








智东西(公众号:zhidxcom)
编译 | Vendii
编辑 | 漠影
智东西8月30日消息,阿里通义千问于昨日开源新一代视觉语言模型Qwen2-VL。其中,Qwen2-VL-72B在大部分指标上都达到了最优,刷新了开源多模态模型的最好表现,甚至超过了GPT-4o和Claude 3.5 Sonnet等闭源模型。
据官方博客文章介绍,Qwen2-VL基于Qwen2打造,相比第一代Qwen-VL,Qwen2-VL具有以下特点:
1、能读懂不同分辨率和不同长宽比的图片:Qwen2-VL在多个视觉理解基准测试中取得了全球领先的表现,其中包括但不限于考察数学推理能力的MathVista、考察文档图像理解能力的DocVQA、考察真实世界空间理解能力的RealWorldQA、考察多语言理解能力的MTVQA。
2、能理解20分钟以上的长视频:Qwen2-VL可理解长视频,并将其用于基于视频的问答、对话和内容创作等应用中。
3、能够操作手机和机器人的视觉智能体:借助复杂推理和决策的能力,Qwen2-VL可集成到手机、机器人等设备,根据视觉环境和文字指令进行自动操作。
4、多语言支持:除英语和中文外,Qwen2-VL现在还支持理解图像中的多语言文本,包括大多数欧洲语言、日语、韩语、阿拉伯语、越南语等。
