








「智猩猩AI新青年讲座」由智猩猩出品,致力于邀请青年学者,主讲他们在生成式AI、LLM、AI Agent、CV等人工智能领域的最新重要研究成果。
AI新青年是加速人工智能前沿研究的新生力量。AI新青年的视频讲解和直播答疑,将可以帮助大家增进对人工智能前沿研究的理解,相应领域的专业知识也能够得以积累加深。同时,通过与AI新青年的直接交流,大家在AI学习和应用AI的过程中遇到的问题,也能够尽快解决。
「智猩猩AI新青年讲座」现已完结254讲,错过往期讲座直播的朋友,可以点击文章底部 “ 阅读原文 ” 进行回看!
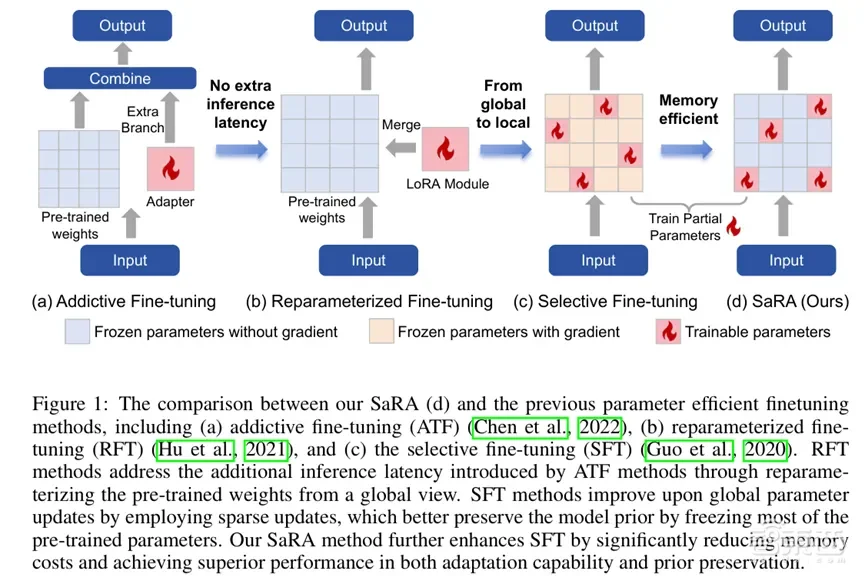
近年来扩散模型的快速发展,图像生成、视频生成、3D生成等任务取得了重大进展。然而一个核心问题也随之浮现:如何有效且高效地微调预训练的基础扩散模型,并将其应用于新任务。现有的微调方法可分为附加型微调方法(AFT)、重参数化微调方法(RFT)以及选择性微调方法(SFT)。AFT和RFT方法都需要针对不同模型进行特定设计,以及根据具体任务调整隐藏维度或秩值。而SFT方法不仅引入了较高的延迟,还对参数选择的超参数敏感,在效果和训练效率方面表现不佳。
针对上述问题,上海交通大学在读博士胡腾联合腾讯优图实验室研究人员提出了一种新颖的高效微调方法SaRA(Sparse Low-Rank Adaptation),其专门为预训练扩散模型设计,现已开源。该方法是基于渐进稀疏低秩适应的高效微调,利用基于核范数的低秩损失来有效防止模型过拟合,同时引入渐进训练策略,以充分利用无效参数,从而使模型在学习新知识的同时不影响其原有的泛化能力。

SaRA 的显著特点是其引入了非结构化反向传播策略,这使得它在对扩散模型微调过程中显著减少了内存消耗。通过将可训练参数分离为叶节点,使得模型的所有参数梯度能够流入少量的可训练参数中,避免了为整个参数矩阵保留梯度的需求,这大大简化了预训练模型微调的复杂性和工作量。
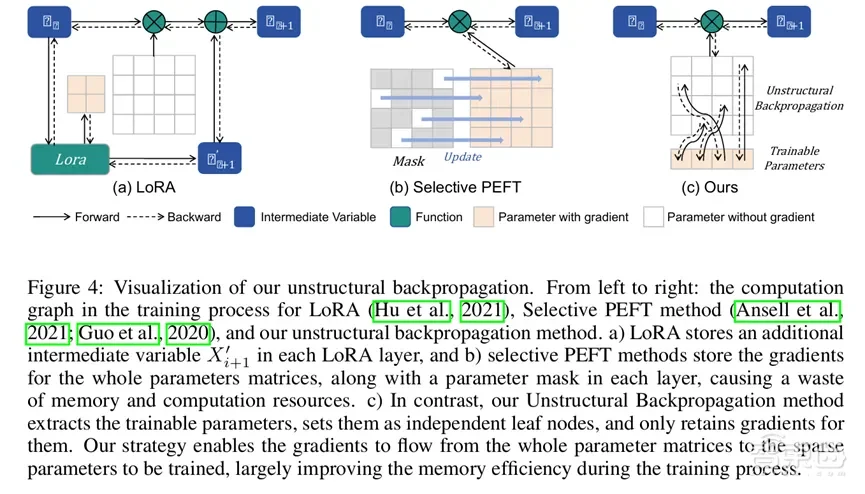
SaRA不仅实现了低内存消耗,还实现了很好的代码集成,只需要修改一行代码即可实现高效的扩散模型微调。结果表明,SaRA相较于其他微调方法能够更好地学习到下游任务的知识,并最大化维护模型的先验信息,其高效性、简便性和实用性,不仅解决了如何高效利用预训练扩散模型中无效参数的问题,还为未来在各种下游任务中应用扩散模型提供了新的可能性。

11月27日19点,智猩猩邀请到论文一作、上海交通大学在读博士胡腾参与「智猩猩AI新青年讲座」255讲,主讲《扩散模型高效微调方法SaRA与显存占用优化》。
主讲人
胡腾
上海交通大学在读博士
师从易冉助理教授,从事图像、视频等可视媒体的内容生成研究,主要研究图像、视频可控生成。 入选首届《中国电子学会-腾讯博士生科研激励计划》。目前以第一作者、学生第一作者、共同第一作者在CCF A类会议或期刊上发表高水平论文8篇,共计发表10篇高水平论文。
第255讲
主 题
扩散模型高效微调方法SaRA与显存占用优化
提 纲
1、现有扩散模型微调方法及局限性
2、扩散模型中无效参数分析及潜在有效性
3、基于无效参数重用的微调方法
4、通过非结构化反向传播降低微调显存
5、基础模型提升与下游任务微调
直 播 信 息
直播时间:11月27日19:00
直播地点:智猩猩知识店铺
成果
论文标题
《SaRA: High-Efficient Diffusion Model Fine-tuning with Progressive Sparse Low-rank Adaptation》
论文链接
https://arxiv.org/pdf/2409.06633
项目网站
https://sjtuplayer.github.io/projects/SaRA/
报名方式
对本次讲座感兴趣朋友,可以扫描下方二维码,添加小助手米娅进行报名。已添加过米娅的老朋友,可以给米娅私信,发送“ANY255”即可报名。
我们会为审核通过的朋友推送直播链接。同时,本次讲座也组建了学习群,直播开始前会邀请审核通过的相关朋友入群交流。

