








智猩猩是智一科技打造的AI与硬科技知识分享社区,关注大模型、通用视觉、算力、具身智能机器人与自动驾驶,提供讲座、公开课、在线研讨会、峰会等线上线下产品。
「智猩猩具身智能前沿讲座」由智猩猩机器人新青年讲座全新升级而来,致力于邀请来自全球知名高校、顶尖研究机构以及优秀企业的学者与研究人员,主讲在具身智能领域的研究成果与系统思考。
目前很多评测工作都在探究视觉语言大模型在不同维度上的能力,但已有的评测数据都是以物体为中心或者第三人称视角,对于模型在第一人称视角下的能力评测则有显著欠缺。在真实世界中,人会以第一人称视角去观察和理解世界并与之交互。而未来作为具身智能体或机器人的大脑,多模态模型应当具备从第一人称视角理解世界的能力。
针对当前问题,清华大学刘洋教授团队提出了第一人称视角的视觉问答基准数据集EgoThink,相关论文收录于 CVPR 2024 并获得 Highlight。其中清华大学万国数据教授、智能产业研究院执行院长刘洋教授为通讯作者,清华大学计算机系、智能产业研究院 (AIR)在读博士程思婕是项目负责人及论文一作。

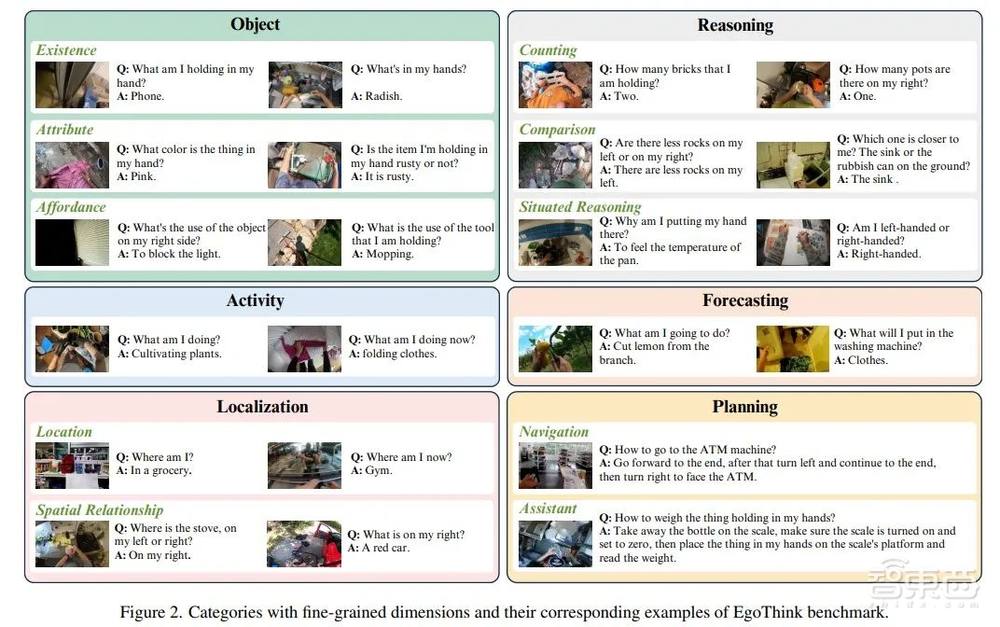
该论文提出了一个针对视觉语言大模型在第一人称视角下思考能力的较为完整的视觉问答评测数据集EgoThink。该数据集共包含700条问答问题,总结了6个核心能力作为评测的维度,并进一步细分为12个维度。
EgoThink来源于Ego4D第一人称视频数据集的采样图片,为保证数据多样性,每条视频最多只采样出两张图片。数据集图片同样经过了严格的筛选,只留下了拥有较好质量和能明显体现第一人称视角思考的图片。该数据集采用人工标注,每种维度都包含至少50条详细标注的问答问题,并且数据来源于多个第一视角的不同现实场景。
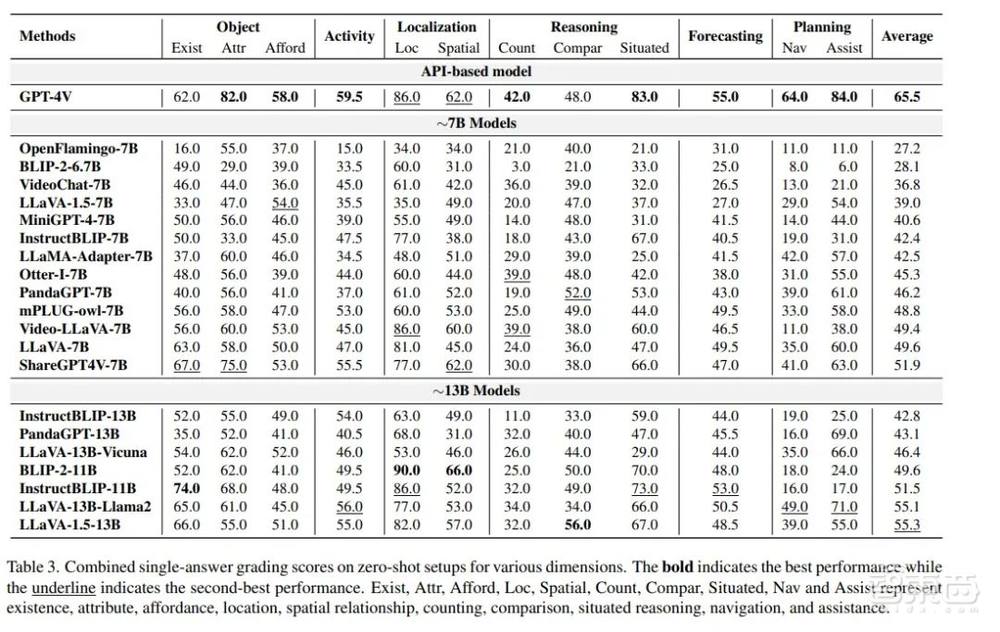
该论文选取了GPT-4作为自动评估模型,用来评估模型输出与人工标注答案的相似度,并根据相似度进行打分,判断模型输出是否准确可靠。论文实验结果显示GPT-4模型与人工评估结果的Pearson相关系数为0.68,证实了GPT-4评估的可靠性。