通义千问团队以Apache 2.0协议开源了Qwen2-VL-2B和Qwen2-VL-7B,并发布了Qwen2-VL-72B的API。开源代码已集成到Hugging Face Transformers、vLLM和其他第三方框架中。
GitHub项目地址:https://github.com/QwenLM/Qwen2-VL
一、媲美GPT-4o!多个指标刷新最好表现,3种规模模型开源
通义千问团队从6个方面来评估Qwen2-VL分别在72B、7B、2B三种规模上的视觉能力,包括复杂的大学水平问题解决、数学能力、文档和表格的理解、多语言文本图像的理解、通用场景问答、视频理解、视觉智能代理(Visual AI Agent)能力。
整体来看,Qwen2-VL-72B在大部分指标上都达到了最优,甚至超过了GPT-4o和Claude 3.5 Sonnet等闭源模型。
具体而言,该模型在文档理解方面优势明显,仅在复杂的大学水平问题解决方面和GPT-4o还有差距。同时,Qwen2-VL 72B也刷新了开源多模态模型的最好表现。
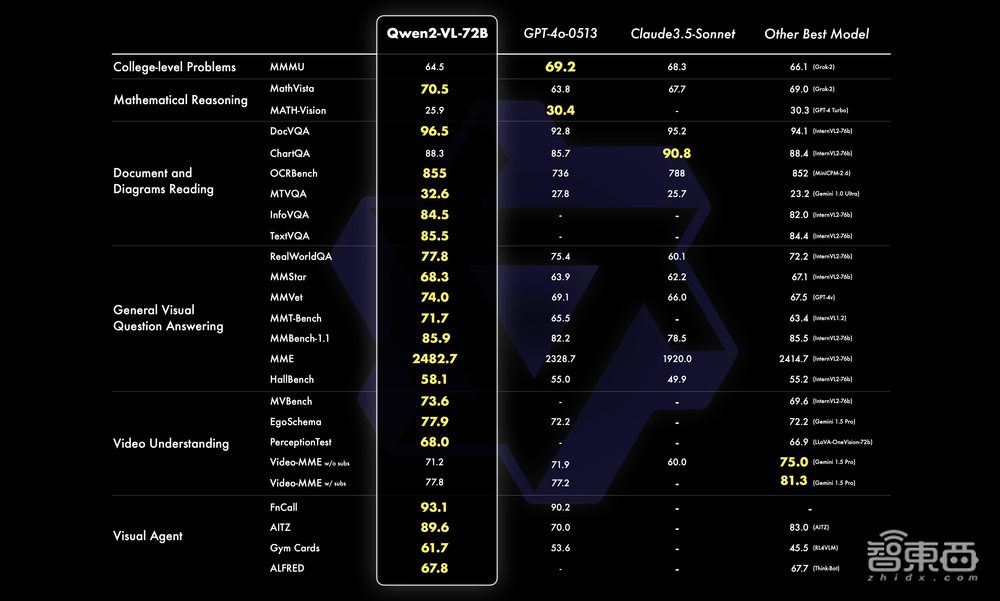
▲Qwen2-VL-72B模型能力分数比较(图源:通义千问团队官方博客文章)
在7B规模上,Qwen2-VL同样支持单图、多图、视频的输入,在更经济的规模上也实现了有竞争力的性能表现。
