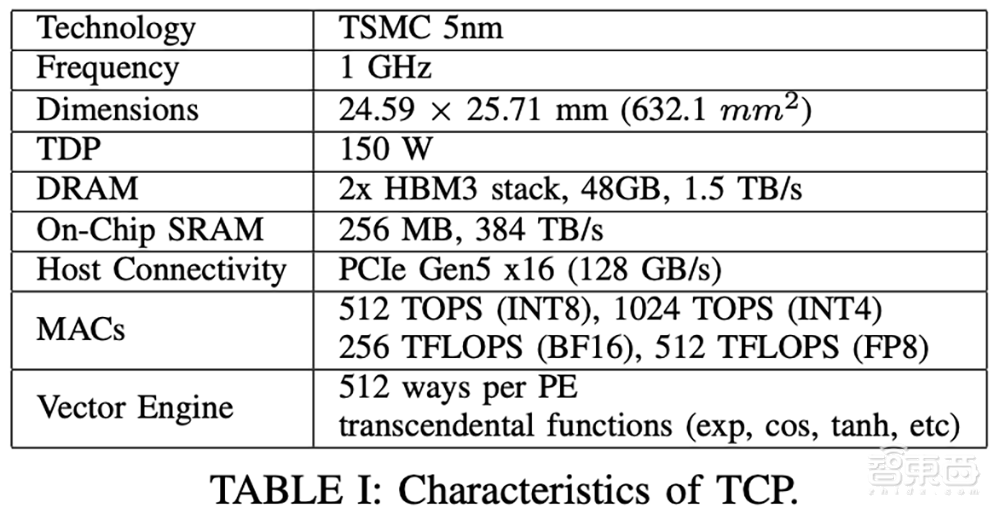
它还具有高度可编程性,由一个“强大的编译器”实现。该编译器经过联合设计,针对TCP进行了优化,可将整个AI模型视为单一融合操作,支持自动部署和优化新模型。
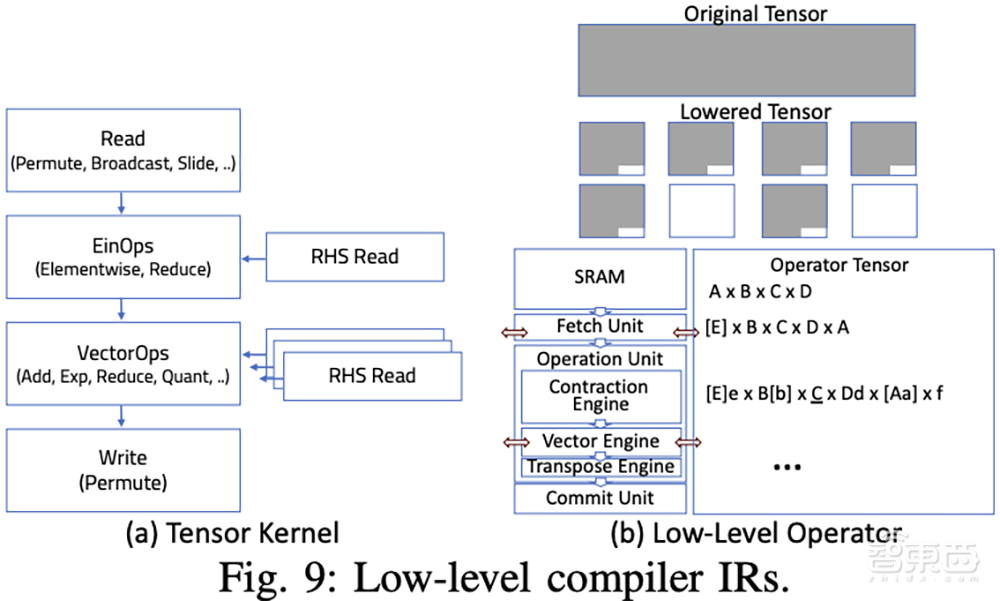
“这是GPU无法实现的,因为它们会动态分配资源,因此很难准确预测性能。”Hanjoon Kim在博客文章中写道。
TCP架构中的PE由一个CPU核心、一个执行大规模张量操作的张量单元和一个张量DMA引擎组成,用于传输张量。张量单元是一个实体,配备32MB SRAM和64TOPS,通过不断地从SRAM中获取输入张量、处理操作并将结果提交回SRAM来加速张量操作。
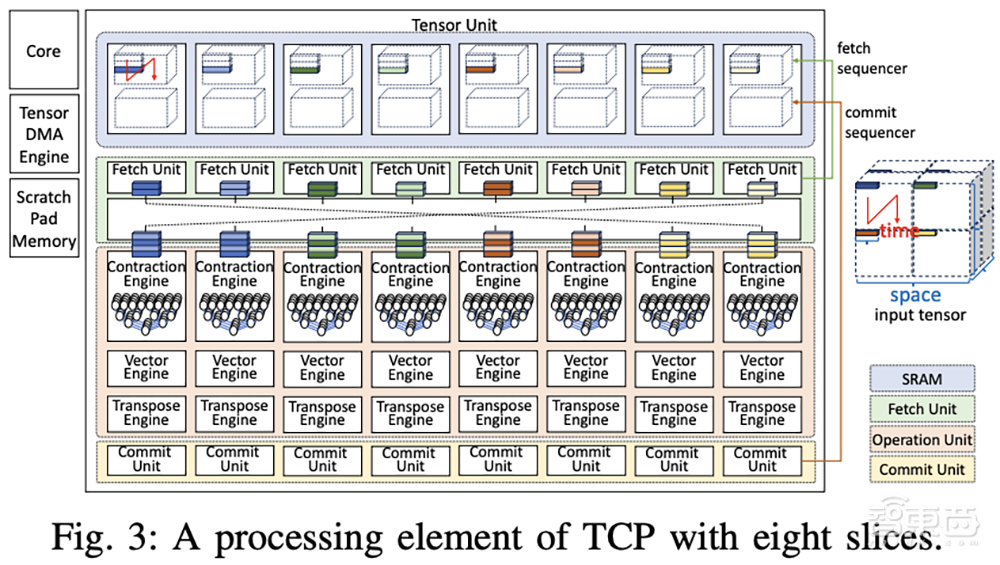
当一个张量操作运行时,向量和内存操作可以并行执行,有效地将它们的执行时间隐藏在张量操作的执行时间内,这有助于提高张量单元的利用率。为了实现这种并行操作,每个切片通过并发运行多个上下文,来执行张量收缩和向量操作。
