








智东西(公众号:zhidxcom)
作者 | 汪越
编辑 | 漠影
智东西12月3日报道,今天,腾讯混元大模型正式上线视频生成能力,这是在腾讯文生文、文生图、3D生成之后的最新技术进展。
据腾讯混元多模态生成技术负责人凯撒现场介绍,此次更新中,HunYuan-Video模型经历了四项核心改进:
1、引入超大规模数据处理系统,提升视频画质;
2、采用多模态大语言模型(MLLM),优化文本与图像的对齐;
3、使用130亿参数的全注意力机制(DIT)和双模态ScalingLaw,增强时空建模与动态表现;
4、采用自研3D VAE架构,提升图像和视频的重建能力。
与此同时,腾讯宣布将这款拥有130亿参数规模的视频生成模型开源。目前,该模型已在APP与Web端发布,其标准模式下的视频生成大约需要120秒完成。
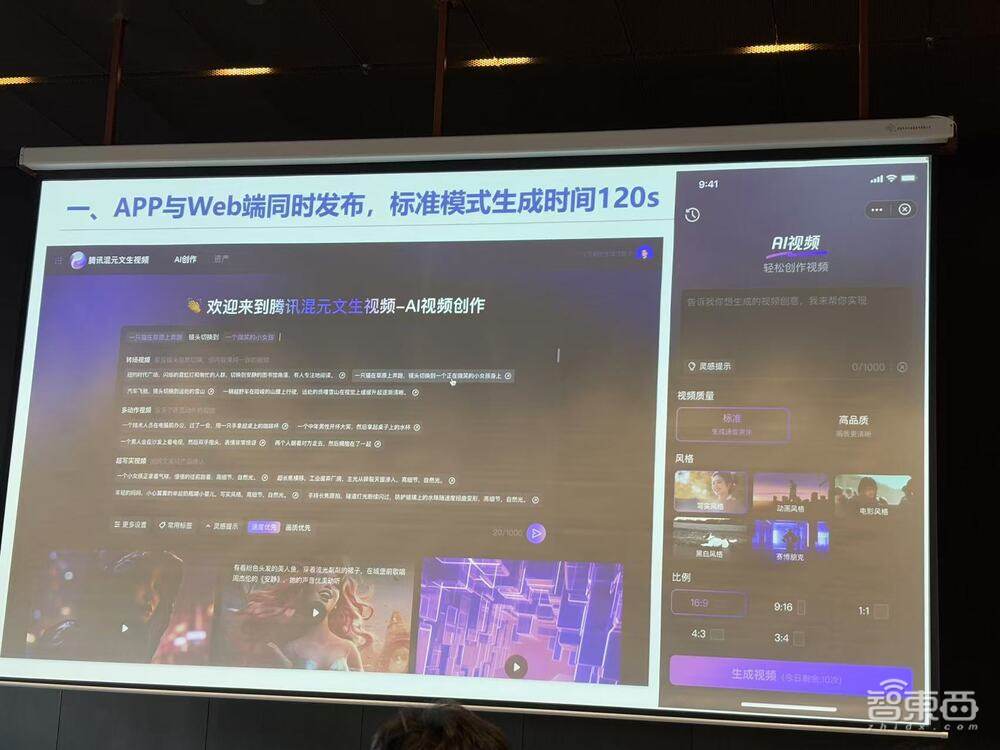
一、腾讯HunYuan-Video模型技术升级与应用拓展
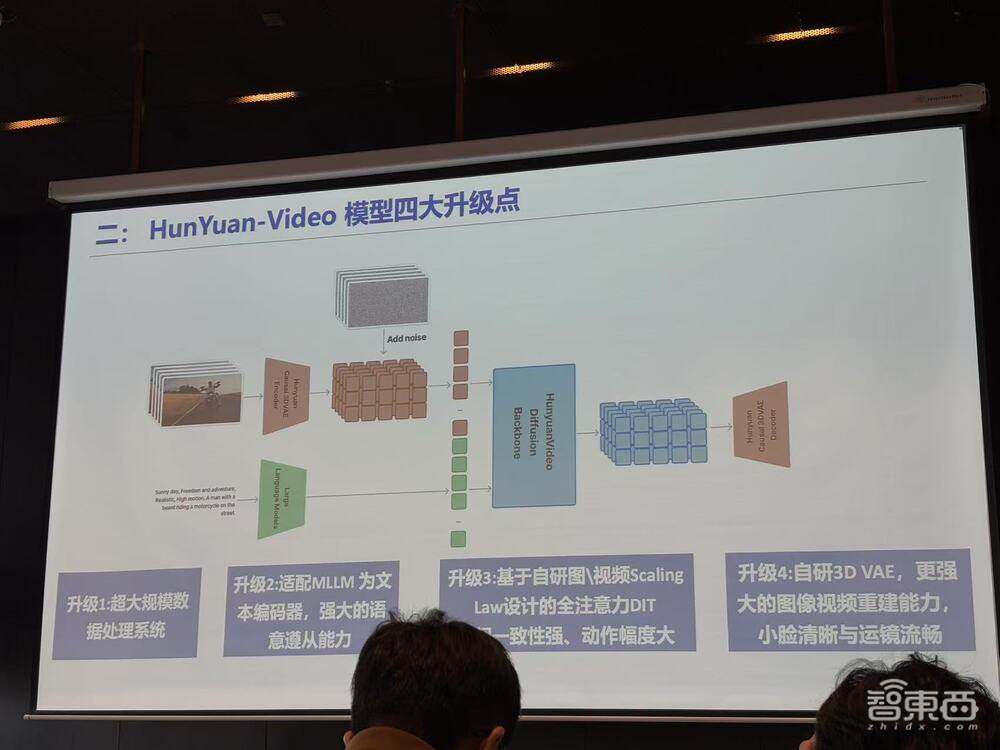
腾讯对HunYuan-Video模型进行了四项技术升级,涵盖了数据处理系统、文本编码、算力优化等多个方面,提升了视频生成的质量与可控性。此外,腾讯还通过微调、应用拓展及开源等措施进一步强化了模型的实际应用能力。
1、四项关键技术升级
首先,模型采用了一个超大规模的数据处理系统,能够混合处理图像与视频数据。该系统包括文字检测、转景检测、美学打分、动作检测、准确度检测等多个维度的功能,进一步提升视频画质。
其次,模型引入了多模态大语言模型(Decoder-only MLLM)作为文本编码器,提升了复杂文本的理解能力,同时支持多语言理解。这一升级使得文本与图像之间的对齐性得到了加强,能够根据用户提供的提示词精确生成符合要求的视频内容。

