








▲头图由AI生成
智东西(公众号:zhidxcom)
作者 | 三北
编辑 | 漠影
城市大模型正处于爆发前夕,数据很可能成为一只“拦路虎”。
当下,北京、上海、深圳等多地都推出了AI新政策,提出“在城市大脑建设中应用大模型”、“构建开放式城市大模型服务平台”等明确指示。沉睡的城市数据成为大模型的“养料”,同时数量巨大、种类异构等特征也加大了大模型落地的难度。
数据存储是数据价值挖掘的第一关口,大模型正倒逼产业进化。过去一年多,包括曙光、华为等基础设施龙头,以及阿里云、腾讯云、百度智能云等云厂商都面向大模型进行了数据存储产品优化,动辄达数倍模型训练效率提升。
曙光存储运营总监石静告诉智东西:“从过去一年多次与客户的沟通情况来看,大家从早期直接要PB级的存储容量,到咨询存储如何让GPU发挥更大效能,到现在则更加关注契合应用需求的变化,这都推动曙光存储产品不断进化。”
据悉,目前,曙光ParaStor分布式存储产品能将AI整体表现提升超20倍,已落地了北京、泉州、中国移动等多个AI智能化项目,并在大模型、具身智能机器人、自动驾驶、智算中心等各个领域落地,打造了AI大模型应用标杆案例。

▲曙光ParaStor分布式全闪系列产品
随着算力、模型的价格降低,数据成为AI产业落地的“牛鼻子”。如何挖掘城市中的海量数据价值,让AI助力城市智能化发展,进而渗透到千行百业?从存储环节来看,整个AI落地的成本压缩逻辑是什么样的?
通过对话曙光存储运营总监石静,沿着曙光AI数据存储落地的足迹,我们对这些问题有了深入了解。
一、AI城市大脑进化时,向数据存储要成本和效率
当下,城市已成为AI落地的第一站,数据存储成为不容忽视的短板环节。
北京、上海、广东等一线城市及省份均发布了将大模型与城市治理相结合的相关政策。比如《北京市推动“人工智能+”行动计划(2024-2025年)》提出“构建开放式城市大模型服务平台,打造智慧城市大脑”;《广东省加快数字政府领域通用人工智能应用工作方案》提出“探索人工智能与城市大脑等场景创新”。各地都在加速推动AI与城市智能化建设融合发展,落地城市治理、数字政务、智慧交通、智能制造、商业等各个领域。





▲城市智能化领域AI及大模型部分核心政策(智东西梳理)
石静告诉智东西,在AI时代,城市智能化建设发生了较大变化。
此前,“城市大脑”更侧重抓取城市数据去做智能分析,现在更主要的是借助大模型去辅助城市决策和管理;此前很多项目用CPU算力就行了,现在则更多考虑异构算力,GPU等AI算力占比投入大大提升。
以泉州联合曙光推进的智慧城市项目为例,项目涉及图片、语音、视频等多种业务数据,要将这些数据汇聚接入AI大模型,不仅对存储性能和安全可靠提出更高要求,对异构数据的纳管能力要求也很高。其在方案中兼顾了这些多方面需求,从而实现城市数据快速互联,支持城市大脑中枢决策。
再以智慧交通场景为例,此前各地主要是将数据汇聚后来做简单分析,现在则是通过交通垂直大模型辅助决策。曙光存储也跟业界专门做交通大模型的厂商做了相关适配,以提供整个城市交通态势掌控、更科学的交通调配等更多服务。
在这一过程中,忽略存储是比较要命的。
石静说:“算力越来越快,如果存储跟不上,这很可能导致GPU算力空转或等待,从而使资源效率难以发挥;如果忽略存储,一些数据质量问题的出现,也可能导致大模型效果出现偏差。”
具体来说,当下城市智能化进程对数据存储提出了以下新要求:
1、存储性能要更极致。只有足够快的存储,才能匹配上足够快的GPU或者AI芯片。2、存储更加契合用户业务。从通用大模型到行业生产大模型需要针对性调优,要求存储具有一定的可定制化能力。3、数据安全要求更高。大模型训练若出现中断往往损失惨重,保障数据安全可靠尤为关键。4、更强异构数据的纳管能力。面向大模型,非结构化数据的采集、汇聚、分析、处理能力提升。
“百模大战”快速发展一年,得益于数据存储技术进步,城市智能化项目的计算效率大幅提升。
石静告诉智东西,在带宽指标方面,曙光存储ParaStor分布式全闪单个节点已经做到最高150GB/s带宽,也就是一秒钟可为用户提供150G的数据吞吐,这个指标还在快速提升中,早在两个月前还是130GB/s。
在IOPS指标方面,智存ParaStor产品可以提供320万IOPS/s,也就是一秒钟可以处理320万个I/O请求,相较于以前有了十倍以上的提升。而同样的硬件配置下,当前市场主流产品的单节点带宽能力普遍在100GB/s以内,单节点的IOPS能力基本在200万以下。