比如,Qwen2-VL-7B在DocVQA考察的文档理解能力,以及MTVQA考察的多语言文本图片理解能力都处于SOTA水平。在AI领域,SOTA模型通常是指在特定任务或数据集上性能表现最优的模型。
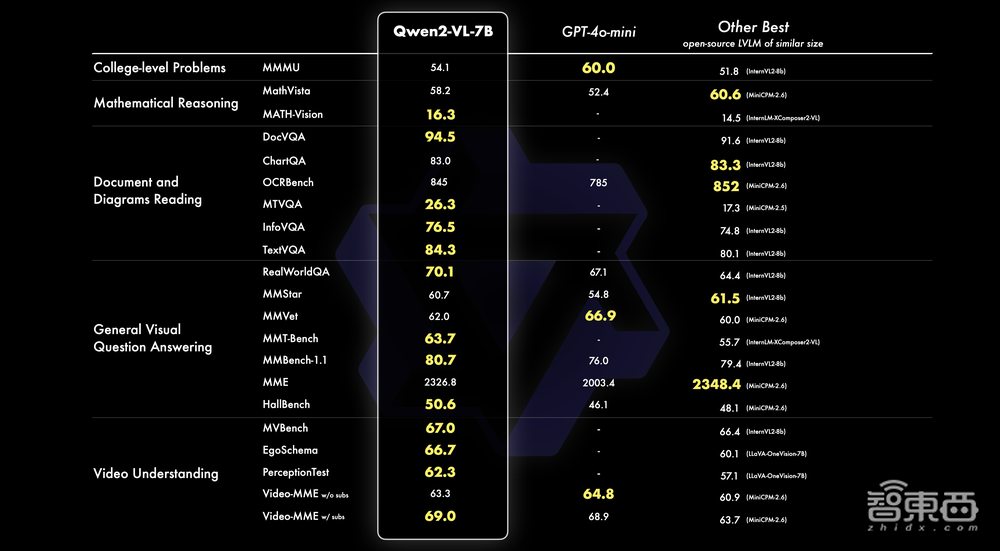
▲Qwen2-VL-7B模型能力分数比较(图源:通义千问团队官方博客文章)
除此之外,通义千问团队还提供了一个更小的2B规模的模型,以此支持移动端的丰富应用。Qwen2-VL-2B具备完整图像视频多语言的理解能力,特别在视频文档和通用场景问答方面,相较同规模模型优势明显。
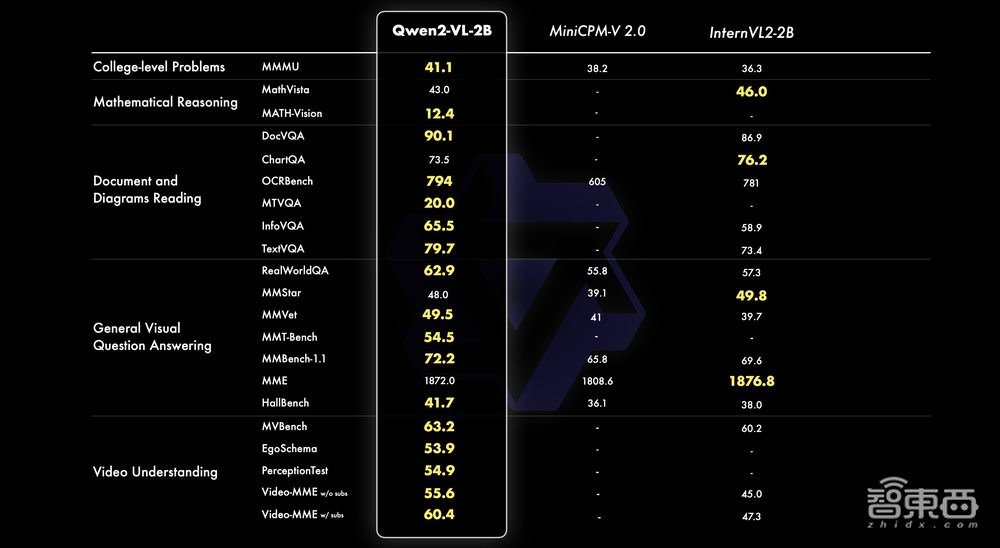
▲Qwen2-VL-2B模型能力分数比较(图源:通义千问团队官方博客文章)
二、手写字体、公式代码、网页截屏、视频影像……多场景识别理解不在话下
在官方博客文章列举的多个模型能力案例中,Qwen2-VL覆盖了广阔的应用场景:能识别手写文字、图中文字,能转写数学公式、多种语言文字,能解数学几何题、LeetCode编程题,能读懂不同分辨率和不同长宽比的图片,能用特定格式输出答案,还能对视频内容进行总结和解读。
1、准确识别图中文字,轻松转写数学公式