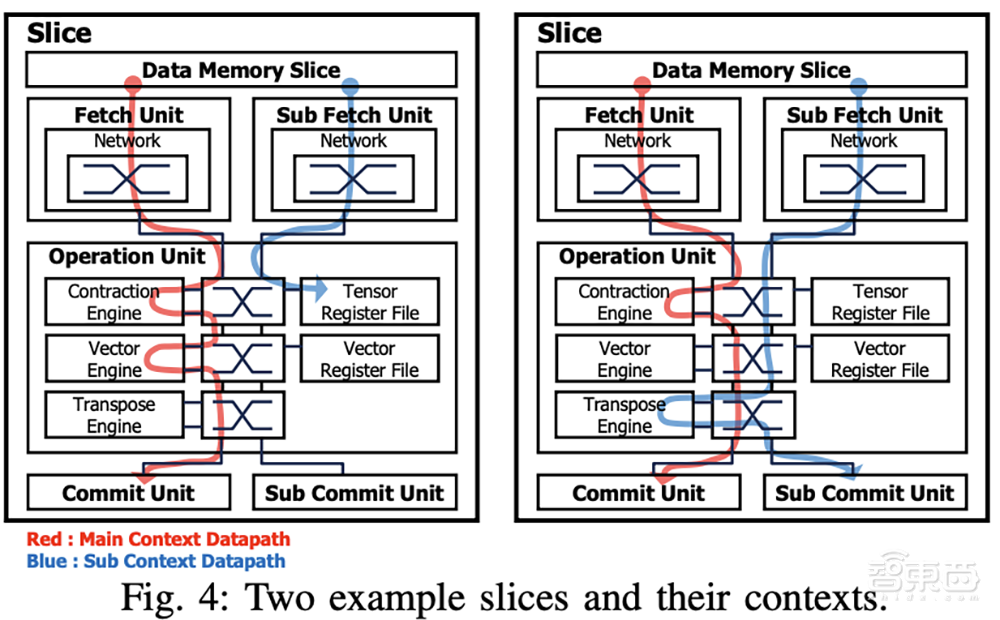
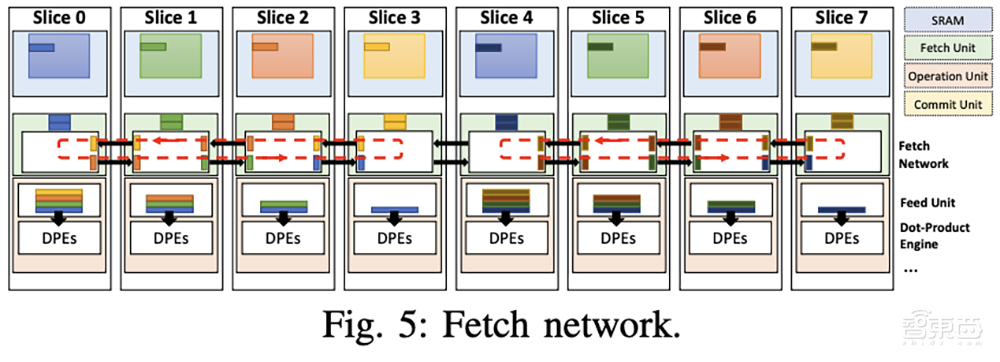
Fetch单元依次从数据内存片访问张量,并将它们传递给操作单元。Fetch网络支持跨多个片的数据重用。
收缩引擎(CE)在两个张量之间执行点积运算。其数据路径由feed单元、寄存器文件、点积引擎(DPE)和累积单元组成。它们由操作顺序器控制。DPE从feed单元和寄存器文件接收两个输入向量,每次输入可容纳32 BF16值、64 FP8值、64 INT8值或128 INT4值。输入元素的数量也表示指定输入类型的最大吞吐量。
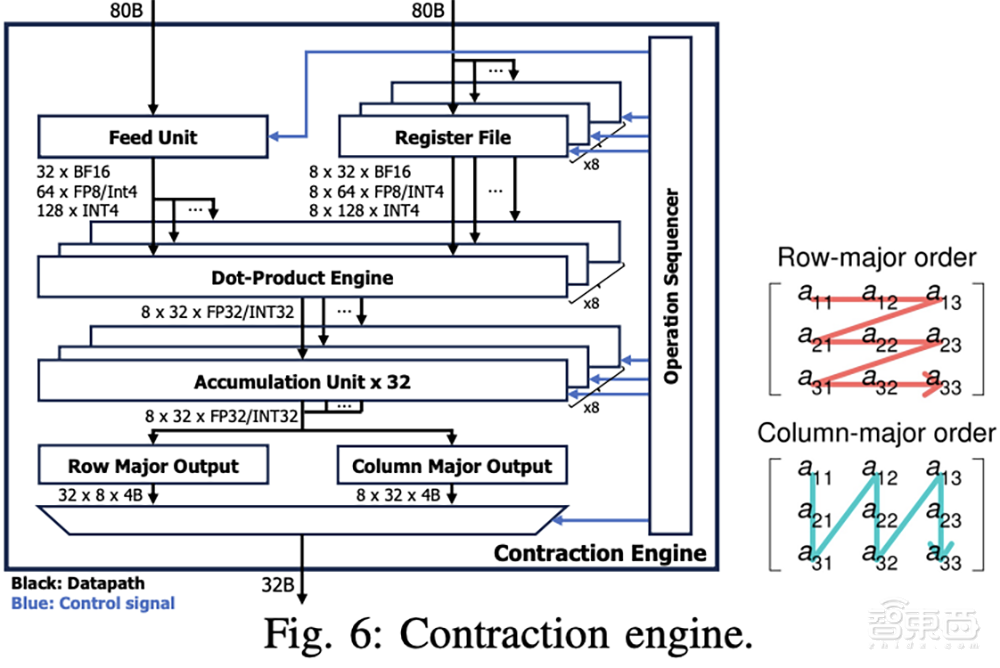
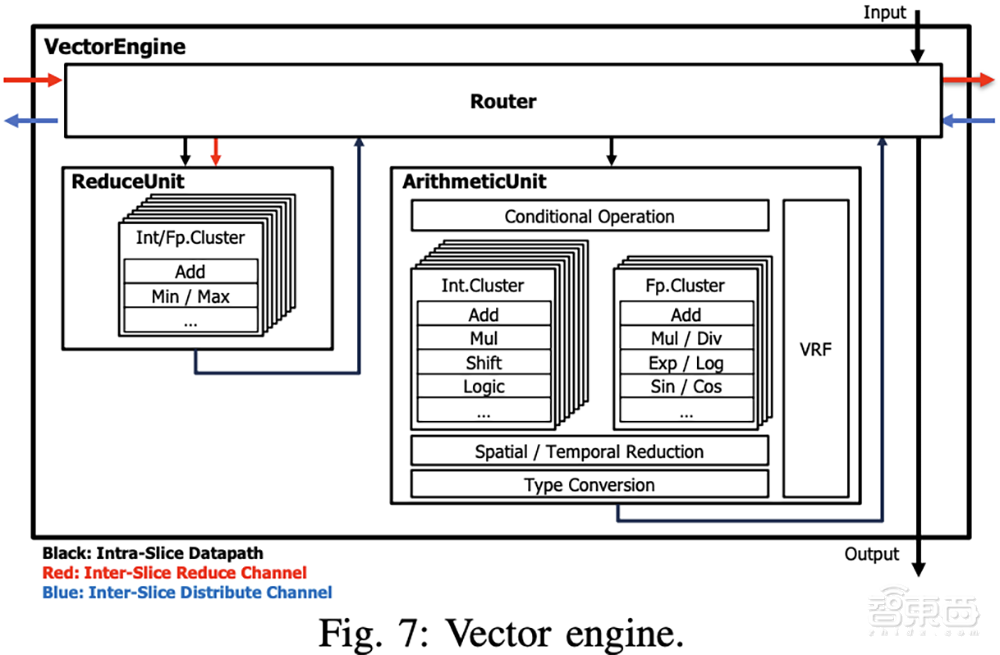
