








智东西(公众号:zhidxcom)
作者 | 陈骏达
编辑 | 漠影
AI时代,存储不仅是数据的栖息之地,更是AI模型训练、落地过程中的坚实底座。
在AI开启的存储行业新周期中,众多厂商已将带宽等性能指标卷至新的高度。然而,这种追求似乎将AI这一复杂应用场景简单地“存储化”了。
实际上,AI对存储的需求远不止于性能这一维度本身,更需要让存储“AI化”,关注整体存储解决方案与AI应用场景的契合度。这一点,也是全球唯一的AI/ML存储基准测试——MLPerf所关注的本质。
MLPerf存储基准测试面向AI/ML用户的痛点,即存储和计算的平衡及两者的有效利用。然而测试中存储架构的多样与存算节点的非标准化,导致性能数据本身的参考价值有所下降。
在性能数据之外,有无另一指标可以更为准确地反映存储系统在AI场景的表现呢?MLPerf存储基准测试要求加速器利用率需达到90%或70%,在这一区间内考核节点所能支持的最大加速卡数,测试其能否尽可能跑满每个客户端的理论带宽,以实现最佳存储性能。
在MLPerf存储基准测试中,由于理论带宽是统一的,因此所有厂商的解决方案均可归一化到网络利用率这一指标上,进行相对客观的评估。网络利用率的提高意味着成本的降低,算力潜能的更充分释放,存储与AI应用场景的契合度也越高。
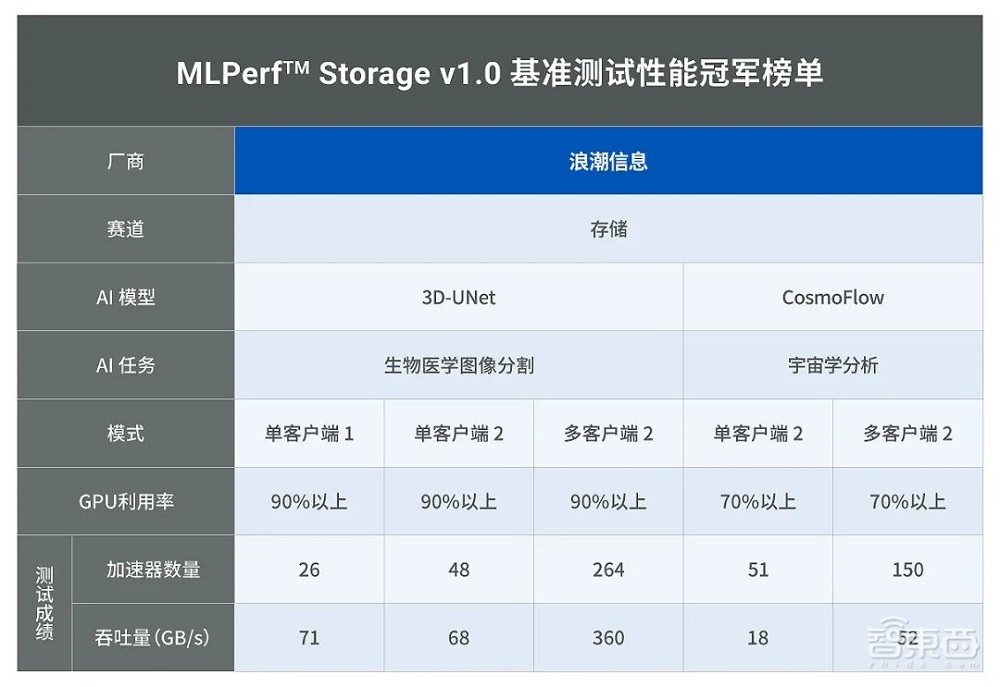
今年9月,新一轮MLPerf存储基准测试成绩发布,其中,中国企业浪潮信息的分布式存储平台AS13000G7,在图像分割模型3D-UNet和天文学模型CosmoFlow共计8项测试中斩获5项最佳成绩。这一平台在网络利用率上展现出20%左右的优势,断层领先。
值得一提的是,本次MLPerf存储基准测试已升级至1.0版本,这一升级提出了哪些新的要求,浪潮信息又是如何凭借其技术积淀与整体解决方案,获得新版测试中的多项最佳成绩的呢?