对于下图列举出来的手写文字、融合在图像中的文字,Qwen2-VL都能准确地识别出对应的语种和文字内容(图中分别涉及到葡萄牙语、中文)。对于下图右下角,Qwen2-VL不只能识别出具体的数字,还能识别出各个数字对应的盒子的颜色。

▲Qwen2-VL能够准确识别图中的文字(图源:通义千问团队官方博客文章)
对于下图左半边中涉及到的复杂数学公式,Qwen2-VL可以轻松地用Markdown格式转写出来。对于下图右半边中涉及到的中文、日语、韩语、西班牙语、葡萄牙语、爱尔兰语、英语、德语、波兰语、希腊语、越南语、蒙古语、俄语、印地语、斯瓦希里语,Qwen2-VL也能一字不落地转录出来。

▲Qwen2-VL能够准确转录图中的复杂公式和多语种(图源:通义千问团队官方博客文章)
2、理解现实世界信息,准确输出问题答案
对于数学平面几何题目、LeetCode平台的编程题目、1792×14400尺寸的技术文档截图,Qwen2-VL也能识别理解并回答用户的提问。
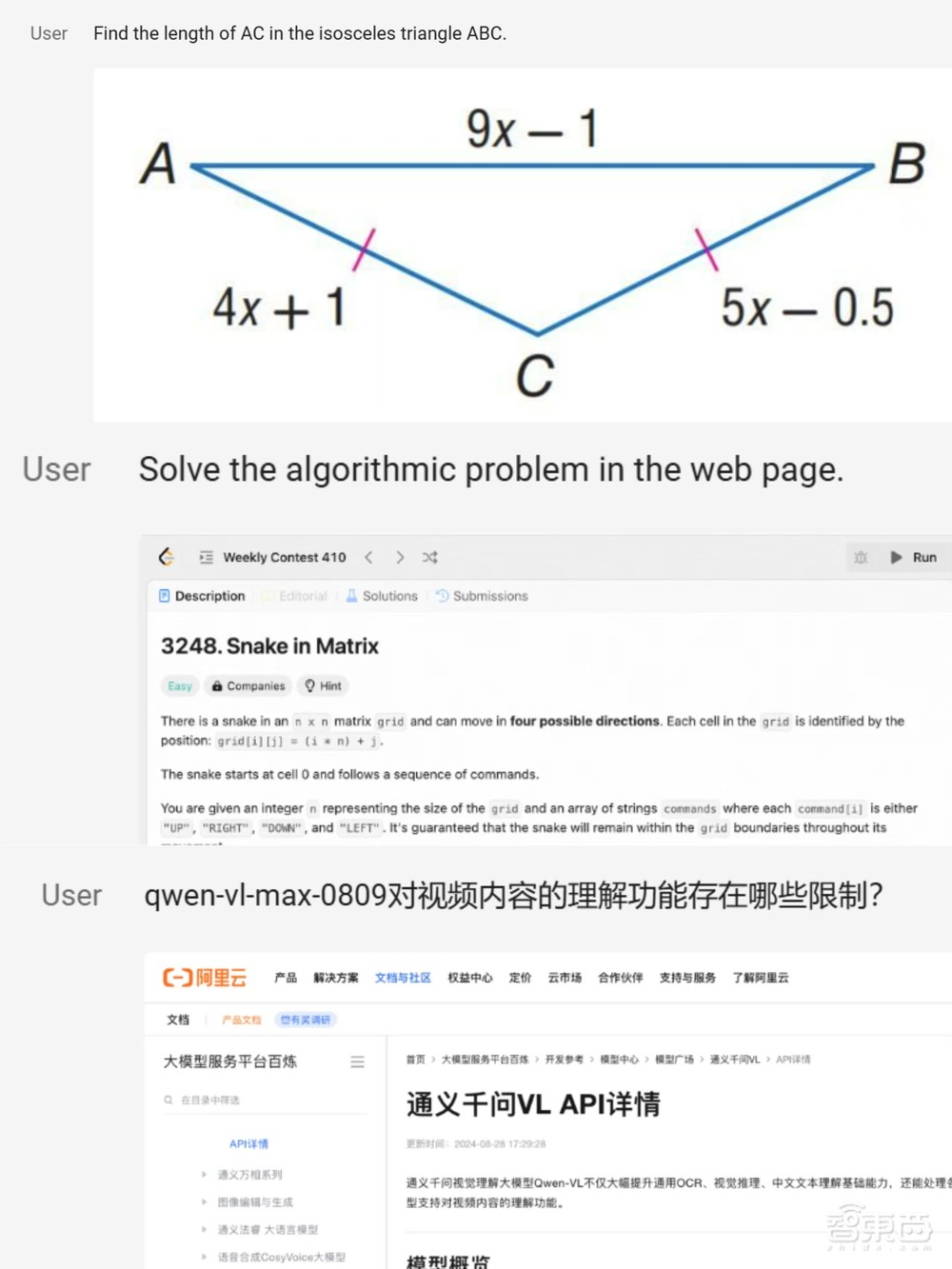
▲Qwen2-VL能够解决的各种问题(图源:通义千问团队官方博客文章)
Qwen2-VL还能基于天气预报软件的截屏、网页搜索结果的截屏、Linux官方档案库的截屏等等抓取用户需要的信息,用特定格式(如表格、段落编号方式、JSON格式的数组)输出。
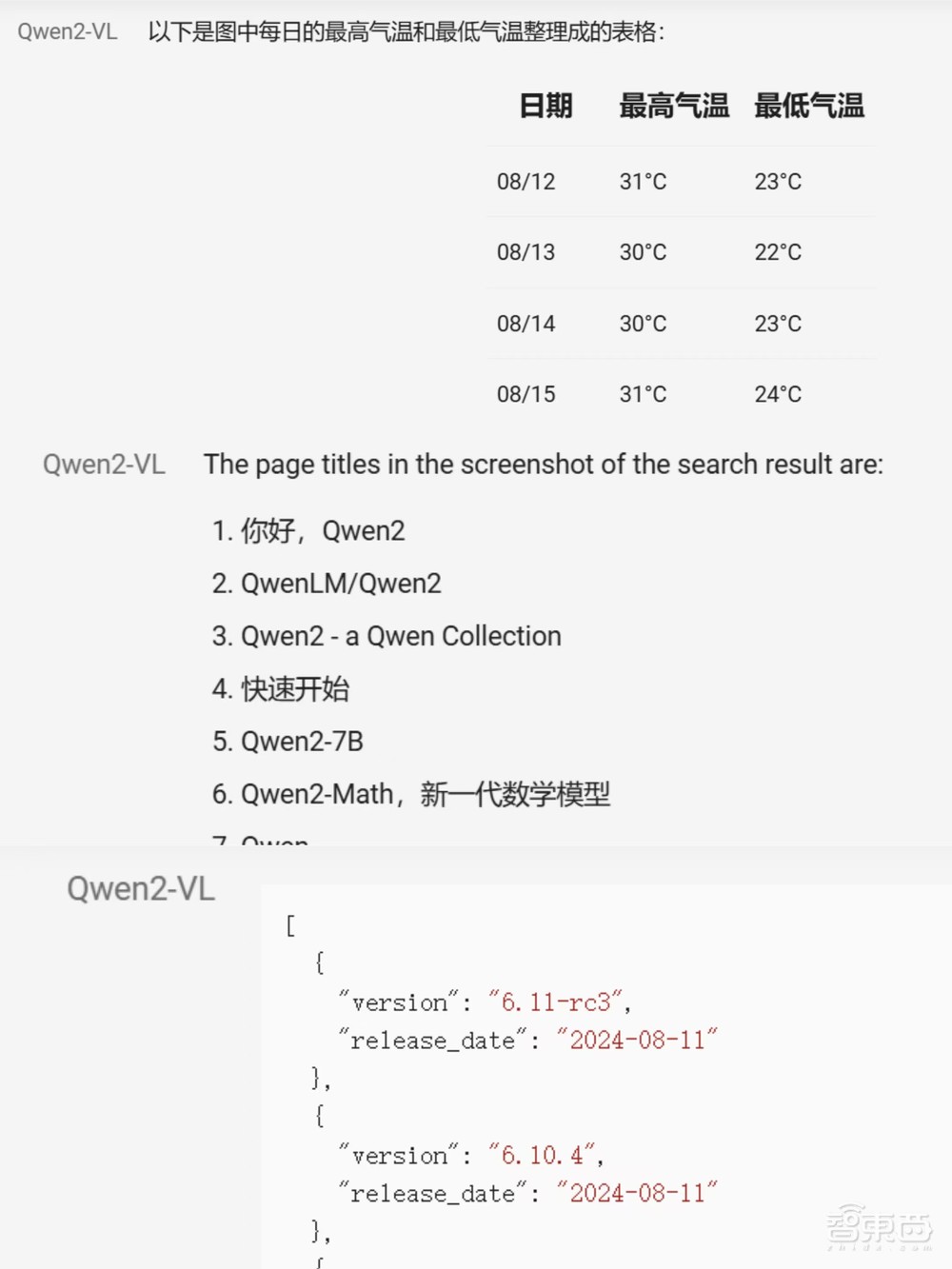