下图是处理非线性函数、元素操作、约简和类型转换的向量引擎(VE),由多个功能单元组成集群,编译器可以通过形成链来对其进行流水线处理。功能单元实现了INT32/FP32上的各种算术和逻辑运算,支持INT4/8/16/32、FP8、FP16/BF16、FP32的各种类型转换和量化。
编译器在TCP计算中探索张量形状的可能选择及其顺序,并尝试为给定的性能和功耗要求提供最佳配置。
三、张量收缩:实现广泛并行,增强数据重用
Hanjoon Kim称,对于所有芯片架构,在DRAM和芯片处理元件(PE)之间传输数据,比执行计算本身所消耗的能量要多得多(多达10000倍)。
为了高效地实现AI算法,芯片必须通过重复使用已存储在片上内存中的数据,来最大限度地减少数据移动。如果数据可以分成可预测、可重复的模式或片段,它通常可以多次使用。
对于大语言模型和其他生成式AI这些涉及大量数据、规模大道无法放进片上内存,数据重用尤为重要,是提高能效和整体性能的有效策略。

AI模型中的矩阵乘法实际上是一种更通用的运算,称为张量收缩。
张量收缩泛化了矩阵乘法,支持更复杂、更高效的数据交互,通过在单个操作中组合多个维度上的元素来减少计算开销。这不仅利用张量固有的多维性质实现更广泛的并行性,而且还增强了这些操作之间的数据重用。
