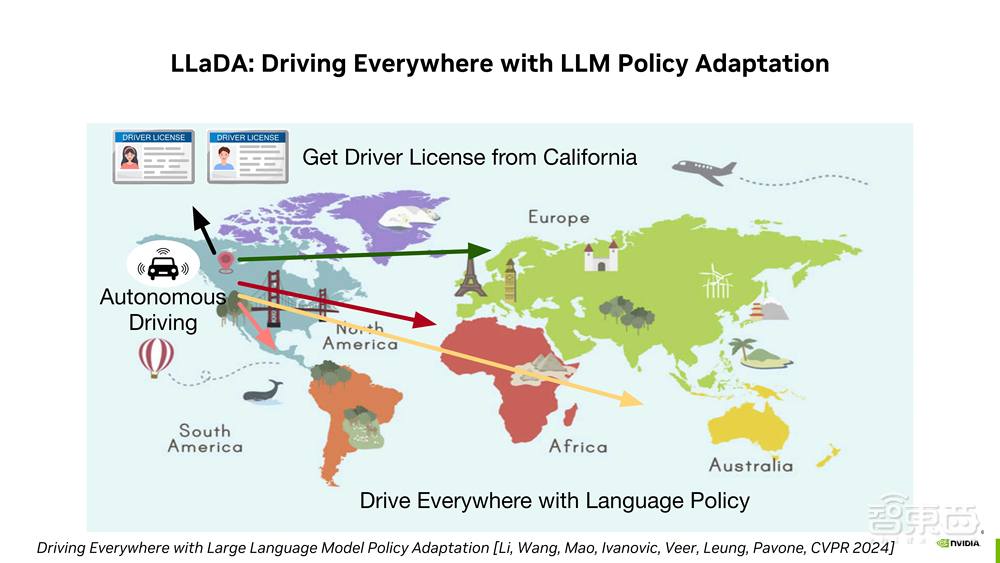
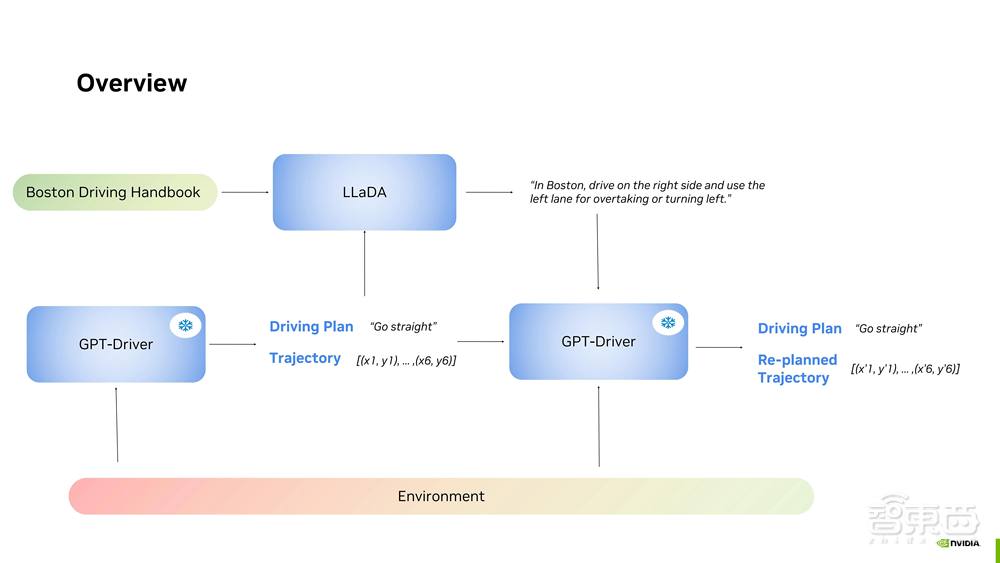
10月22日,由智猩猩联合 NVIDIA 策划推出的「智猩猩公开课 NVIDIA 自动驾驶智能体专场」顺利完结。NVIDIA Research 自动驾驶方向研究科学家李柏依以《探索基于多模态LLM 的自动驾驶智能体》为主题进行了直播讲解,共涉及 LLaDA、TOKEN 以及 Wolf 三篇论文成果。首先,李柏依博士通过视频 demo 介绍了自动驾驶智能体 LLaDA 如何为驾驶员和自动驾驶汽车提供多语言和地区交通规则的实时指导;之后通过对比GPT-Driver、人类驾驶员、LLaDA 的驾驶轨迹,分析了 LLaDA 如何帮助自动驾驶汽车和人类驾驶员调整轨迹策略,使其可以在世界的任何地方驾驶。
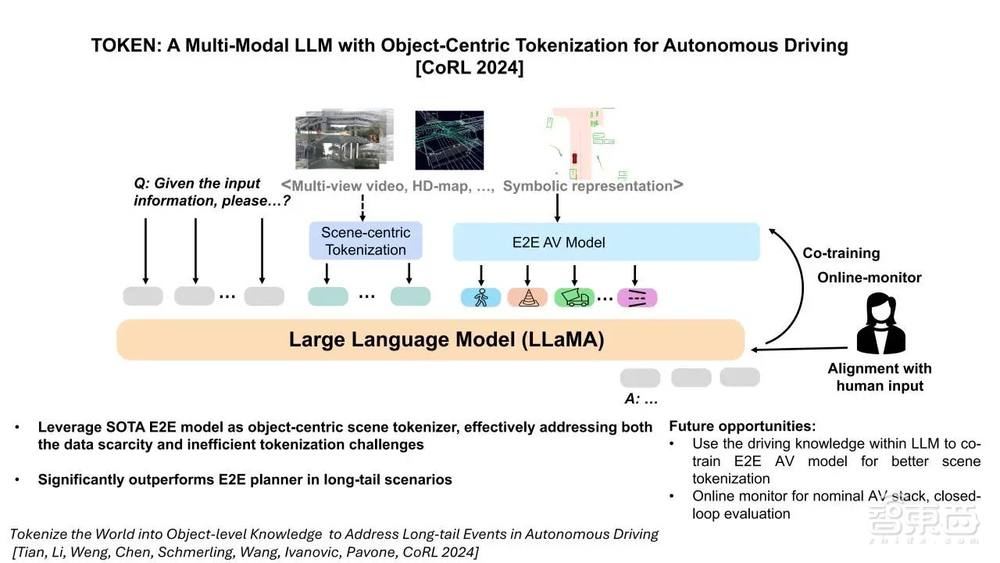
而在复杂交通场景中,车辆之间存在过多交互,这会导致智能体在预测时产生幻觉,从而影响其规划性能。为此,李柏依博士详解了如何基于 TOKEN 分解复杂交通场景,进而提升智能体在长尾事件的规划能力。
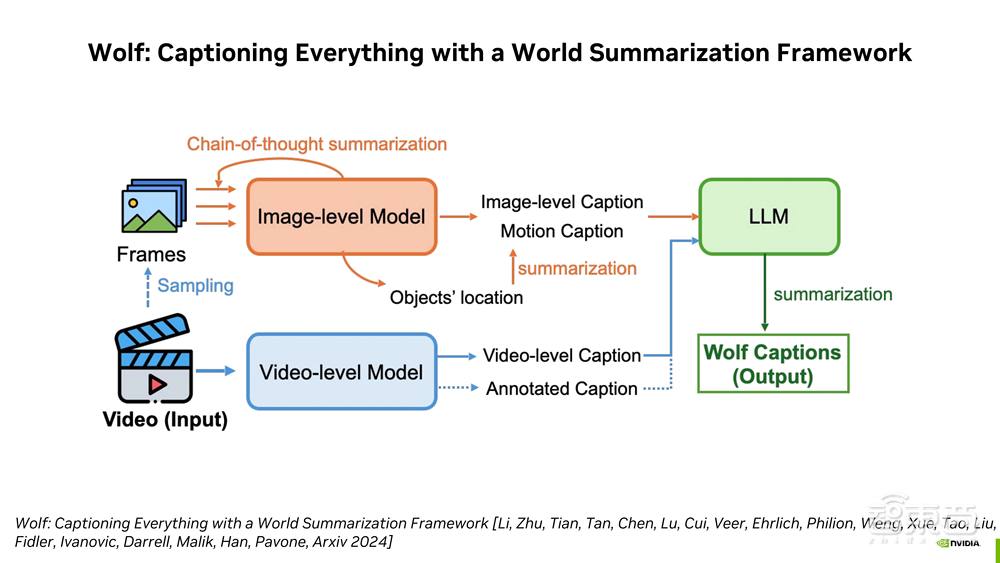
最后,李柏依博士介绍了能够提升智能体场景理解能力的自动化视频字幕生成模型 Wolf,并对比分析了 Wolf 与 GPT-4V、CogAgent、VILA-1.5-13b 等其他模型。目前,此次公开课的课件 PPT 已上传至公众号【智猩猩】,大家可以在后台回复关键词“自动驾驶智能体”进行获取和学习。
完整回放
错过本次直播的朋友,可以观看「智猩猩公开课 NVIDIA 自动驾驶智能体专场」完整回放。
https://wqpoq.xetlk.com/sl/4p6Brv
精选PPT





相关资料
标题:《LLaDA: Driving Everywhere with Large Language Model Policy Adaptation》
链接:
https://arxiv.org/abs/2402.05932
项目地址:
https://boyiliee.github.io/llada/
NVIDIA博客:
https://mp.weixin.qq.com/s/azJU4_OBzE_i8VvKnhDjww
标题:
《Tokenize the World into Object-level Knowledge to Address Long-tail Events in Autonomous Driving》链接:
https://arxiv.org/abs/2407.00959
标题:《Wolf: Captioning Everything with a World Summarization Framework》
https://boyiliee.github.io/llada/
链接:
https://arxiv.org/abs/2407.18908
项目地址:
https://wolfv0.github.io/leaderboard.html