▲Qwen2-VL回答支持多种格式(图源:通义千问团队官方博客文章)
3、总结视频要点,解读视频内容
此外,除了静态图像,Qwen2-VL还能进行视频内容分析。它能够总结视频要点、即时回答相关问题,并维持连贯对话,帮助用户从视频中获取有价值的信息。
比如下图中,用户上传了一段2分57秒的视频,并让Qwen2-VL描述这段视频,描述的内容非常详细且准确。然后用户提问了视频中人物穿着的衣服的颜色,Qwen2-VL也给到了符合视频内容的回答。
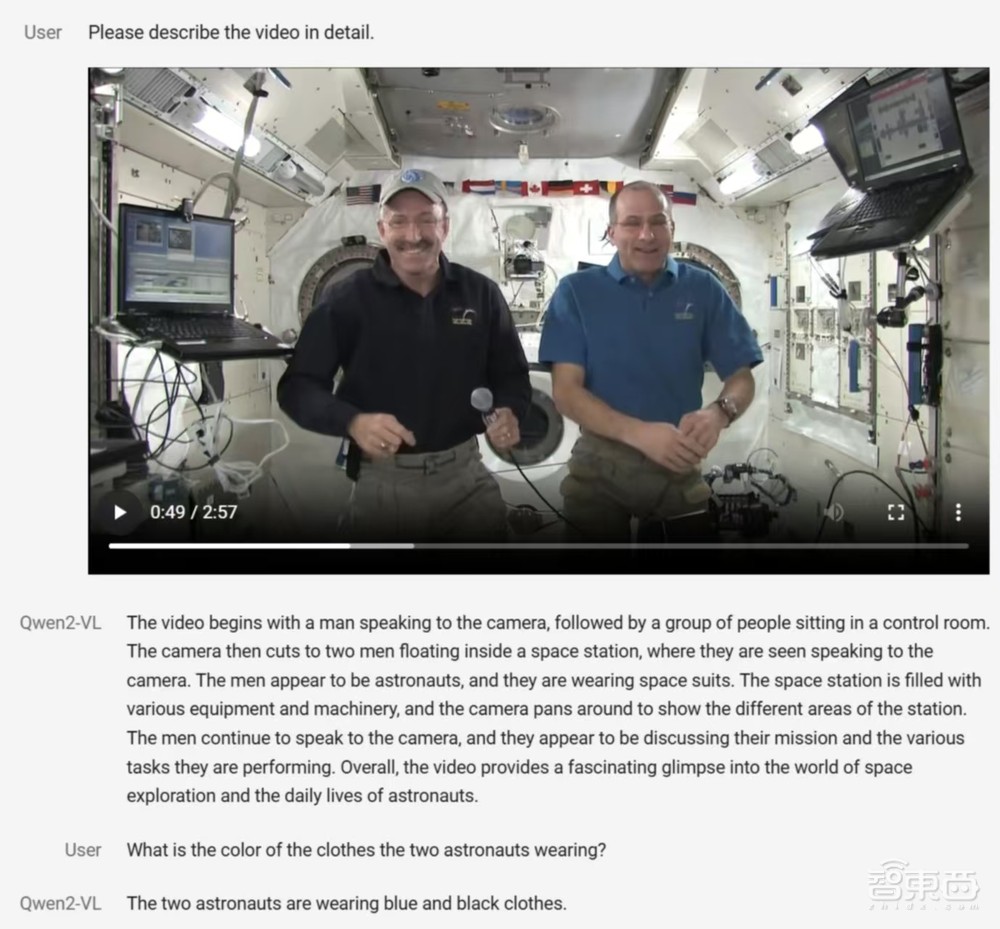
▲Qwen2-VL能够识别视频,并围绕该视频回答相应问题(图源:通义千问团队官方博客文章)
三、实时数据检索+实时环境交互,或将碰撞出更多可能性
据官方博客文章介绍,Qwen2-VL在作为视觉代理方面展现出潜力,能初步利用视觉能力实现一些自动化工具的调用和交互。
视觉代理(Visual Agent)通常指的是一种AI系统,它能够处理和理解视觉信息(如图像或视频),并在此基础上进行决策或执行任务。
Qwen2-VL支持函数调用,使其能够利用外部工具进行实时数据检索,比如航班状态、天气预报、包裹追踪。
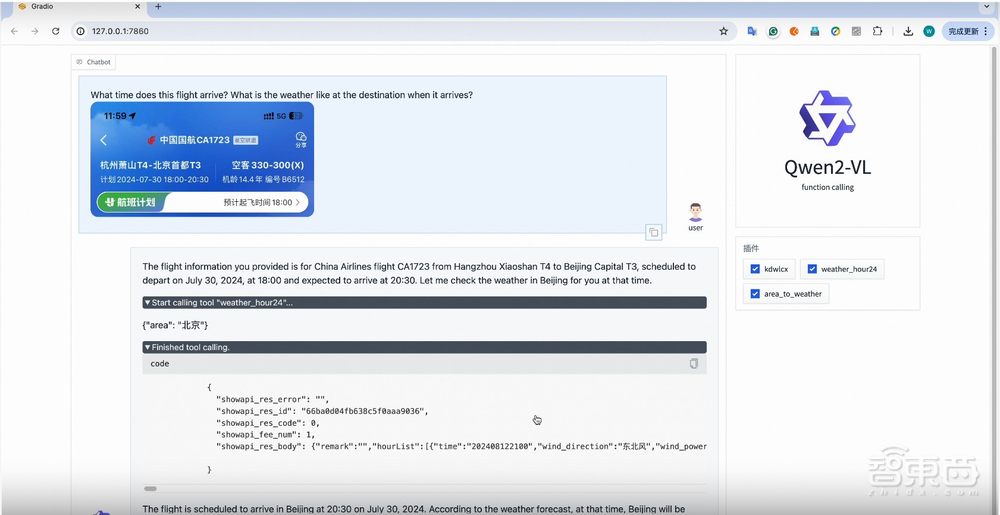
▲Qwen2-VL根据用户提供的航班信息调用“weather_hour24”工具查询天气状况(图源:通义千问团队官方博客文章)