▲曙光ParaStor分布式全闪在相关指标情况
二、从城市体到千行百业,数据成AI落地的“牛鼻子”
众所周知,AI大模型落地,受到算力、算法和数据“三驾马车”牵引。
石静谈道,在前期大家更多关心模型、算力如何,但随着AI的发展,数据应该排到更靠前的位置。大模型能否很好地指导各行各业的发展?存储所承载的数据质量非常关键。
今年1月4日,国家数据局等17部门联合印发《“数据要素×”三年行动计划(2024—2026年)》(简称:行动计划),提出选取工业制造、现代农业、商贸流通、交通运输、金融服务等12个行业和领域,推动发挥数据要素乘数效应,释放数据要素价值。
从城市到千行百业,新一代智存技术已经在促进“数据要素x”发展。
在热门的具身智能领域,“天才少年”稚辉君创办的智元机器人刚刚在8月发布了第一代具身智能机器人远征A1,号称达200TOPS算力。基于曙光ParaStor分布式全闪存储提供与算力匹配的高性能存储池,智元机器人在大模型训练中实现了存储的低延时、高IO吞吐,从而释放了强大的AI算力。
在自动驾驶领域,国内知名造车新势力通过模型模拟仿真,加速新车型从量产走向市场,曙光在2022~2024年连续为其提供超百PB的存储资源,包括通过NVMe全闪产品提供单节点45GB/s带宽和百万级IOPS,最大化提升自动驾驶模型训练效率;3天内帮助用户从几十个节点扩展到200+节点,应对扩展中的数据挑战;存储负载率长期维持在85%以上,保障数据的完整性和可靠性。
在智算中心领域,中国移动在2022年启动了全球运营商最大单体智算中心,针对中心所需的海量非结构化数据承载、多协议互融等存储需求,曙光ParaStor满足了其对存储灵活性的需求,顺畅完成全局统一调度与管理,为项目未来超大规模模型跨地域、多中心并行训练提供了存力保障。
而聚焦AI大模型生产本身,曙光ParaStor分布式全闪存储支持某AI大模型厂商亿级文件数据训练及推理,相比原系统提效50%,最终相隔两月内即发布上线大模型新版本;支持某科技大模型厂商整体训练效率提升50%以上。
可以看到,从城市体到千行百业都在加速智能化,当模型和算力价格降低,数据正成为AI落地新的“牛鼻子”。