另外,模型架构使用了130亿参数的全注意力机制(DIT)和双模态ScalingLaw,能够在视频生成中有效利用算力和数据资源,增强时空建模能力,并优化视频生成过程中的动态表现。此架构支持原生转场,可实现了多个镜头间的自然切换,并保持主体一致性。

最后,HunYuan-Video采用了自研的3D VAE架构,以提升图像和视频重建的能力,特别在小人脸和大幅运动场景下表现更加流畅。

2、六大微调领域强化定向能力
在预训练之后,腾讯混元大模型目前正在进行微调(SFT)工作,进一步增强其视频生成的定向能力。HunYuan-Video在六个关键方面进行了专项微调,包括画质优化、高动态效果、艺术镜头、手写文本、转场效果以及连续动作的生成,其中一些调整仍在进行中。
3、Recaption模型与两种生成模式
此外,HunYuan-Video还推出了Recaption模型,提供了两种生成模式:常规模式和导演模式。
常规模式侧重于简化用户输入的文本,强化自我修正功能,适合专业用户进行精细操作;而导演模式则侧重于提升画面质感,强化镜头运用、光影设计和构图美学等方面的描述,适合非专业用户使用。

4、性能评估与同行对比
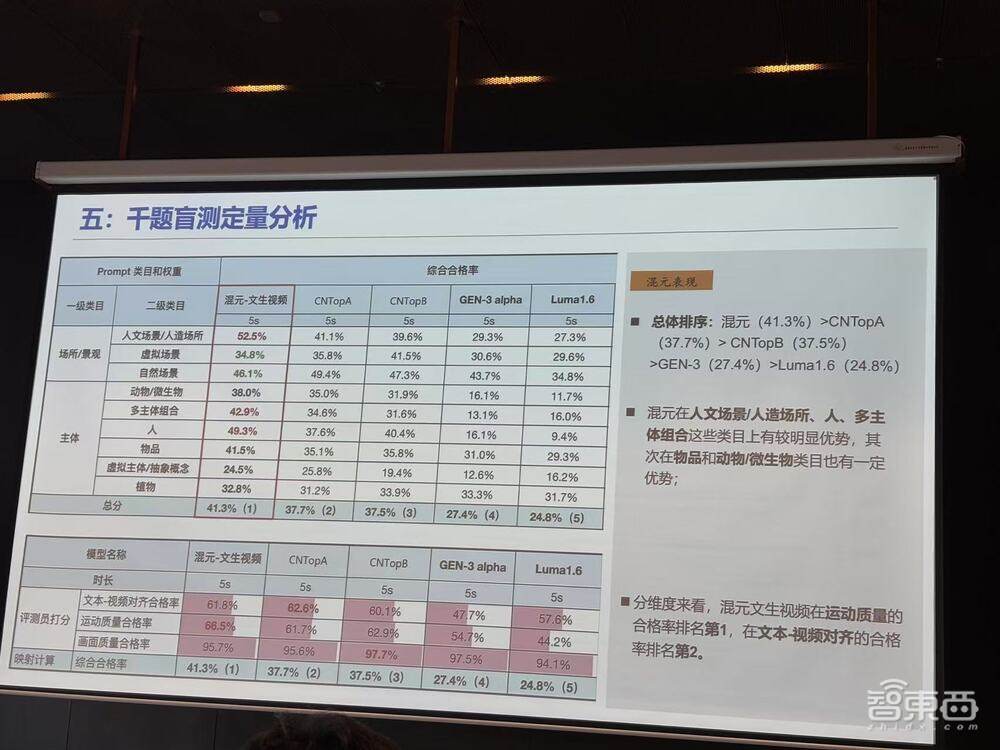
据了解,混元大模型经过了千题盲测的定量分析,在总体排序中以41.3%的表现领先,优于其他模型如CNTOpA(37.7%)、CNTopB(37.5%)和GEN-3(27.4%)。