通义千问团队还初步做了一些简单的探索,让模型能够更像人一样和环境交互。“使得Qwen2-VL不仅作为观察者,而是能有代替人做更多的执行者的可能。”官方博客文章写道。
在以下视频中,Qwen2-VL可以直接代替人类操作手机。
▲Qwen2-VL进行视觉交互并自主操作手机(图源:通义千问团队官方博客文章)
以及以下视频中,Qwen2-VL能根据识别到的场上信息和提示词描述进行“24点”游戏的决策,并且取得了胜利。
▲Qwen2-VL进行视觉交互并完成纸牌游戏(图源:通义千问团队官方博客文章)
结语:语言能力已经远远不够!模型正在卷向多模态
随着AI技术的飞速发展,语言模型曾一度成为技术竞争的焦点,但自2023年3月15日OpenAI发布了能够读图的GPT-4后,多模态模型的战鼓也是越敲越响。模型不再局限于处理单一的文本数据,而是通过整合图像、视频、音频等多种信息源,展现出更为强大的认知和理解能力。
视觉语言模型是多模态模型领域内的一个重要细分方向。这些模型通过结合计算机视觉与自然语言处理技术,在图像理解、生成及跨模态交互等领域展现出巨大潜力。它们可以被应用于视觉问答(VQA)、图像分类、目标检测、图像分割等多种任务,未来有望在医疗诊断、机器人技术等领域内实现更加广泛的应用。
来源:GitHub