一、MLPerf测试迎升级,存储助力AI算天文分图像
2018年,图灵奖得主大卫·帕特森(David Patterson)联合斯坦福、哈佛等顶尖学术机构和谷歌、百度等AI行业头部企业,共同发起了MLCommons协会,同年推出首款测试套件MLPerf,目前,该测试是影响力最广的国际AI性能基准评测之一。

▲图灵奖得主大卫·帕特森(图源:ACM)
MLPerf系列测试套件得到学界和产业界的广泛认可。其中,MLPerf存储基准测试是专门用于AI复杂负载下存储系统性能的测试套件,最大程度地模拟了AI任务的真实负载,数据访问的pipeline、架构、软件栈均与实际训练程序无异,已成为AI/ML模型开发者选择存储解决方案的权威参考依据。

▲浪潮信息是MLCommons的创始成员之一(图源:MLCommons官网)
本次MLPerf存储基准测试1.0版本测试吸引了全球13家领先存储厂商和研究机构的参与,测试内容也迎来重大升级,回应了当下复杂AI应用场景对存储提出的新需求。
一方面,存储系统的带宽峰值处理能力迎来新的挑战,测试特别关注了在高性能GPU达到一定使用率的情况下,存储系统能为AI集群提供的整体带宽和单个节点的带宽。
另一方面,测试还强化了对分布式训练的考察,特别关注每个存储节点能够支持的GPU数量,以此来衡量用户在AI存储方面的投资效益。
在本次测试中,浪潮信息使用3台AS13000G7平台搭建分布式存储集群,并配备ICFS自研分布式文件系统,参与了3D-UNet和CosmoFlow两个单项的测试。
作为图像分割领域最具影响力的AI模型,3D-UNet模型的测试中使用了海量的图像类非结构化数据,要求存储平台具备高带宽、低时延的特点,才能保证GPU的高效利用。CosmoFlow宇宙学分析模型参数量仅有10万-20万,如此之小的模型对时延提出了更高的要求。二者都是典型的数据密集型应用。
在3D-UNet多客户端2评测任务中,浪潮信息的存储平台服务于10个客户端264个加速器,集群聚合带宽达到360GB/s,单个存储节点的带宽高达120GB/s。
在宇宙学分析CosmoFlow单客户端2和多客户端2评测任务中,浪潮信息的存储平台分别提供了18 GB/s和52 GB/s的带宽最佳成绩。
二、契合AI使用场景,兼顾性能、效率、韧性
浪潮信息多项最佳成绩的背后,是其面向AI时代,提升存储平台性能、效率和韧性的努力。
性能层面,浪潮自研分布式软件栈中的全新数控分离架构解决了分布式存储数据流在节点间流转的转发问题,减少东西向(节点间)数据转发量80%。这一性能的提升能帮助客户节省大量的存储成本,系统性价比也相应改善。
效率层面,浪潮信息通过多协议数据融合技术,解决了AI应用场景使用多种数据接入协议造成的存储效率问题,最高可节省50%的数据存储空间。