通过对视觉语言大模型领域18个有代表性的模型进行评测,较为全面地评测了视觉语言大模型领域第一人称视角下的思考能力。实验结果表明,视觉语言大模型在第一人称视角的任务上表现较差,大多数任务的平均评测分数都仅在60分左右;只在预测和计划两个领域表现较好。而在所有模型中,GPT-4V目前仍然是在绝大多数场景下表现更好的模型,但仍离实际应用有较大的距离,在所有任务上的平均分也仅为65.5。
9月5日晚7点,智猩猩邀请到清华大学计算机系、智能产业研究院(AIR)在读博士程思婕参与「智猩猩具身智能前沿讲座」第12讲,主讲《面向具身智能的第一视角多模态模型评价基准EgoThink 》。
讲者
程思婕
清华大学计算机系
智能产业研究院 (AIR)在读博士
程思婕,清华大学计算机系博士生,导师刘洋教授。研究领域为基础模型与具身智能,已在ICLR、ACL、CVPR等人工智能顶级会议发表论文十余篇,曾获国家奖学金、上海市计算机学会优秀硕士学位论文奖、ICML MFM-EAI Workshop杰出论文奖等。
第 38 讲
主 题
《面向具身智能的第一视角多模态模型评价基准EgoThink 》
提 纲
1、基础模型在真实世界中的现状与不足
2、第一人称视角的重要性
3、基于图片评测多模态模型第一视角能力
4、基于视频评测多模态模型第一视角能力5、总结与未来展望
直 播 信 息
直播时间:9月5日19:00
直播地点:智猩猩ROBOT视频号
成果
论文标题
《EgoThink: Evaluating First-Person Perspective Thinking Capability of Vision-Language Models》
论文链接
https://arxiv.org/abs/2311.15596
项目地址
https://adacheng.github.io/EgoThink/
入群申请
针对本次讲座,也组建了学习群。希望入群学习和交流的朋友,可以扫描下方二维码,添加小助手莓莓进行报名。已添加过莓莓的老朋友,可以给莓莓私信,发送“具身智能12”申请入群。

