








近年来,生成式AI技术的迅猛发展让AI在创意领域的应用不断突破,特别是在动画制作方面,潜力得到了极大地释放。然而,以往的方法只能在特定运动领域内工作,往往局限于生成单一风格的内容,缺乏对动画细节的控制手段,从而限制了其在实际应用中的广泛使用。
针对上述问题,东京大学在读博士牛慕尧联合腾讯AI Lab研究人员提出了MOFA-Video,一个面向动画生成的创新性可控AI模型。通过将静态图像转化为生动的动画视频,MOFA-Video不仅能够生成逼真且富有表现力的动画,还提供对生成内容的精确控制,赋予创作者前所未有的自由与控制力。MOFA-Video不仅是技术上的飞跃,更是创意表达方式的突破。代码现已开源!

MOFA-Video采用了先进的生成运动场适配器(MOFA-Adapter),在精细控制视频生成过程中的动作和细节方面表现卓越。通过稀疏控制信号生成技术,让用户能够利用少量输入数据(如轨迹、面部关键点或音频信号)来生成精确且自然的动画。其核心的MOFA-Adapter设计,将稀疏控制信号转化为密集的运动场,保证了生成视频的自然流畅和视觉一致性。
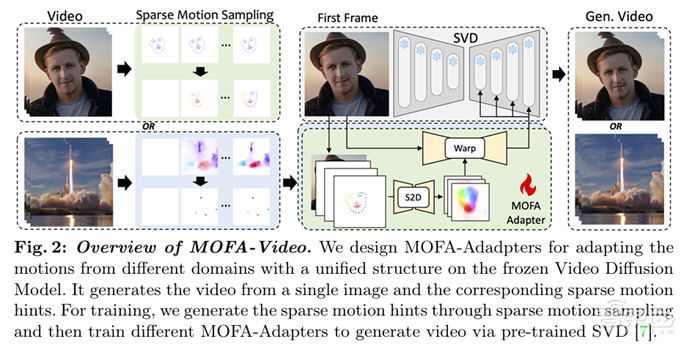
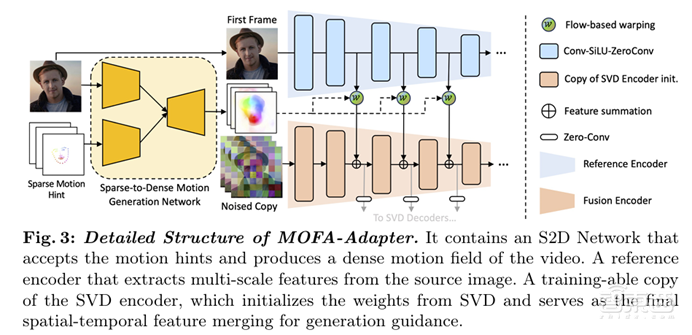
综上所述,MOFA-Video在于其强大的可控性和多模态集成能力,用户只需简单地绘制轨迹,便能精准控制物体或相机的动作;通过音频信号驱动的面部动画,使图像中的人物与语音或音乐同步,带来更具表现力的动画效果。实验结果表明,MOFA-Video能够处理复杂的动画制作任务,生成的长视频不仅保持连续性和逻辑一致性,还在细节上具有很高的表现力,极大地提升了视频内容创作的效率和质量。作者还提供了简易的用户界面,使得无编程经验的用户也能轻松上手,创造出与原始图像高度一致的动态场景。


12月19日19点,智猩猩邀请到论文一作、东京大学在读博士牛慕尧参与「智猩猩AI新青年讲座」259讲,主讲《基于自适应光流运动场的可控图像动画化》。
讲者
牛慕尧
东京大学在读博士生
日本东京大学(UTokyo)计算机学院一年级博士生,师从郑银强教授。于2022年获得大连理工大学工学学士学位;2024年获得日本东京大学硕士学位。研究领域包括AIGC与计算摄影学。在CVPR、ICCV、ECCV以及IEEE TIP等国际会议、期刊上以第一作者身份发表论文6篇。
第259讲
主 题
基于自适应光流运动场的可控图像动画化
提 纲
1、主流视觉扩散模型回顾
2、视频生成可控性分析
3、MOFA-Video研究动机与核心思想
4、MOFA-Adapter设计细节
5、衍生功能解读
直 播 信 息
直播时间:12月19日19:00
成果
论文标题
《MOFA-Video: Controllable Image Animation via Generative Motion Field Adaptions in Frozen Image-to-Video Diffusion Model》
论文链接
https://arxiv.org/pdf/2403.10518
项目网站
https://myniuuu.github.io/MOFA_Video/
报名方式
对本次讲座感兴趣朋友,可以扫描下方二维码,添加小助手米娅进行报名。已添加过米娅的老朋友,可以给米娅私信,发送“ANY259”即可报名。
我们会为审核通过的朋友推送直播链接。同时,本次讲座也组建了学习群,直播开始前会邀请审核通过的相关朋友入群交流。