▲曙光存储产品全家福
三、强者恒存,曙光存储跑出中国AI加速度
AI大模型飞速发展,也反过来倒逼存储产业升级。
在过去一年多时间里,包括曙光、华为等基础设施龙头企业,以及阿里云、腾讯云、百度智能云等云厂商,都针对AI大模型研发与落地的全流程,对存储产品进行了性能优化。各大厂商的存储产品的优化方向具有一致性,都强调高性能、多协议、可定制、高安全等提升。
其中,作为深耕AI存储多年的头部玩家,曙光ParaStor分布式全闪存储将AI整体表现提升了超20倍。这是如何实现的?
石静告诉智东西,曙光是从两大核心去解决的,可以总结成:最强的数据底座、最佳的AI应用加速套件。
在数据底座方面,存储就是要去发挥极致的硬件性能,软件要把CPU、内存、网络和硬盘介质的性能发挥出来。在AI方面,现在大家都在通过高速网络,加上NVMe SSD闪存介质去实现,存储软件把高速网络跟NVMe介质的协同发挥出来,实现最高性能。
在AI应用加速套件方面,这需要结合AI方向特殊的一些应用模式做优化。曙光有五大加速技术方案,能够通过分析AI整个的流程去尽量缩短整个I/O流程,让GPU更加靠近存储,或者说让存储更加靠近于显存。
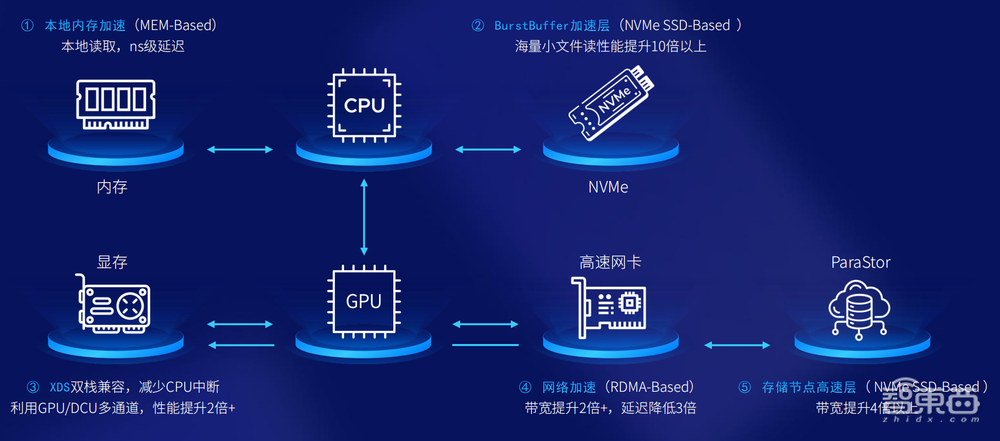
▲曙光AI应用加速套件五级加速
具体展开这五级加速,覆盖了数据流动到GPU服务器、网络和存储的整个阶段:
1、本地内存加速。首先把计算节点本身的CPU对应内存利用起来,将一些关键的数据缓存在那里,做第一层加速层,延时降至纳秒级别。
2、BurstBuffer加速层。进一步把GPU服务器本地的NVMe盘利用起来,它相较本地内存容量大很多,把这些数据缓存起来以后,就能够保证海量数据不用跨网络访问存储,把读取性能提高几倍甚至十倍以上。本地内存加速和BurstBuffer都是聚焦计算节点本身。
3、XDS双栈兼容,减少CPU中断。让GPU去直通访问存储,缩短整个I/O通路;不光实现GPU跟存储的直接交互,还通过存储技术让AI智能芯片跟存储直接打交道,从而减少CPU本身的损耗,降低延时。
4、网络加速(RDMA-Based)。在网络层,用RDMA技术等技术,不管是IB网络还是在以太网里,RDMA或RoCE都能够把网络带宽给跑满,实现第三层加速。
5、存储节点高速层( NVMe SSD-Based )。最后是存储本身,当下在AI应用最多的主要是NVMe全闪存,把全闪存本身的性能充分发挥出来。
深耕存储领域20年,曙光不仅在技术进化方面紧跟市场需求发展,还不断推进存储产业开放生态建设。
石静称,目前,曙光存储在国产和非国产硬件上都充分开放,通过软硬件一体形态支持客户搭建数据底座;存储与多种前端应用计算节点平台兼容,支持国内外AI芯片直通存储;存储兼容更多AI应用,通过智能I/O分析工具辅助其存储更好地契合应用,做到应用开放。
强者恒存,曙光正跑出中国AI的加速度。
可以看到,大模型发展不仅推动国产存储厂家不断实现技术突破,还以更加开放的心态推动软硬件兼容、计算平台兼容及应用兼容,从而强化AI落地。
结语:从曙光的AI足迹,看到数字山河间的中国速度
随着大模型落地各行各业,加速已成为AI数据存储的核心需求。从曙光城市智能化到各行各业的AI落地案例来看,其存储方案通过缩短数据读写时间,大大提升了AI大模型的训练效率,减少算力的空转等待时间,从而降低AI成本。
20年筚路蓝缕,曙光存储伴随着中国信息化、数字化和智能化转型一路发展。当下,大模型成为全球科技竞赛的主赛场,以曙光为代表的国产ICT龙头正通过更精尖的技术、更贴近场景的服务、更开放的生态助力国内大模型产业发展,跑出数字山河间的中国速度。