韧性层面,为满足AI业务对持续性的要求,浪潮信息的可靠性主动管理技术、AIOps系统故障预测算法和勒索软件检测技术,有效预防了设备故障和数据安全问题的出现。相关技术对硬盘故障的预测准确率达到98%,对勒索软件的检测漏报率仅有0.029%。
如何将技术整合落地,将技术指标转化为实际效果,最终形成完整且适配AI场景的解决方案,则是真正造福AI行业客户的关键。
浪潮信息与AI场景紧密契合,凭借其产品场景化定制能力与成熟的AI场景解决方案能力,打造出了真正贴合AI需求的存储产品,为AI场景构建坚实的数据支撑平台。
以本次测试中3D-UNet加速器H多客户端下的测试结果为例,浪潮信息的多路并发透传技术有效减少了I/O操作中频繁的上下文切换,降低单次I/O时延50%。本次测试的3D-UNet场景中,3节点存储支撑了1430个高并发读线程,计算节点网络利用率达到了72%。
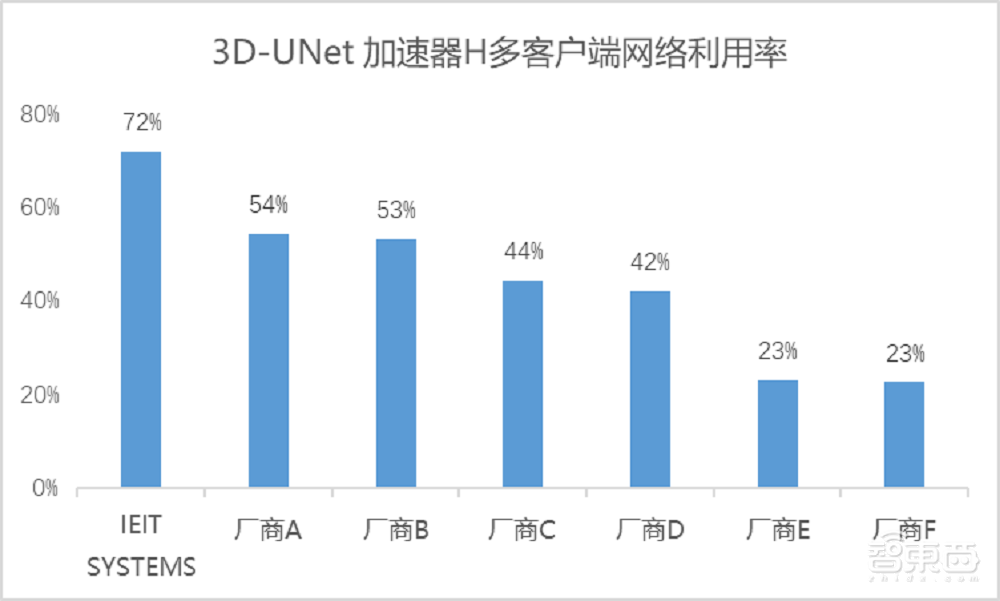
网络利用率的提高有效降低了网络资源的浪费。在客户端配置双网卡情况下,部分参赛解决方案仅有50%的网络利用率,意味着整套方案实质上浪费了近乎一整张网卡资源,大大增加了总体成本。
若在大模型训练的万卡集群下,低网络利用率造成的网卡资源的浪费可能高达数千万级别,更不必说设备扩容所引发的算力利用率下降、连接线增加、运维复杂度提升等连锁成本效应。
对于本就成本高昂的AI基础设施而言,任何可以削减的开支都显得尤为关键。浪潮信息存储解决方案在网络利用率上的明显优势,证明了相关方案对AI场景的高度适配。
在实践中,浪潮信息的存储解决方案已经在互联网企业大模型训练推理场景、大型AI算力中心与某国家重点实验室中落地。
例如,在大模型场景训练中,浪潮信息通过增加全闪存储帮助客户实现效率提升,将断电续训时间降低到分钟级别。新增20台全闪存储提升的效率,相当于新增了10多台GPU服务器,从投资角度上来看,每100万存储投资相当于300万的GPU服务器投资。
而针对大模型推理场景中多文件协议特点,浪潮信息的融合存储方案让客户节省了协议转化的时间,使得数据汇集准备时间节省30%,存储空间也大幅节省。
结语:生成式AI步入下半场,存储成AI向实关键
据工信部测算,到2035年,中国生成式AI的市场规模将突破30万亿元,制造业、医疗健康、电信行业和零售业对生成式AI技术的采用率迎来较快增长。
2024年,生成式AI正以前所未有的速度走入千行百业。AI行业已经由百模大战时期的“卷模型”,转变为“卷场景、卷应用”,或将迎来下半场的角逐。
在AI向实发展的进程中,数据是连接物理世界与数字世界的重要桥梁,而存储作为数据的载体,持续在AI落地的实践中发挥关键作用。