当张量被展平或分解为二维矩阵时,这种并行性通常会被破坏。例如,语言模型的输入可能是三维张量,其批处理大小、序列长度和特征的轴各不相同。将其重新整形为二维矩阵可能会掩盖不同序列之间的区别。这使得利用数据包含多个并行文本序列这一事实变得更加困难。
Furiosa的TCP架构旨在解决这些限制,并最大限度地提高数据重用率。
与GPU不同,TCP的基本数据结构是张量,它执行的基本操作是张量收缩。这意味着TCP在执行计算之前不需要采取额外的步骤将张量划分为二维矩阵。
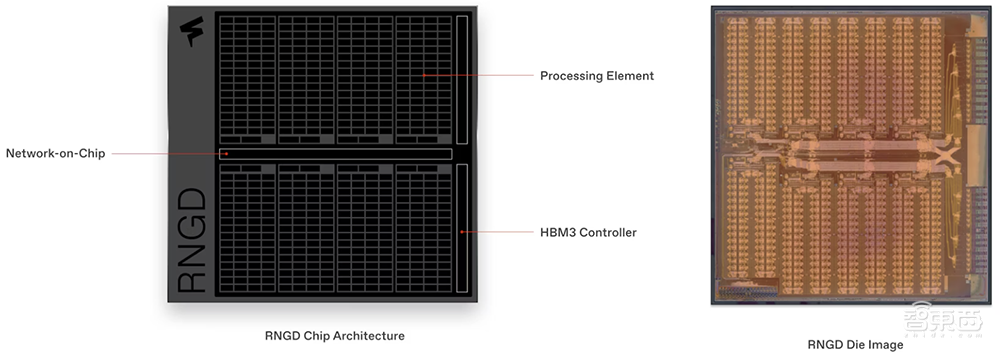
RNGD芯片包含8个相同的处理元件,它们可以独立运行,也可以在需要时“融合”在一起。每个处理元件有64个“切片”,每个切片都有一个计算管道和SRAM,用于存储正在处理的张量的分区部分。
数据还可以通过提取网络多播(而不仅仅是复制)到多个切片的操作单元。这大大减少了SRAM访问次数,并提高了数据重用率。调度是通过硬件结构明确完成的,而不是作为线程,与GPU相比,这大大简化了数据路径。
