








现有的多模态大模型(MLLM)通常将预训练的视觉编码器与大语言模型结合来实现,即模块化MLLM。最近新兴的Chameleon、EVE等原生MLLM,将视觉感知和多模态理解直接集成到LLM中,能够更方便地通过现有工具进行部署,且具备更高的推理效率。
然而,由于原生MLLM缺乏视觉能力,但视觉预训练过程中语言基座能力常常出现灾难性遗忘问题,这导致现有原生MLLM的性能仍显著低于模块化MLLM。
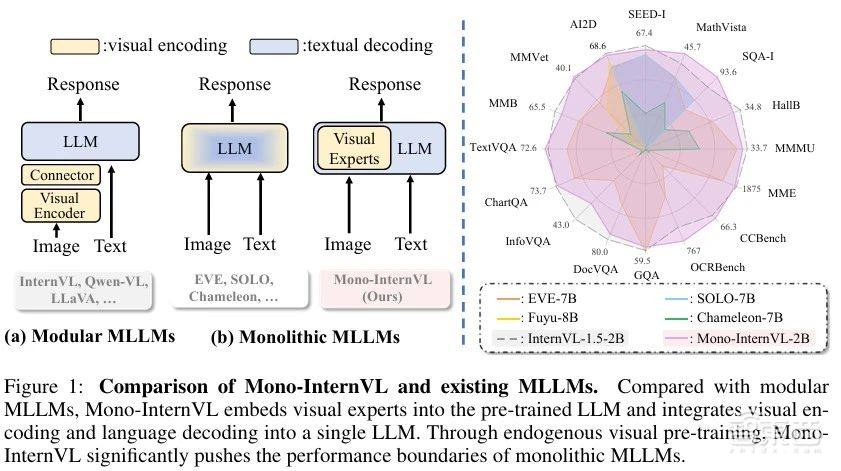
为此,上海人工智能实验室通用视觉团队(OpenGVLab)联合清华大学、上海交通大学等提出了全新的原生多模态大模型Mono-InternVL。该模型采用增量预训练方法,解决了此前原生MLLM中的灾难性遗忘问题。与非原生模型相比,Mono-InternVL首个单词延迟能够降低67%,且在多个评测数据集上均达到了SOTA水准。

相比于现有多模态大模型,Mono-InternVL无需额外的视觉编码器,通过内嵌视觉专家打通了一条从大语言模型到原生多模态模型扩展的新路径,且2B模型多模态能力优于7B参数的现有原生多模态模型,多个指标超越了InternVL1.5。
Mono-InternVL兼具了视觉灵活性和部署高效性,支持高达2M像素输入的动态图像分辨率,在原生多模态架构中感知精度最高。相比于InternVL1.5,在部署框架上首个单词延迟最多降低67%,整体吞吐量提高31%。
11月7日19点,智猩猩邀请到论文一作、上海 AI Lab OpenGVLab 博士后研究员罗根参与「智猩猩通用视觉讲座」03讲,主讲《Mono-InternVL: 突破原生多模态大模型性能瓶颈》。
讲者
罗根,上海 AI Lab OpenGVLab 博士后研究员
主 题
《Mono-InternVL: 突破原生多模态大模型性能瓶颈》
提 纲
1、模块化大模型与原生大模型对比分析
2、原生多模态大模型Mono-InternVL解析
3、原生MLLM面临的的灾难性遗忘问题
4、增量内生视觉预训练(EViP)方法
5、实验比较及模型性能展示
直 播 信 息
直播时间:11月7日19:00
成果
论文标题
《Mono-InternVL: Pushing the Boundaries of Monolithic Multimodal Large Language Models with Endogenous Visual Pre-training》
论文链接
https://arxiv.org/abs/2410.08202
项目地址
https://internvl.github.io/blog/2024-10-10-Mono-InternVL/
如何报名
有讲座直播观看需求的朋友,可以添加小助手“沐可”进行报名。已添加过“沐可”的老朋友,可以给“沐可”私信,发送“通用视觉03”进行报名。对于通过报名的朋友,之后将邀请入群进行观看和交流。

