








视觉导航是具身智能体的基础技能,可以极大拓宽智能体的行动边界和任务边界。其中,基于开放域语言指令的视觉语言导航是目前最具挑战及应用价值,也是最难以进行现实部署的具身导航任务之一。
导航智能体需要理解从单个物体、到物体间关系、再到不同房间的空间布局,并借由开放域指令进行导航规划。这要求环境表征能从不同粒度上与语言语义对齐;且在未知场景的导航需要实时动态地更新环境表征,传统的基于低噪声点云的3D Visual Grounding等方法难以奏效,而2D基础模型难以理解大范围的三维环境布局。
为此,中科院计算所和新加坡国立大学等研究人员提出了基于网格记忆地图和三维特征场等一系列方法,包括动态构建地图表征方法GridMM,基于特征场的导航前瞻探索策略HNR,高性能单目视觉语言导航Sim-to-Real方案以及三维基础模型3D-Language特征场。通过这些方法来解决视觉语言导航等具身任务中的三维环境表征和理解问题。
GridMM是动态构建与语言指令细粒度对齐的环境网格地图的方法。该方法通过映射智能体水平观察的细粒度视觉特征到俯视角网格地图,并在每个网格区域内与导航指令做语义关联聚合。与GridMM相关的论文成果收录于ICCV 2023,并成为CVPR 2023 Embodied AI 视觉语言导航RxR竞赛冠军方案。

通过GridMM能够实现网格记忆地图的动态增长,并随导航过程同步更新,以支持全局的导航规划。接着,相关团队又提出了第一个可用于视觉语言导航的可泛化特征场HNR。与HNR相关的论文成果收录于CVPR 2024 Highlight。

HNR通过将智能体历史观察的视觉特征映射进三维空间,并利用体积渲染来解码与CLIP语义空间对齐的新视角表征。HNR对若干可导航的候选点预测其周围的新视角表征,构建导航的未来路径树以支持其前瞻探索。这一策略大幅提升了智能体的导航规划表现。
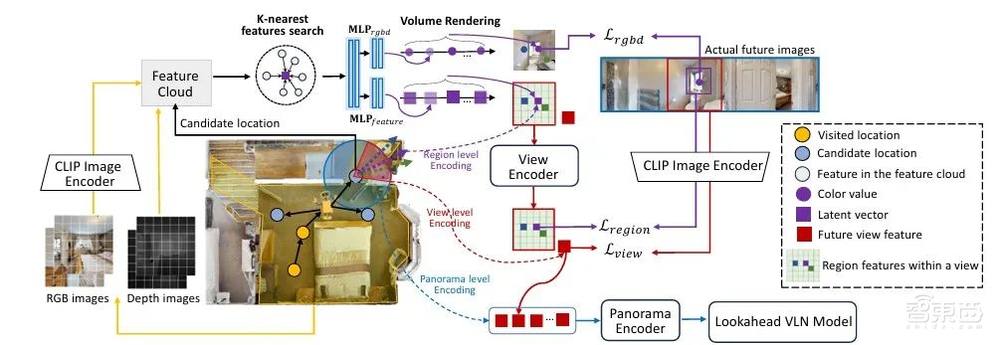
如何将仿真环境中的训练成果迁移到真实环境也是具身导航领域一项重要的研究。不同于仿真环境中惯用的全景RGB-D设置,现实环境中的绝大多数机器人仅配备单目相机,这极大限制了视觉语言导航模型的实机部署。因而VLN-3DFF提出使用3D特征场构建的高性能单目视觉语言导航Sim-to-Real方案,赋予单目机器人全景感知能力,即用语义地图预测全景范围的可导航候选点。该方案将单目视觉语言导航模型的最佳导航成功率提升了6%以上。与VLN-3DFF相关的论文成果收录于CoRL 2024。

此外,先前的可泛化特征场通常仅由2D基础模型进行语义对齐,或仅使用有限的物体类别标注做语义分割监督。这极大限制了特征场模型的大范围物体关系和空间布局理解。3D-LF是第一个通过大规模3D-Language数据训练层次化特征场的方法,实现了特征场模型从物体、关系、到环境布局的多层级语义表征和理解。该方法能大幅提升视觉语言导航和零样本物体导航等任务的性能表现,验证了3D语言特征场在具身任务的应用价值。

11月21日晚7点,智猩猩邀请到上述四篇成果的论文一作、新加坡国立大学计算机学院博士生王子涵参与「智猩猩具身智能前沿讲座」第15讲,以《具身导航中的三维场景理解》为主题带来直播讲解。
讲者
王子涵
新加坡国立大学计算机学院博士生
新加坡国立大学计算机学院博士生,导师为Gim Hee Lee教授。硕士师从中科院计算所蒋树强研究员。研究领域为具身导航与用于具身智能的三维基础模型,相关研究发表于CVPR,ICCV,CoRL等计算机视觉与机器人顶会。曾获CVPR 2023 Embodied AI 视觉语言导航RxR竞赛冠军。
第 15 讲
主 题
《具身导航中的三维场景理解》
提 纲
1、具身导航的核心难点与基础方法介绍
2、具身导航中的动态构建地图表征方法GridMM
3、基于特征场的导航前瞻探索策略HNR
4、视觉语言导航的Sim-to-Real部署
5、利用3D语言数据训练层次化特征场提升机器人导航能力
直 播 信 息
直播时间:11月21日19:00
成果
论文成果1
标题:《GridMM: Grid Memory Map for Vision-and-Language Navigation》
链接:https://arxiv.org/abs/2307.12907
收录情况:ICCV 2023,CVPR 2023 Embodied AI 视觉语言导航RxR竞赛冠军方案
论文成果2
标题:《Lookahead Exploration with Neural Radiance Representation for Continuous Vision-Language Navigation》
链接:https://arxiv.org/abs/2307.12907
收录情况:CVPR 2024 Highlight
论文成果3
标题:《Sim-to-Real Transfer via 3D Feature Fields for Vision-and-Language Navigation》
链接:https://arxiv.org/abs/2406.09798
收录情况:CoRL 2024
论文成果4
标题:《Generalizable 3D-Language Feature Fields for Embodied Tasks》
如何报名
有讲座直播观看需求的朋友,可以添加小助手“莓莓”进行报名。已添加过“莓莓”的老朋友,可以给“莓莓”私信,发送“具身智能15”进行报名。对于通过报名的朋友,之后将邀请入群进行观看和交流。

