








近年来,生成式人工智能技术的迅猛发展使得高质量的短时舞蹈生成成为可能。然而,实际应用中的舞蹈表演通常远超这一时长,社交舞一般持续3至5分钟,舞蹈剧甚至可能长达15分钟以上。这使得现有的舞蹈生成方法在处理长序列舞蹈时面临诸多挑战,特别是在生成高质量的长序列舞蹈动作方面,现有技术尚难满足实际需求。因此,如何在保证动作细节的同时,捕捉舞蹈的全局结构并生成流畅且富有表现力的长时序列舞蹈,成为一个待解决的核心问题。
针对上述问题,清华大学在读博士李镕辉提出了Lodge,一个能够在给定音乐条件下生成极长舞蹈序列的网络。Lodge采用了两阶段粗到细的扩散架构,并引入了一种具有显著表现力的特征舞蹈原语,作为连接两个扩散模型的中间表示。这一设计有效平衡了全局编舞模式与局部动作的质量和表现力,使得极长的舞蹈序列生成得以并行化完成。论文已收录于CVPR 2024!

Lodge通过两阶段扩散实现长舞蹈序列生成。全局扩散阶段利用Transformer网络从音乐中提取节奏和结构信息,生成稀疏的特征舞蹈原语(8帧关键动作),捕捉音乐与舞蹈的全局编排模式。这些原语表达性强、语义丰富,为局部扩散提供了关键指导。在局部扩散阶段,框架以舞蹈原语为引导,并行生成细节丰富的短舞蹈片段,确保片段的连续性与表现力。其中,硬提示原语用于片段连接,软提示原语提升动作质量与多样性,最终生成兼具全局编排和局部细节的高质量长舞蹈序列。
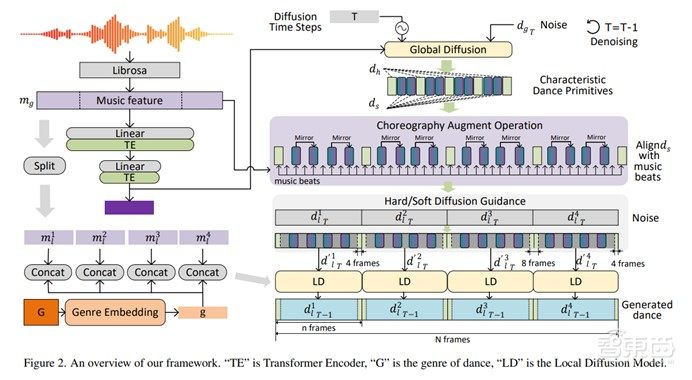
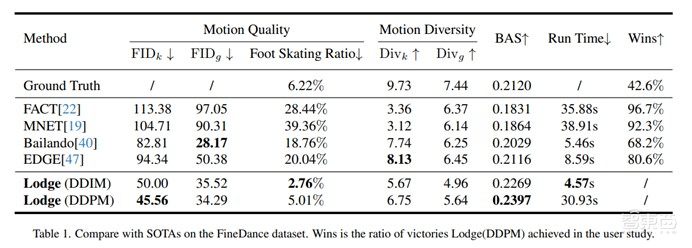
与此同时,Lodge在FineDance和AIST++数据集上进行实验,其中FineDance以152.3秒的平均每段舞蹈时长远高于AIST++的13.3秒,因此成为主要的训练和测试数据集。实验结果表明,Lodge在用户研究和标准指标的广泛评估中取得了最先进结果。生成样本表明,Lodge能够并行生成符合编舞规则的舞蹈,同时保持局部细节和物理真实感。由于Lodge的并行生成架构,即使生成更长的舞蹈序列,推理时间也不会显著增大。

12月17日19点,智猩猩邀请到论文一作、清华大学在读博士李镕辉参与「智猩猩AI新青年讲座」257讲,主讲《音乐驱动的高质量长序列舞蹈生成》。
讲者
李镕辉
清华大学在读博士生
师从李秀教授,目前清华大学博士三年级在读。研究方向包括人体动作建模与生成,AI编舞,数字人交互,AIGC等。在CVPR、ICCV、NeurIPS、AAAI等会议及期刊上发表多篇论文。个人主页:https://li-ronghui.github.io/。
第257讲
主 题
音乐驱动的高质量长序列舞蹈生成
提 纲
1.音乐驱动舞蹈生成背景介绍
2.高质量细粒度的全身舞蹈动作生成
3.高效生成极长舞蹈序列
4.实验效果展示
直 播 信 息
直播时间:12月17日19:00
成果
论文标题
《Lodge: A Coarse to Fine Diffusion Network for Long Dance Generation Guided by the Characteristic Dance Primitives》
论文链接
https://arxiv.org/pdf/2403.10518
项目网站
https://li-ronghui.github.io/lodge
报名方式
对本次讲座感兴趣朋友,可以扫描下方二维码,添加小助手米娅进行报名。已添加过米娅的老朋友,可以给米娅私信,发送“ANY257”即可报名。
我们会为审核通过的朋友推送直播链接。同时,本次讲座也组建了学习群,直播开始前会邀请审核通过的相关朋友入群交流。