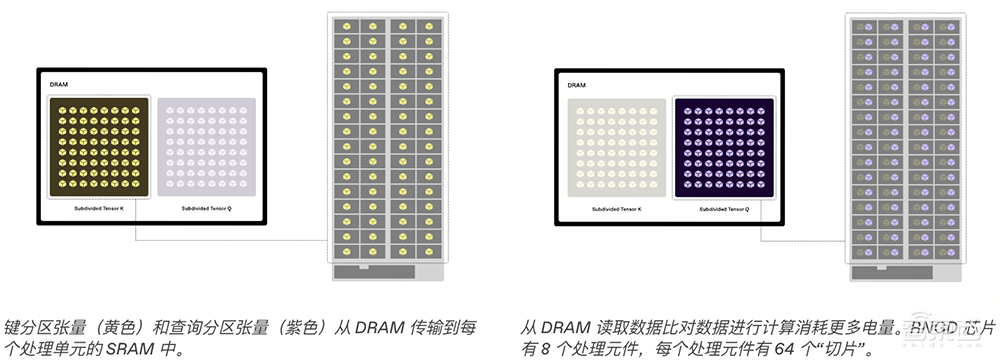
下图是Key和Value张量的简化图示,它们是Transformer模型中使用的多维数据结构。
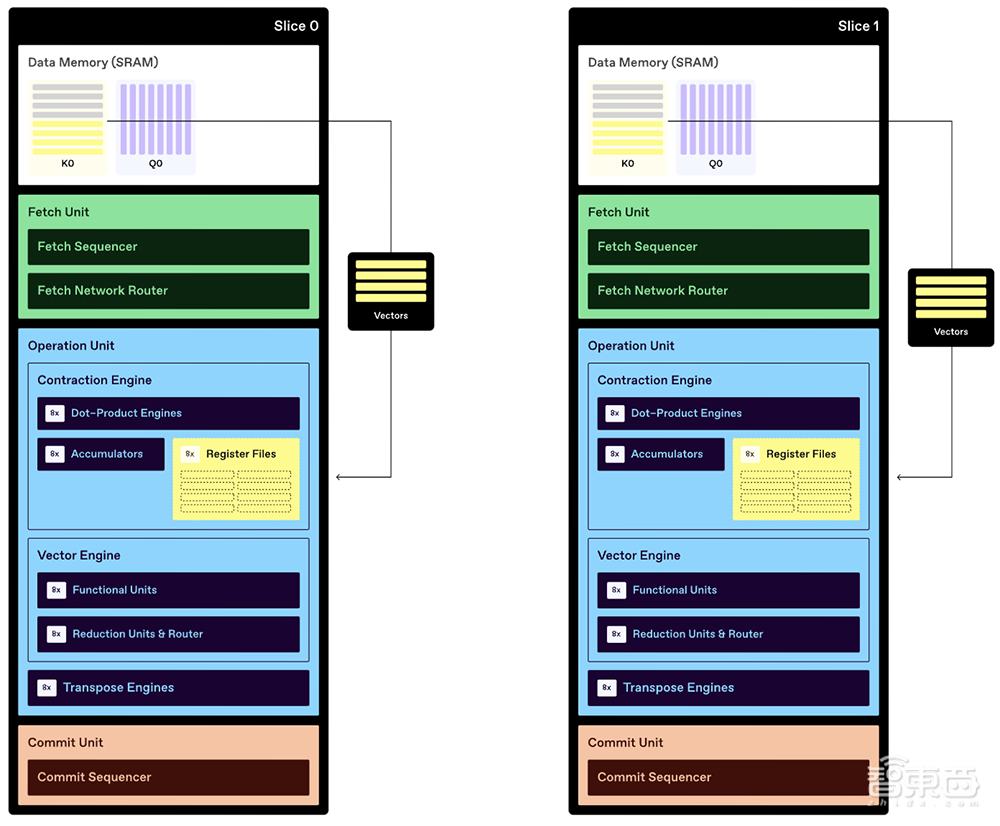
此简化示例中的每个张量都有单独的维度,用于序列长度、输入标记和注意力头的数量。这两个张量分别细分为较小的分区张量,然后从DRAM传输到TCP芯片中每个处理元件的SRAM中。从DRAM读取数据比使用数据执行计算更耗电,因此TCP架构旨在最大限度地重复使用已存储在SRAM中的数据。
 一旦将它们存储在每个切片的SRAM中,Key和Query分区张量就可以被划分为一维向量,而无需先将它们划分为二维矩阵。每个切片从Query分区张量中获取向量,并将它们从SRAM“流式传输”到点积引擎,在那里进行计算。数据还会从每个切片的SRAM多播到其他切片,从而实现更大的数据重用,而无需额外的DRAM读取。(注:多播数据通过获取网络路由器传送,但此简化图中未显示。)