在特定场景类别中,混元表现尤为突出,特别是在处理人文场景、人工场所以及多主体组合场景时,其生成效果优于其他模型。在物品和动物/微生物类目中,混元也具有一定的优势,而在虚拟场景和自然场景的生成效果相对较弱。
从维度来看,混元运动质量的合格率排名第一,文本与视频的对齐合格率位居第二。但从数据中可以看出,行业里的这些模型总体成功率都仍然较低,视频生成的内容仍存在一定的优化空间。
5、视频配音、配乐与数字人技术
除了基础的视频生成能力外,腾讯还拓展了HunYuan-Video的应用功能,推出了视频配音与配乐功能,能够为生成的视频提供音效与背景音乐,进一步提升视频的完整性和表现。
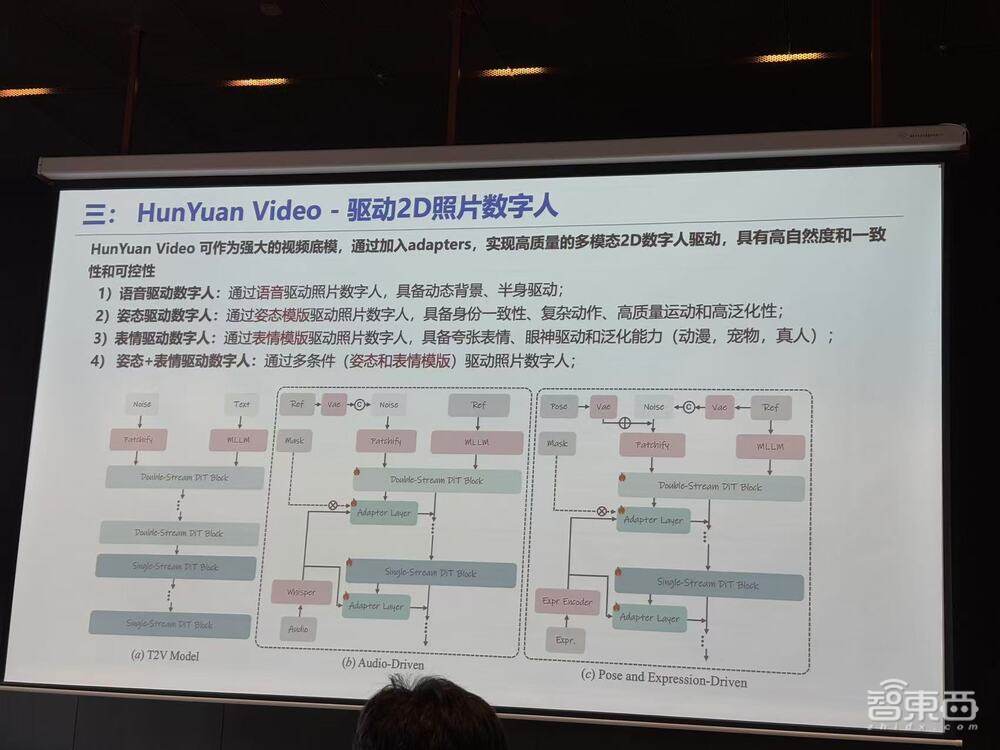
此外,腾讯还推出了驱动2D照片数字人的技术,支持通过语音、姿态和表情等多种驱动方式控制照片数字人的动态表现,增强了生成内容的自然度、一致性和可控性。
6、开源发布与生态支持
目前,腾讯宣布开源该视频生成大模型已在Hugging Face平台及Github上发布,包含模型权重、推理代码、模型算法等完整模型,可供企业与个人开发者免费使用和开发生态插件。
腾讯混元视频生成开源项目相关链接如下:
官网:https://aivideo.hunyuan.tencent.com
代码:https://github.com/Tencent/HunyuanVideo
模型:https://huggingface.co/tencent/HunyuanVideo
技术报告:https://github.com/Tencent/HunyuanVideo/blob/main/assets/hunyuanvideo.pdf
二、腾讯混元的下一步:提高视频分辨率和生成速度
