








在图像生成领域,高分辨率图像的生成一直是一个具有挑战性的工作。Stable Diffusion等强大的预训练扩散模型目前可以生成1024×1024像素的高质量图像。但生成更高分辨率的图像(2K-4K)会遇到不合理的重复物体问题,并且生成时间成倍增加。
为解决这些问题,旷视研究院高级研究员张慎等研究人员提出了一个无需训练的更高分辨率图像生成框架 HiDiffusion。该框架通过动态调整特征图大小来解决重复物体问题,同时改进自注意力机制实现推理速度的提升。相关论文为《HiDiffusion: Unlocking higher-resolution creativity and efficiency in pretrained diffusion models》,已收录于ECCV 2024。

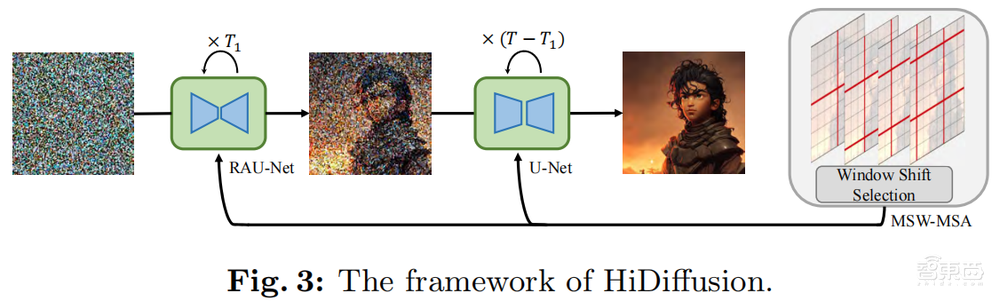
HiDiffusion框架主要由两部分组成:分辨率感知U-Net(RAU-Net)和改进的移动窗口多头自注意力 (MSW-MSA)。
RAU-Net通过动态调整特征图的大小来解决高分辨率图像生成中的对象重复问题。这种调整是为了匹配U-Net深层块中卷积的感受野,从而确保在生成更高分辨率图像时不会发生特征重复而导致不合理的对象重复现象。
MSW-MSA通过使用更大的窗口来减少不必要的计算,并动态移动窗口来优化自注意力机制。这种方法可以更有效地利用计算资源,同时保持对全局信息的捕捉。
HiDiffusion可以集成到各种预训练扩散模型中,将图像生成分辨率扩展到2K-4K,同时推理速度是以前方法的1.5-6倍。大量实验表明,HiDiffusion框架可以解决对象重复和计算量大的问题,并且在更高分辨率图像生成任务上达到最好的性能。
讲者
张慎
第2讲
主题
HiDiffusion:高效、无需训练的更高分辨率图像生成框架
提纲
1、扩散模型目前存在的更高分辨率生成问题
2、RAU-Net解决图像生成中物体重复问题
3、MSW-MSA解决更高分辨率的效率问题
4、更高分辨率的图像生成结果和效率展示
直播信息
直播时间:10月24日10:00
成果
论文标题
《HiDiffusion: Unlocking higher-resolution creativity and efficiency in pretrained diffusion models》
论文链接
https://arxiv.org/abs/2311.17528v2
项目网站
https://hidiffusion.github.io/
如何报名
有讲座直播观看需求的朋友,可以添加小助手“沐可”进行报名。已添加过“沐可”的老朋友,可以给“沐可”私信,发送“通用视觉2402”进行报名。对于通过报名的朋友,之后将邀请入群进行观看和交流。