一旦将它们存储在每个切片的SRAM中,Key和Query分区张量就可以被划分为一维向量,而无需先将它们划分为二维矩阵。每个切片从Query分区张量中获取向量,并将它们从SRAM“流式传输”到点积引擎,在那里进行计算。数据还会从每个切片的SRAM多播到其他切片,从而实现更大的数据重用,而无需额外的DRAM读取。(注:多播数据通过获取网络路由器传送,但此简化图中未显示。)
在上面的例子中,FuriosaAI展示了TCP架构如何计算多头注意力中使用的常见张量收缩:QK ᵀ。此计算是Transformer模型的核心部分,其中FuriosaAI找到查询向量和所有键向量的点积,以生成每对输入标记之间的注意力分数矩阵。
QK ᵀ也可以用简洁表达张量运算的常用方法einsum表示法来表示,例如HQD, HKD → HQK,其中H代表头的数量,Q和K代表查询和密钥张量,D代表每个头的维度大小。收缩沿H轴并行操作,收缩发生在D轴上。
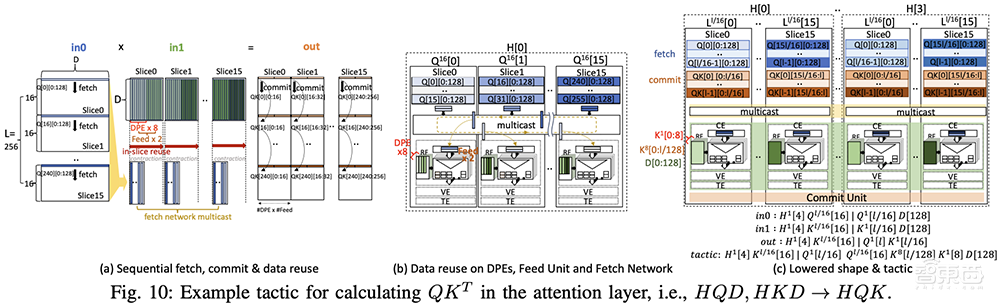
如图所示,查询和密钥张量都仅从DRAM中获取一次,然后存储在SRAM中并在所有QK ᵀ操作中重复使用。
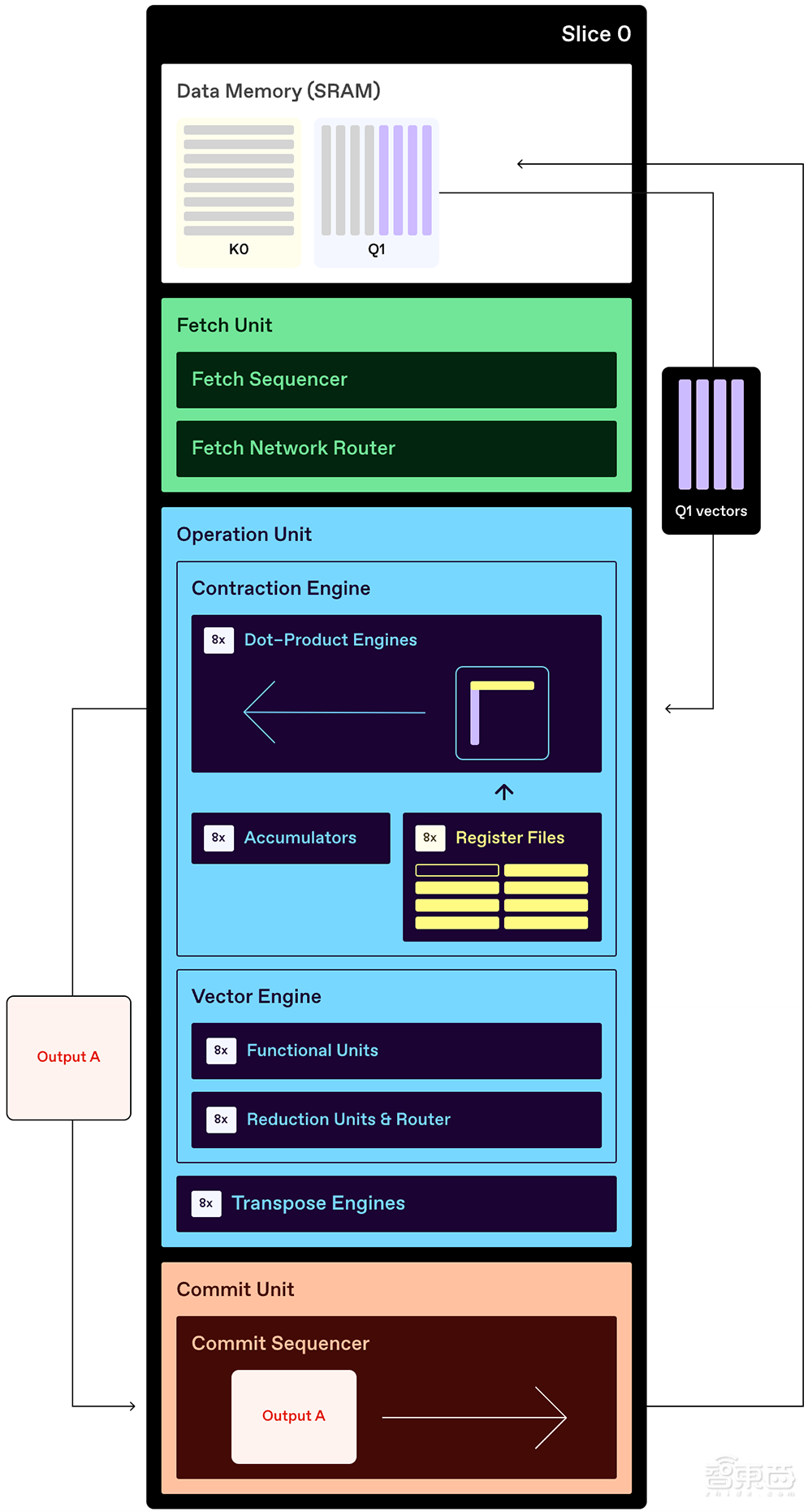
为了进一步减少数据移动,RNGD芯片将某一层的输出激活直接用作片上内存中下一层的输入激活,无需任何额外的DRAM访问。
下图显示了使用不同策略时注意层的性能和功耗。不同策略利用不同类型的数据重用,这取决于获取的顺序和缓冲区的管理方式,从而导致性能和功耗的不同权衡。
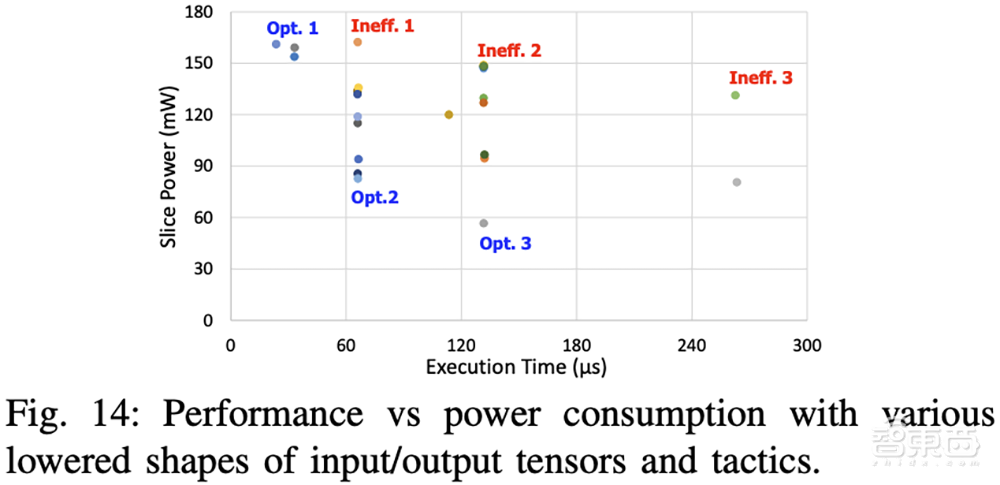
对于性能关键型系统,编译器将选择性能最高的策略,即图中左上角的点Opt. 1。在严格的峰值功率约束下的系统,则可能需要更低的功率策略,例如Opts. 2、Opts. 3。
结语:数据中心呼唤更高能效的AI芯片
计算是开发和部署新型AI系统的一个关键限制因素。业界普遍预计未来对更多计算的需求将大幅加速,开发高能效AI芯片是实现AI可持续发展的关键方式之一。
许多硬件创新将帮助行业满足对更高性能、更高能效的AI处理器的需求。其中主要进步包括新型HBM、PCIe 5.0、2.5D/3D封装等。但要创造一个真正丰富的AI计算时代,仍需探究芯片架构创新。
FuriosaAI团队相信,得益于其高能效,RNGD芯片可以广泛部署于数据中心,例如,无需高性能GPU所需的复杂液体冷却系统。
周二,Hot Chips 2024上围绕AI芯片的议题继续,上午的主题演讲包括适用于视觉和汽车的AMD Versal AI Edge系列、斯坦福大学的稀疏张量代数可编程加速器Onyx、Meta新一代AI推理芯片MTIA、特斯拉DOJO、网络芯片创企Enfabrica的超级网卡ACF-S、英特尔的 4Tbit/s光学计算互连芯片。
下午的主题演讲有Cerebras的晶圆级AI芯片、中科院计算所的香山高性能RISC-V处理器、微软首款AI芯片MAIA、AMD新一代Zen5核心、日本创企Preferred Networks的第二代AI处理器MN-Core 2。芯东西将持续关注。