腾讯混元多模态生成技术负责人凯撒谈道,文生视频与图像生成在技术上有着密切联系。虽然视频生成建立在图像生成的基础上,但它对动态时序信息和场景变化处理能力提出了更高的要求。
视频生成的一个核心挑战是在快速变化的场景中维持图像的连贯性和一致性。虽然图像生成技术已经取得了显著的进步,但将其扩展至动态视频生成仍面临许多技术障碍。未来,图像与视频生成可能会趋向一体化发展,但这需要在多个技术领域取得突破。
此外,视频主体的一致性问题也是关键所在。当前的技术能够在较短时间(约5秒)内较好地保持一致性,但随着视频长度增加,尤其是在镜头切换时,保持主体一致性就会变得困难,这在行业内是一个普遍存在的难题。
关于视频分辨率,目前大多数视频生成技术能够达到720P。腾讯混元计划逐步提升这一标准,首先达到1080P,最终目标是4K乃至8K,以增强视觉体验中的清晰度与细节表现力。
算力的提升对于提高视频分辨率及加快生成速度至关重要。腾讯混元正在探索两条主要路径:一是通过改进算法来直接提升分辨率;二是利用放大算法来提高视频质量。这两方面的工作都在积极进行中。
目前,腾讯混元已经开始内部测试其视频生成功能,并计划逐步推向市场应用。然而,要实现大规模商业化还需经过一定的时间以及市场的验证。
结语:AI视频生成领域竞争加剧
随着腾讯混元大模型视频生成能力的发布,AI视频生成领域的竞争格局进一步加剧。除了腾讯,国外AI视频生成平台如Runway、Luma、Pika,以及国内的快手可灵、字节即梦、智谱清影等也在争夺市场份额,形成了多方竞争的态势。
开源已成为腾讯混元大模型的一个战略选择。从年初以来,腾讯混元系列模型的开源速度不断加快。此前,腾讯混元已经开源了旗下文生文、文生图和3D生成大模型。至此,腾讯混元系列大模型已实现全面开源。
